
Оглавление
Если вы ищете способы вычисления P-value или значение вероятности в линейной регрессии в Excel, тогда вы находитесь в правильном месте. P-value используется для определения вероятности результатов гипотетических испытаний. Мы можем анализировать результаты на основе 2 гипотез;. Нулевая гипотеза и Альтернативная гипотеза . Использование P-value мы можем определить, подтверждает ли результат нулевую гипотезу или альтернативную гипотезу.
Итак, приступим к основной статье.
Скачать рабочую тетрадь
P value.xlsx3 способа вычисления значения P в линейной регрессии в Excel
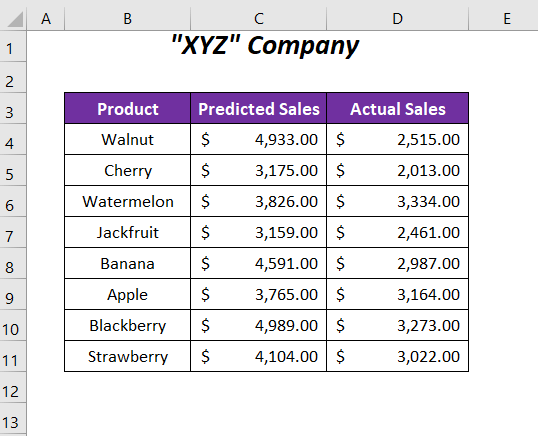
Здесь у нас есть прогнозируемые значения продаж и фактические значения продаж некоторых продуктов компании. Мы сравним эти значения продаж и определим значение вероятности, а затем мы определим, если P нулевая гипотеза предполагает отсутствие различий между двумя типами значений продаж, а альтернативная гипотеза будет рассматривать различия между этими двумя наборами значений.
Мы использовали Microsoft Office 365 версию здесь, вы можете использовать любые другие версии в зависимости от вашего удобства.
Метод-1: Использование 't-Test Analysis Tool' для расчета значения P
Здесь мы будем использовать пакет инструментов анализа, содержащий инструмент анализа t-Test для определения P-value для этих двух наборов данных о продажах.

Шаги :
Если вы не активировали инструмент анализа данных, то сначала включите этот пакет.
➤ Нажмите на Файл вкладка.

➤ Выберите Опции .

После этого Параметры Excel появится диалоговое окно.
➤ Выберите Дополнения на левой панели.
➤ Выберите Excel Дополнения опция в Управляйте поле и затем нажмите Перейти .
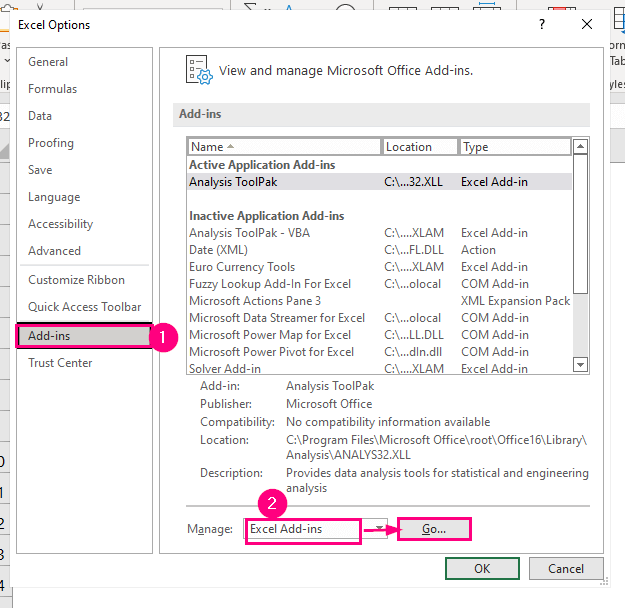
После этого Дополнения появится диалоговое окно.
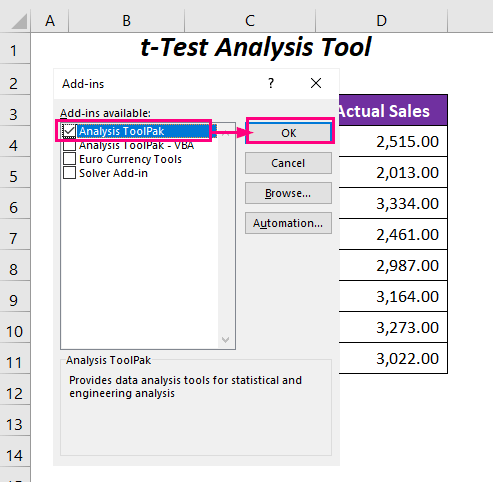
➤ Проверьте Пакет инструментов анализа и нажмите кнопку OK .
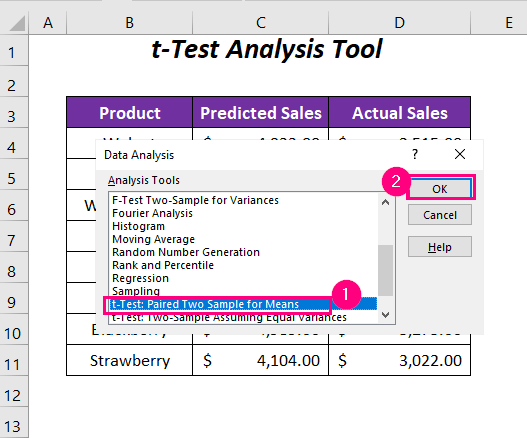
➤ Теперь перейдите в Данные Вкладка>> Анализ Группа>> Анализ данных Вариант.

Затем Анализ данных появится мастер.
➤ Выберите опцию t-тест: парная двухвыборочная выборка для средних значений из различных вариантов Инструменты анализа .
После этого t-тест: парная двухвыборочная выборка для средних значений откроется диалоговое окно.
➤ As Вход мы должны предоставить два диапазона переменных; $C$4:$C$11 для Переменная 1 Диапазон и $D$4:$D$11 для Переменная 2 Диапазон , как Выходной диапазон мы выбрали $E$4 .
➤ Вы можете изменить значение для Альфа с сайта 0.05 (автоматически генерируется) в 0.01 поскольку назначенное значение для этой константы обычно 0.05 или 0.01 .
➤ Наконец, нажмите OK .

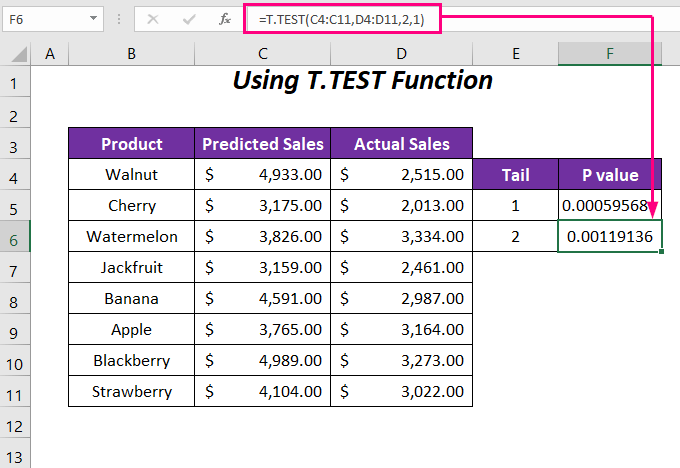
После этого вы получите P-value для двух случаев; однохвостовое значение составляет 0.00059568 и двуххвостовое значение 0.0011913 Мы видим, что однохвостая P-value в два раза меньше двуххвостого P-value . Поскольку двуххвостка P-value учитывает как увеличение, так и уменьшение оценок, в то время как однохвостовая P-value рассматривает только один из этих случаев.
Более того, мы видим, что для значения альфа 0.05 мы получаем P значения меньше 0.05 что означает, что он пренебрегает нулевой гипотезой, и поэтому данные являются высокозначимыми.

Читать далее: Как интерпретировать результаты линейной регрессии в Excel (с простыми шагами)
Метод-2: Использование функции T.TEST для вычисления значения P в линейной регрессии в Excel
В этом разделе мы будем использовать Функция T.TEST для определения Значения P для хвостов 1 и 2 .
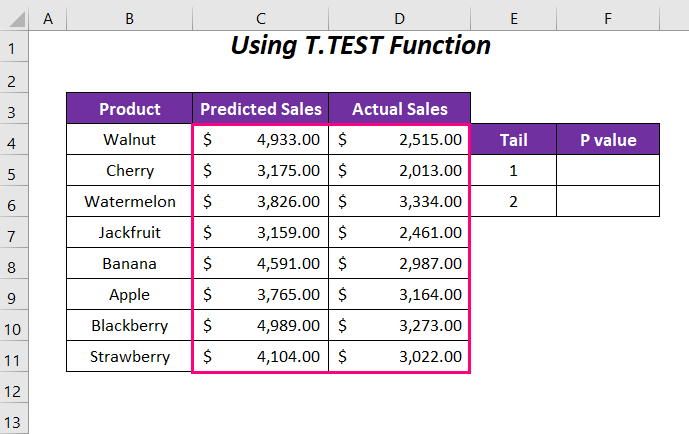
Шаги :
Мы начнем с определения P-value для хвоста 1 или в одном направлении.
➤ Введите следующую формулу в ячейку F5 .
=T.TEST(C4:C11,D4:D11,1,1)Вот, C4:C11 диапазон Прогнозируемые продажи , D4:D11 диапазон Фактические продажи , 1 является хвостовым значением, а последнее 1 для Парный тип.
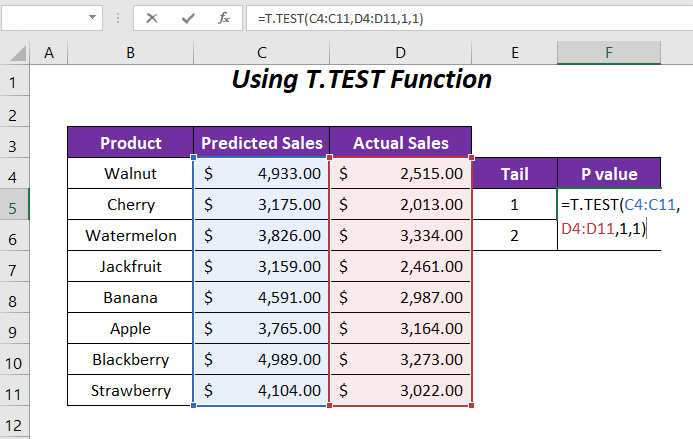
После нажатия ENTER , мы получаем P-value 0.00059568 для хвоста 1 .

➤ Примените следующую формулу в ячейке F6 для определения P-value для хвоста 2 или в обоих направлениях.
=T.TEST(C4:C11,D4:D11,2,1) Вот, C4:C11 диапазон Прогнозируемые продажи , D4:D11 диапазон Фактические продажи , 2 является хвостовым значением, а последнее 1 для Парный тип.
Читать далее: Множественная линейная регрессия на наборах данных Excel (2 метода)
Метод-3: Использование функций CORREL, T.DIST.2T для вычисления значения P в линейной регрессии
Мы определим P-value для корреляции здесь с помощью КОРРЕЛ , T.DIST.2T функции.
Для этого мы создали несколько столбцов с заголовками Итого Пункт , Корреляция. Фактор , t Значение и P-значение и мы ввели значение для общего количества товаров, которое также равно 8 .

Шаги :
➤ Во-первых, мы определяем Коррел.фактор введя следующую формулу в ячейку C14 .
=CORREL(C4:C11,D4:D11) Вот, C4:C11 диапазон Прогнозируемые продажи и D4:D11 диапазон Фактические продажи .

➤ Для определения значение t введите следующую формулу в ячейку D14 .
=(C14*SQRT(B14-2))/SQRT(1-C14*C14) Вот, C14 коэффициент корреляции, и B14 общее количество продуктов.
- SQRT(B14-2) становится
SQRT(8-2) → SQRT(6) дает квадратный корень из 6 .
Выход → 2.4494897
- C14*SQRT(B14-2) становится
0.452421561*2.4494897
Выход → 1.10820197
- 1-C14*C14 становится
1-0.452421561*0.452421561
Выход → 0.79531473
- SQRT(1-C14*C14) становится
SQRT(0.79531473) → возвращает квадратный корень из 0.79531473 .
Выход → 0.891804199
- (C14*SQRT(B14-2))/SQRT(1-C14*C14) становится
(1.10820197)/0.891804199
Выход → 1.242651665
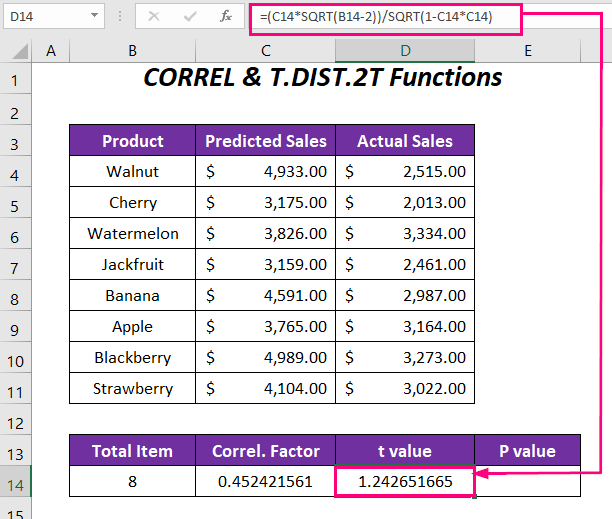
➤ Наконец, с помощью следующей функции мы определим P-value для корреляции.
=T.DIST.2T(D14,B14-2) Вот, D14 это значение t , B14-2 или 8-2 или 6 степень свободы и T.DIST.2T вернет P-value для корреляции с двуххвостовым распределением.

Читать далее: Как провести множественный регрессионный анализ в Excel (с простыми шагами)
О чем следует помнить
⦿ Как правило, мы используем два распространенных варианта Альфа значения; 0.05 и 0.01 .
⦿ Есть две гипотезы, нулевая гипотеза и альтернативная гипотеза, нулевая гипотеза учитывает отсутствие разницы между двумя наборами данных, а другая учитывает разницу между двумя наборами данных.
⦿ Когда P-value меньше, чем 0.05 отрицает нулевую гипотезу, а для значений, превышающих 0.05 он подтверждает нулевую гипотезу. Оценивая P-value мы можем прийти к следующим выводам.
P<0.05 → высокозначимые данныеP=0.05 → важные данные
P=0.05-0.1 → незначительно значимые данные
P>0.1 → незначительные данные
Практическая секция
Для самостоятельного выполнения практики мы предоставили Практика раздел, как показано ниже, в листе с именем Практика Пожалуйста, сделайте это сами.
Заключение
В этой статье мы постарались рассказать о способах расчета P-value в линейной регрессии в Excel. Если у вас есть какие-либо предложения или вопросы, не стесняйтесь поделиться ими в разделе комментариев.
