
Სარჩევი
სტატიაში მოცემულია რამდენიმე მარტივი მეთოდი, თუ როგორ უნდა იპოვოთ მნიშვნელობის პირველი შემთხვევა სვეტი Excel-ში. ზოგჯერ ჩვენ გვჭირდება დუბლიკატი ელემენტების ან მონაცემების იდენტიფიცირება ჩვენს Excel ფურცელში. მათ მოსაძებნად, ჩვენ უნდა ვიპოვოთ მნიშვნელობის პირველი შემთხვევა სვეტაში . აქ ჩვენ ვიყენებთ მონაცემთა ნაკრებს, რომელიც შეიცავს ID-ებს და ზოგიერთი ბიჭის სახელს <2.

ჩამოტვირთეთ სავარჯიშო სამუშაო წიგნი
Find First Occurrence.xlsx
Excel-ში სვეტში მნიშვნელობის პირველი გაჩენის პოვნის 5 გზა
1. Excel COUNTIF ფუნქციის გამოყენება სვეტში მნიშვნელობის პირველი გაჩენის საპოვნელად
დავუშვათ, რომ გვინდა დავადგინოთ პირველი სახელების შემთხვევების მონაცემთა ნაკრები. თუ რომელიმე სახელი ორჯერ ან მეტჯერ გვხვდება ამ მონაცემთა ნაკრებში, ჩვენ მონიშნავთ მათ როგორც 0s , წინააღმდეგ შემთხვევაში, ის მოინიშნება როგორც 1 . ამის გაკეთება შეგვიძლია COUNTIF ფუნქციის გამოყენებით. ვნახოთ პროცესი ქვემოთ.
ნაბიჯები:
- შექმენით ახალი სვეტი შემთხვევების იდენტიფიცირებისთვის და ჩაწერეთ შემდეგი ფორმულა უჯრედში D5 .
=(COUNTIF($C$5:$C5,$C5)=1)+0 
აქ, COUNTIF ფუნქცია კვლავ ბრუნდება TRUE სანამ არ იპოვის იგივე სახელს სვეტა C -ში. ჩვენ დავამატეთ 0 ( ნული ) რიცხვითი მნიშვნელობის მისაღებად.
- დააჭირეთ ENTER და ნახავთ გამომავალს უჯრედში D5 .

- გამოიყენეთ შევსების სახელური ავტომატური შევსება ქვედა უჯრედები და ეს ოპერაცია მონიშნავს სახელების შემდეგ შემთხვევებს როგორც 0 .

ამგვარად, თქვენ შეგიძლიათ მარტივად ამოიცნოთ მნიშვნელობის პირველი შემთხვევა სვეტი .
დაწვრილებით: როგორ ვიპოვოთ მნიშვნელობის ბოლო შემთხვევა სვეტში Excel-ში (5 მეთოდი)
2. COUNTIFS ფუნქციის გამოყენება სვეტში მნიშვნელობის პირველი გაჩენის საპოვნელად
ჩვენ ასევე შეგვიძლია ვიპოვოთ პირველი შემთხვევა ამით COUNTIFS ფუნქციის გამოყენებით. დავუშვათ, რომ გვინდა დავადგინოთ პირველი შემთხვევები სახელები მონაცემთა ნაკრებში. თუ რომელიმე სახელი ორჯერ ან მეტჯერ გვხვდება ამ მონაცემთა ნაკრებში, ჩვენ მათ მოვნიშნავთ როგორც 0s , წინააღმდეგ შემთხვევაში, ჩვენ მოვნიშნავთ როგორც 1 . მოდით განვიხილოთ პროცესი ქვემოთ.
ნაბიჯები:
- შექმენით ახალი სვეტი შემთხვევების იდენტიფიცირებისთვის და ჩაწერეთ შემდეგი ფორმულა უჯრედში D5 .
=N(COUNTIFS(C$5:C5,C5)=1) 
აქ, COUNTIFS ფუნქცია აგრძელებს დაბრუნებას TRUE სანამ არ იპოვის იგივე სახელს სვეტა C -ში. N ფუნქცია გარდაქმნის TRUE ან FALSE 1 ან 0 შესაბამისად.
- დააჭირეთ ENTER და ნახავთ გამოსავალს უჯრედში D5 .
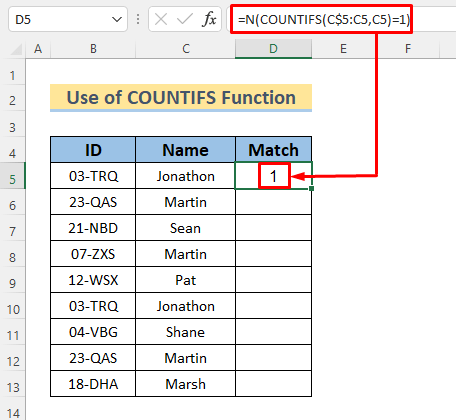
- გამოიყენეთ შეავსეთ სახელური ავტომატური შევსება ქვედა უჯრედებში და ეს ოპერაცია მონიშნავს სახელების შემდეგ შემთხვევებს როგორც 0 .

ამგვარად, თქვენ შეგიძლიათ მარტივად ამოიცნოთ მნიშვნელობის პირველი შემთხვევა სვეტაში .
დაწვრილებით: როგორ ვიპოვოთ მნიშვნელობა სვეტში Excel-ში (4 მეთოდი)
3. იპოვნეთ მნიშვნელობის პირველი შემთხვევა სვეტში Excel-ის ISNUMBER და MATCH ფუნქციების გამოყენებით. იპოვეთ მნიშვნელობის პირველი შემთხვევა სვეტაში . დავუშვათ, რომ გვინდა დავადგინოთ პირველი სახელების შემთხვევები მონაცემთა ნაკრებში. თუ რომელიმე სახელი ორჯერ ან მეტჯერ გვხვდება ამ მონაცემთა ნაკრებში, ჩვენ მოვნიშნავთ მათ როგორც 0s , წინააღმდეგ შემთხვევაში, ჩვენ მოვნიშნავთ როგორც 1 . ვნახოთ პროცედურა ქვემოთ. ნაბიჯები:
- შექმენით ახალი სვეტი შემთხვევების იდენტიფიცირებისთვის და ჩაწერეთ შემდეგი ფორმულა უჯრედში D5 .
=1-ISNUMBER(MATCH(C5,C$4:C4,0)) 
აქ, MATCH ფუნქცია ეძებს მნიშვნელობას C5 , ეძებს დიაპაზონში C4:C4 და აბრუნებს პოზიციას, სადაც პოულობს ზუსტ შესატყვისს. ISNUMBER ფუნქცია აბრუნებს TRUE თუ იპოვის მასში ციფრულ მნიშვნელობას, წინააღმდეგ შემთხვევაში აბრუნებს FALSE მაშინაც კი, თუ მასში არის შეცდომა.
- დააჭირეთ ENTER ღილაკს და ნახავთ გამოსავალს უჯრედში D5 .
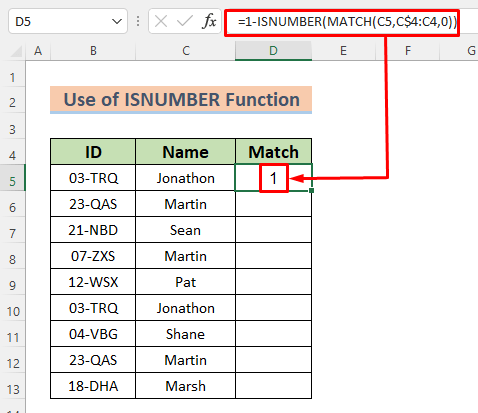
- გამოიყენეთ შევსების სახელური ავტომატური შევსების ქვედა უჯრედებში და ეს ოპერაცია მონიშნავს შემდეგს შემთხვევები სახელებიდან როგორც 0 .

ამგვარად, თქვენ შეგიძლიათ მარტივად ამოიცნოთ პირველი მნიშვნელობის გამოჩენა სვეტში .
წაიკითხეთ მეტი: როგორ მოვძებნოთ საუკეთესო 5 მნიშვნელობა და სახელები Excel-ში (8 სასარგებლო გზა)
4. მნიშვნელობის პირველი გაჩენის პოვნა კომბინირებული ფუნქციების გამოყენებით
ჩვენ ასევე შეგვიძლია ვიპოვოთ პირველი მნიშვნელობის ან მონაცემების გამოჩენა სვეტში <1 კომბინაციით>IF
, INDEX , FREQUENCY , MATCH და ROW ფუნქციები. დავუშვათ, რომ გვინდა დავადგინოთ პირველი ID-ების შემთხვევები მონაცემთა ნაკრებში. თუ რომელიმე ID ორჯერ ან მეტჯერ გვხვდება ამ მონაცემთა ნაკრებში, ჩვენ მათ მოვნიშნავთ როგორც 0s , წინააღმდეგ შემთხვევაში, ჩვენ მოვნიშნავთ როგორც 1 . ფორმულა ცოტა ბინძური იქნება. მოდით გადავიდეთ ქვემოთ მოცემულ აღწერილობაში.
ნაბიჯები:
- შექმენით ახალი სვეტი შემთხვევების იდენტიფიცირებისთვის და ჩაწერეთ შემდეგი ფორმულა უჯრედში D5 .
=IF(INDEX(FREQUENCY(IF($B$5:$B$13&"#"&$C$5:$C$13"",MATCH("~"&$B$5:$B$13&"#"&$C$5:$C$13,$B$5:$B$13&"#"&$C$5:$C$13,0)),ROW($B$5:$B$13)-ROW($B$5)+1),ROWS($B$5:B5))>0,1,0) 
აქ, IF ფუნქცია აბრუნებს 1 ( TRUE ), როდესაც ის აკმაყოფილებს კრიტერიუმებს, წინააღმდეგ შემთხვევაში აბრუნებს 0 ( FALSE ). FREQUENCY ფუნქცია განსაზღვრავს მნიშვნელობების მოცემულ დიაპაზონში მნიშვნელობის გაჩენის რაოდენობას .
ფორმულის დაშლა
- ROWS($B$5:B5) —-> აბრუნებს
- გამომავალი : 1
- ROW($B$5:$B$13) —-> იქცევა
- გამომავალი:{5;6;7;8;9;10;11;12;13}
- ROW($B$5) —-> იქცევა
- გამოსავალად: {5}
- MATCH(“~”&$B$5:$B$13& ”#”&$C$5:$C$13,$B$5:$B$13&”#”&$C$5:$C$13,0) —-> იქცევა
- გამომავალი : {1;2;3;4;5;1;7;2;9}
- თუ ($B$5:$B$13&"#"&$C$5:$C$13"",MATCH("~"&$B$5:$B$13&"#"&$C$5: $C$13,$B$5:$B$13&”#”&$C$5:$C$13,0)) —-> იქცევა
- IF($ B$5:$B$13&"#"&$C$5:$C$13"",{1;2;3;4;5;1;7;2;9}) —-> ტოვებს
- გამომავალი : {1;2;3;4;5;1;7;2;9}
- სიხშირე(IF($B$5:$B$13&"#"&$C$5:$C$13"",MATCH("~"&$B$5:$B$13&" #"&$C$5:$C$13,$B$5:$B$13&"#"&$C$5:$C$13,0)), ROW($B$5:$B$13)-ROW ($B$5)+1) —-> იქცევა
- სიხშირე(IF{1;2;3;4;5;1;7;2;9}),{ 5;6;7;8;9;10;11;12;13}-{5}+1) —-> იქცევა
- გამოსავალად : {2;2;1;1;1;0;1;0;1;0}
- ინდექსი(სიხშირე( IF($B$5:$B$13&"#"&$C$5:$C$13"",MA TCH("~"&$B$5:$B$13&"#"&$C$5:$C$13,$B$5:$B$13&"#"&$C$5:$C$13 ,0)),ROW($B$5:$B$13)-ROW($B$5)+1) —-> აბრუნებს
- INDEX({2;2;1 ;1;1;0;1;0;1;0})
- გამომავალი:{2}
- IF(INDEX(სიხშირე(IF($B$5:$B$13&"#"&$C$5:$C$13 "",MATCH("~"&$B$5:$B$13&"#"&$C$5:$C$13,$B$5:$B$13&"#"&$C$5: $C$13,0)), ROW($B$5:$B$13)-ROW($B$5)+1),ROWS($B$5:B5))>0,1,0) —-> ამარტივებს
- IF({2}>0,1,0)
- გამომავალი: 1
ბოლოს, ჩვენ ვიღებთ გამოსავალს, როგორც 1 რადგან ID უჯრედში B5 პირველად ჩნდება .
- დააწკაპუნეთ ENTER და ნახავთ გამოსავალს უჯრედში D5 .

- გამოიყენეთ შევსების სახელური ავტომატური შევსების ქვედა უჯრედებში და ეს ოპერაცია მონიშნავს სახელების შემდეგ შემთხვევებს როგორც 0 .

ამგვარად, თქვენ შეგიძლიათ მარტივად ამოიცნოთ მნიშვნელობის პირველი შემთხვევა სვეტაში .
დაწვრილებით: როგორ ვიპოვოთ მნიშვნელობა სვეტში VBA-ის გამოყენებით Excel-ში (4 გზა)
5. ფილტრის ბრძანების გამოყენებით სვეტში მნიშვნელობების პირველი შემთხვევების დასალაგებლად
დავუშვათ, რომ გსურთ ნახოთ სახელების გამეორების დრო სვეტა D -ში და აქედან გამომდინარე თქვენ გსურთ ნახოთ ამ სახელების პირველი შემთხვევების პოზიცია. ამის გაკეთება შეგვიძლია ფილტრის ბრძანების გამოყენებით. გთხოვთ, გადახედოთ ქვემოთ მოცემულ აღწერილობას.
ნაბიჯები:
- შექმენით ახალი სვეტი შემთხვევების იდენტიფიცირებისთვის და ჩაწერეთ შემდეგი ფორმულა უჯრედში D5 .
=COUNTIF($C$5:C5,C5) 
აქ, COUNTIF ფუნქცია აბრუნებს რამდენჯერაც სახელი მოხდება სვეტა C .
- ახლა, დააჭირეთ ENTER და თქვენ იხილავს გამოსავალს უჯრედში D5 .

- გამოიყენეთ შევსების სახელური ავტომატური შევსებისთვის ქვედა უჯრედები და ეს ოპერაცია მონიშნავს სახელების შემდეგ შემთხვევებს როგორც 0 .

ამგვარად, შეგიძლიათ ნახოთ რამდენჯერ გაჩნდება სახელი სვეტა D -ში.
- გაფილტვრა პირველი შემთხვევები , აირჩიეთ დიაპაზონი B4:D13 და გადადით მთავარი >> დახარისხება & ფილტრი >> ფილტრი

- დააწკაპუნეთ მონიშნულ ისარზე 1>მატჩის სათაური . მონიშნეთ 1 და შემდეგ დააწკაპუნეთ OK .

- ამის შემდეგ ნახავთ ყველა დუბლიკატს IDs ამოღებულია ფილტრით . გამოჩნდება მხოლოდ პირველი ID-ების შემთხვევები.

ამგვარად შეგიძლიათ იპოვოთ მხოლოდ პირველი შემთხვევის და გაფილტვრა ისინი სვეტში.
წაიკითხეთ მეტი: როგორ მივიღოთ უჯრედის მნიშვნელობა მწკრივისა და სვეტის მიხედვით Excel VBA
სავარჯიშო განყოფილება
შემდეგ ფიგურაში მე წარმოგიდგენთ მონაცემთა ბაზას, რომელიც ჩვენ გამოვიყენეთ ამ სტატიაში, რათა შეძლოთ ამ მაგალითების დამოუკიდებლად პრაქტიკა.
დასკვნა. სვეტი Excel-ში. ამ მიზნით ჩვენ გამოვიყენეთ საკმაოდ ძირითადი ფუნქციები. თუ თქვენ გაქვთ რაიმე უკეთესი მეთოდი ან იდეა ან გამოხმაურება, გთხოვთ დატოვოთ ისინი კომენტარების ველში. ეს დამეხმარება ჩემი მომავალი სტატიების გამდიდრებაში.
