
Obsah
Filtrování jedinečných údajů je účinný způsob, jak se vypořádat s četnými položkami v datové sadě. Excel nabízí několik funkcí pro filtrování jedinečných údajů nebo odstranění duplicit, ať už je nazýváme jakkoli. V tomto článku si ukážeme způsoby filtrování jedinečných údajů z ukázkové datové sady.
Řekněme, že máme tři jednoduché sloupce v datovém souboru aplikace Excel, které obsahují Datum objednávky , Kategorie a Produkt . Chceme jedinečné objednané produkty v rámci celého souboru dat.
Stáhnout sešit aplikace Excel
Filtrování jedinečných hodnot.xlsm8 snadných způsobů filtrování jedinečných hodnot v aplikaci Excel
Metoda 1: Použití funkce Excelu Odstranit duplikáty k filtrování jedinečných hodnot
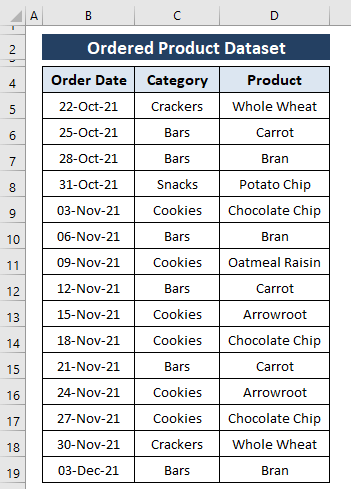
Abychom se v rozsáhlém souboru dat vyznali, potřebujeme někdy odstranit duplicity. Excel nabízí funkci Odstranění duplicit funkce v Data vynechat duplicitní položky z datových sad. V tomto případě chceme odstranit duplicity z datových sad. Kategorie a Produkt Výsledkem je, že můžeme použít sloupec Odstranění duplicit funkci, která to umožňuje.
Krok 1: Vyberte rozsah (tj, Kategorie a Produkt ) a pak přejděte na Data Karta> Vybrat Odstranění duplicit (z Datové nástroje sekce).
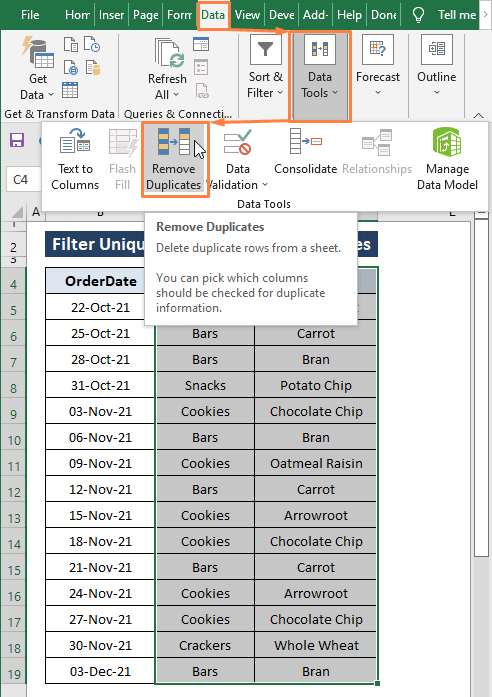
Krok 2: Na stránkách Odstranění duplicit Zobrazí se okno Odstranění duplicit okno,
Zkontroloval jsem všechny sloupce.
Zaškrtněte možnost Moje data mají záhlaví .
Klikněte na OK .
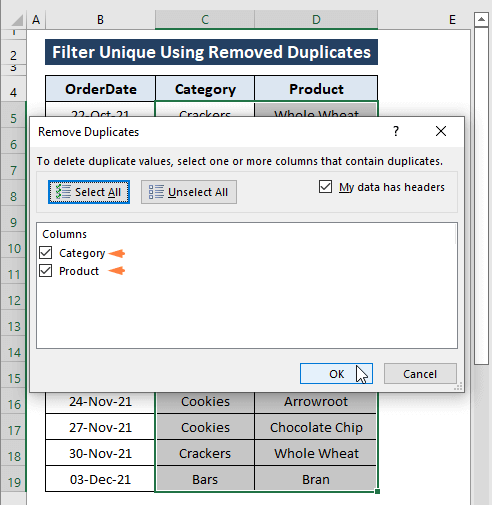
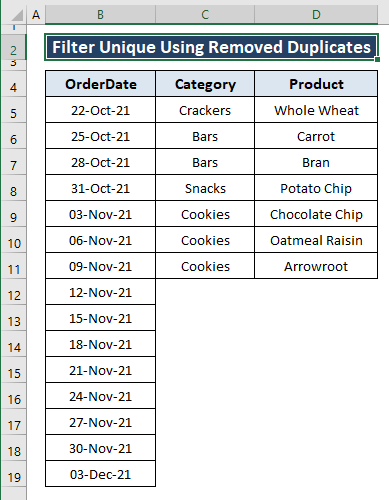
Krok 3: Zobrazí se dialogové okno s potvrzením 8 nalezené a odstraněné duplicitní hodnoty; Zbývá 7 jedinečných hodnot .
Klikněte na OK .
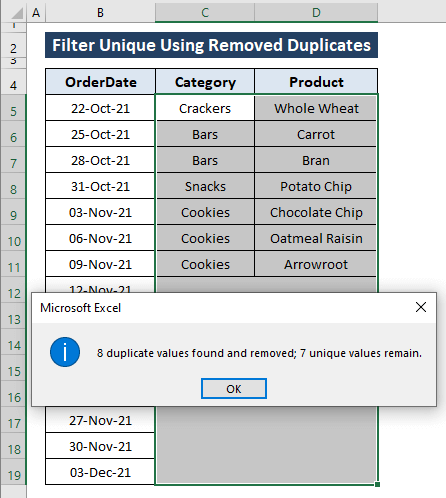
Všechny kroky vedou k následujícím důsledkům, jak je znázorněno na následujícím obrázku.
Metoda 2: Použití podmíněného formátování k filtrování jedinečných hodnot
Dalším způsobem, jak filtrovat jedinečné, je Podmíněné formátování . Excel Podmíněné formátování může formátovat buňky podle mnoha kritérií. V tomto případě však použijeme vzorec pro podmíněné formátování buněk v rozsahu (tj, Produkt sloupec). Máme dvě možnosti použití Podmíněné formátování ; jedním je podmíněné formátování pro filtrování jedinečných hodnot a druhým je skrytí duplicitních hodnot z rozsahu.
2.1. Podmíněné formátování pro filtrování jedinečných hodnot
V tomto případě použijeme vzorec v Podmíněné formátování možnosti filtrování jedinečných záznamů v aplikaci Excel.
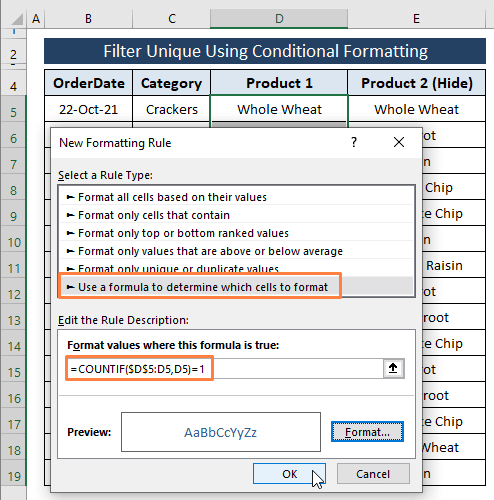
Krok 1: Vyberte rozsah (tj, Výrobek 1 ) a pak přejděte na Home Karta> Vybrat Podmíněné formátování (od Styly section)> Select Nové pravidlo .
Krok 2: Na stránkách Nové pravidlo formátování se objeví okno. Nové pravidlo formátování Okno,
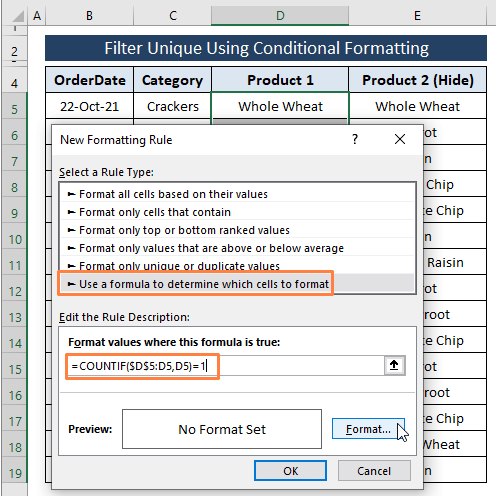
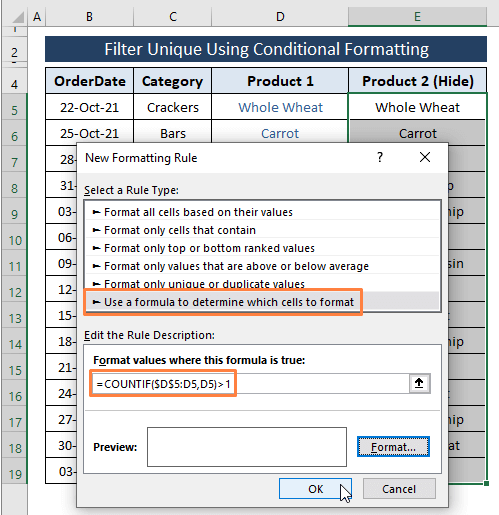
Vyberte Pomocí vzorce určete, které buňky se mají formátovat pod Vyberte typ pravidla možnost.
Do pole zadejte následující vzorec Úprava popisu pravidla možnost.
=COUNTIF($D$5:D5,D5)=1 Ve vzorci jsme aplikaci Excel nařídili, aby počítala každou buňku v seznamu. D sloupec jako Unikátní (tj. rovná se 1 ). Pokud záznamy odpovídají zadané podmínce, vrátí se hodnota TRUE a Formát barev buňky.
Klikněte na Formát .
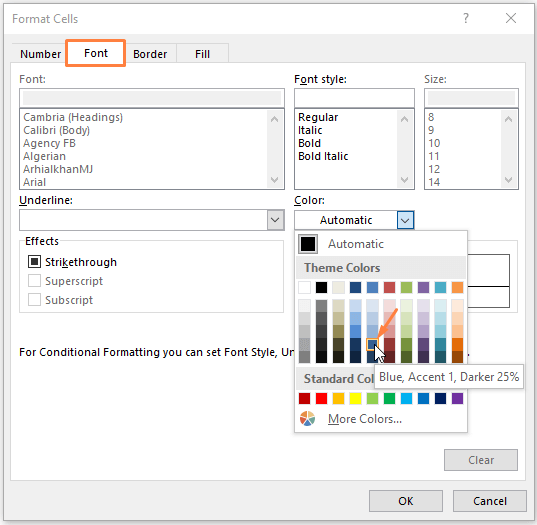
Krok 3: Za okamžik se Formátování buněk Zobrazí se okno Formátování buněk okno,
V Písmo část - vyberte libovolnou barvu formátování, jak je znázorněno na obrázku níže.
Pak klikněte na OK .
Krok 4: Kliknutí na OK v předchozím kroku přejdete na Nové pravidlo formátování znovu okno. V okně Nové pravidlo formátování můžete zobrazit náhled jedinečných záznamů.
Klikněte na OK .
Nakonec získáte jedinečné položky barevně naformátované podle vašich představ podobně jako na obrázku níže.
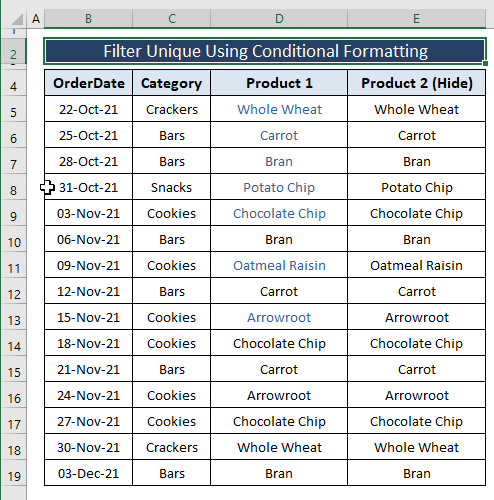
2.2. Podmíněné formátování pro skrytí duplikátů
Aniž bychom museli zasahovat do jedinečných hodnot, můžeme duplicitní hodnoty jednoduše skrýt pomocí příkazu Podmíněné formátování Abychom skryli duplikáty, musíme použít stejný vzorec jako pro odfiltrování unikátů s tím rozdílem, že jim přiřadíme hodnoty větší než 1 . Po výběru White Font barvu, můžeme je skrýt před ostatními položkami.
Krok 1: Opakování Kroky 1 na 2 z metoda 2.1 ale změňte vložený vzorec na níže uvedený.
=COUNTIF($D$5:D5,D5)>1 Vzorec nařizuje aplikaci Excel, aby počítala každou buňku v seznamu D sloupec jako Duplikáty (tj. větší než 1 ). Pokud záznamy odpovídají zadané podmínce, vrátí se hodnota TRUE a Formát barev (tj, Skrýt ) buňky.
Klikněte na Formát .
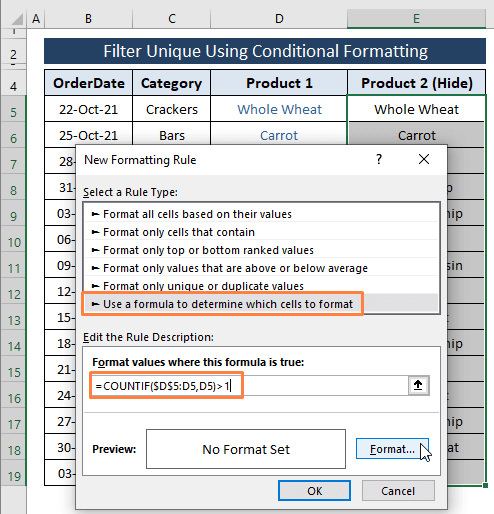
Krok 2: Kliknutím na tlačítko Formát přejdete do Formátování buněk V okně Formátování buněk okno,
Vyberte Písmo barva Bílá .
Pak klikněte na OK .
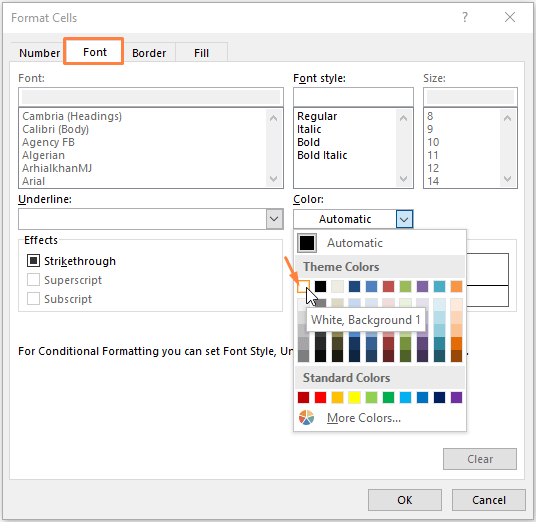
Krok 3: Po výběru Písmo barva, Kliknutí OK vás vznáší k Nové pravidlo formátování Znovu můžete vidět náhled jako bezútěšný, protože jsme vybrali Bílá jako Písmo barva.
Klikněte na OK .
Po provedení všech kroků se zobrazí podobný obrázek jako níže pro duplicitní hodnoty.
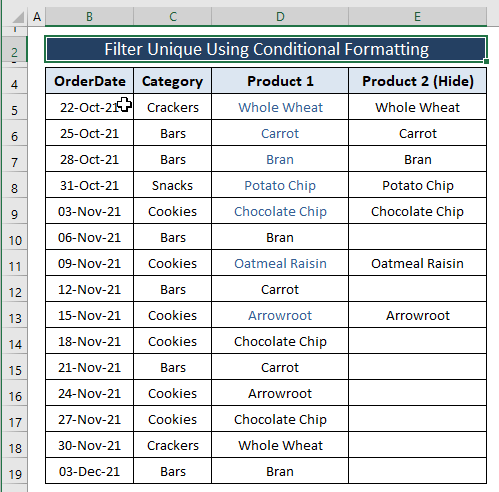
Musíte vybrat Bílá jako Písmo barvu, jinak se duplicitní položky neskryjí.
Přečtěte si více: Jak filtrovat data v aplikaci Excel pomocí vzorce
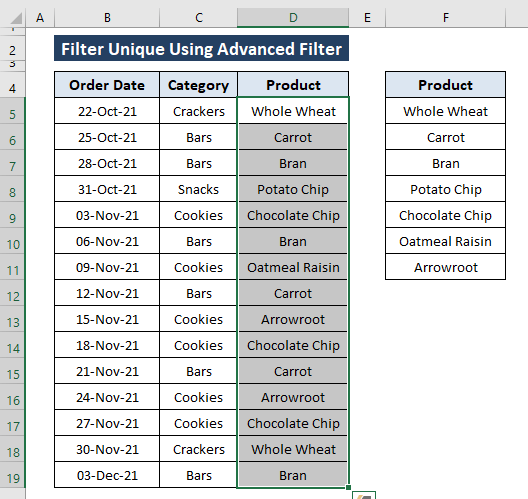
Metoda 3: Použití funkce pokročilého filtru na kartě Data k filtrování jedinečných hodnot
Dřívější metody odstraňují nebo odebírají položky z datové sady, aby se filtrovaly jedinečné. Je to poměrně nebezpečné, když pracujeme s určitými datovými sadami. Mohou nastat situace, kdy nemůžeme měnit surové datové sady, v takových případech můžeme použít příkaz Rozšířený filtr možnost filtrovat jedinečné v požadované pozici.
Krok 1: Vyberte rozsah (tj, Produkt sloupec). Pak přejděte na Data Karta> Vybrat Pokročilé (od Třídit a filtrovat sekce).
Krok 2: Na stránkách Rozšířený filtr Zobrazí se okno Rozšířený filtr okno,
Vyberte Kopírování do jiného umístění akce v rámci Akce možnost. Můžete zvolit buď Filtrování seznamu na místě, nebo Kopírování do jiného umístění my však volíme druhou z nich, protože nemění surová data.
Přiřaďte umístění (tj, F4 ) v Kopírovat do možnost.
Zkontroloval jsem Pouze jedinečné záznamy možnost.
Klikněte na OK .
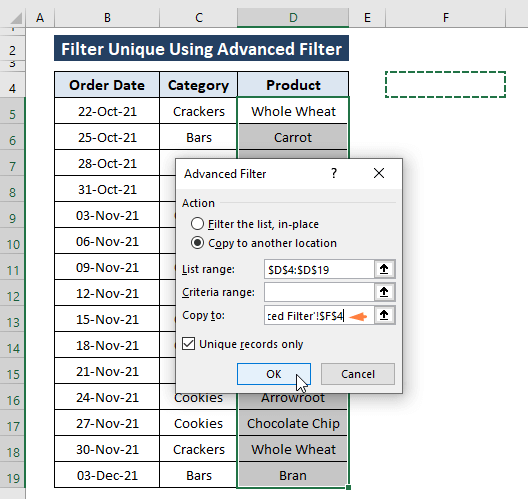
Kliknutí na OK získáte jedinečné hodnoty v určeném umístění podle pokynů v jednotlivých krocích.
Metoda 4: Filtrování jedinečných hodnot pomocí funkce UNIQUE aplikace Excel
Zobrazení jedinečných hodnot v jiném sloupci lze dosáhnout také pomocí příkazu UNIKÁTNÍ funkce. UNIKÁTNÍ funkce načte seznam jedinečných položek z rozsahu nebo pole. Syntaxe funkce UNIKÁTNÍ je funkce
UNIQUE (pole, [by_col], [exactly_once])
Argumenty,
pole ; rozsah nebo pole, ze kterého se získávají jedinečné hodnoty.
[by_col] ; způsoby porovnávání a získávání hodnot, a to row = FALSE ( výchozí ) a column = TRUE . [nepovinné]
[exactly_once] ; jednou se vyskytující hodnoty = TRUE a stávající jedinečné hodnoty = FALSE (podle výchozí ). [nepovinné]
Krok 1: Do libovolné prázdné buňky zadejte následující vzorec (tj., E5 ).
=UNIKÁTNÍ(D5:D19) 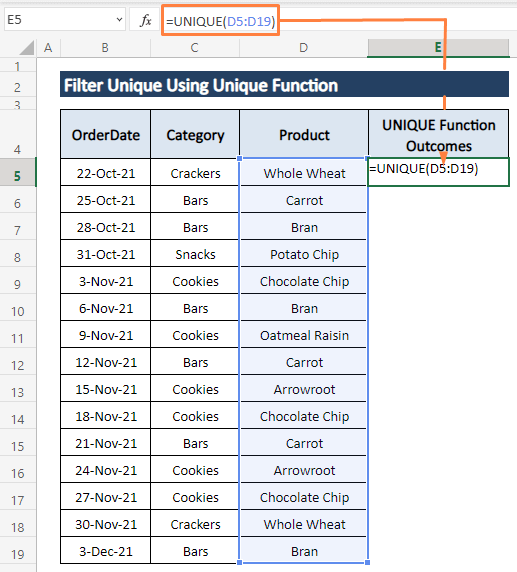
Krok 2: Tisk ENTER pak se během sekundy objeví všechny jedinečné položky ve sloupci podobném obrázku níže.
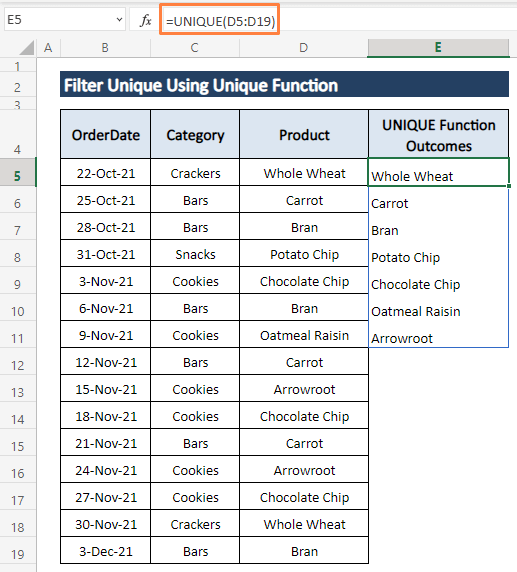
Na stránkách UNIKÁTNÍ funkce vysype všechny jedinečné položky najednou. UNIKÁTNÍ jiná funkce než Excel 365 verze.
Podobná čtení
- Filtrování dat v aplikaci Excel na základě hodnoty buňky (6 efektivních způsobů)
- Jak přidat filtr v aplikaci Excel (4 metody)
- Zkratka pro filtr Excelu (3 rychlá použití s příklady)
- Jak používat textový filtr v aplikaci Excel (5 příkladů)
Metoda 5: Použití funkcí UNIQUE a FILTER (s kritérii)
V metodě 4 používáme UNIKÁTNÍ Co když chceme jedinečné položky v závislosti na podmínce? Řekněme, že chceme jedinečné hodnoty. Produkt jména určitého Kategorie z našeho souboru dat.
V tomto případě chceme jedinečný Produkt jména Bary (tj, E4 ) z našeho souboru dat.
Krok 1: Níže uvedený vzorec zapište do libovolné buňky (tj., E5 ).
=UNIKÁTNÍ(FILTR(D5:D19,C5:C19=E4)) Vzorec dává pokyn k filtrování D5:D19 rozsah, uložení podmínky pro rozsah C5:C19 rovnat buňce E4 .
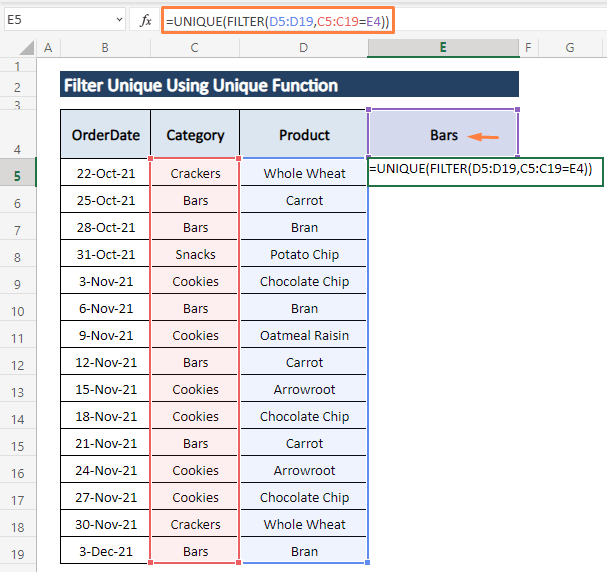
Krok 2: Hit ENTER . Poté, co produkty v rámci Bary se objevují v buňkách Bary sloupec, jak je znázorněno na následujícím snímku obrazovky.
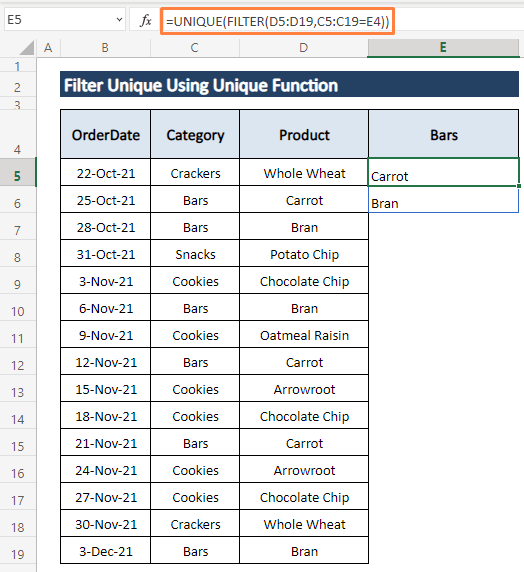
Můžete si vybrat libovolný Kategorie je to docela efektivní způsob, jak zpracovat obrovské soubory dat o prodeji. FILTR je k dispozici pouze v Excel 365.
Přečtěte si více: Filtrování více kritérií v aplikaci Excel
Metoda 6: Použití funkcí MATCH a INDEX (vzorec pole)
Pro jednodušší demonstraci použijeme datový soubor bez prázdných míst a položek rozlišujících velká a malá písmena. Jak tedy můžeme pracovat s takovým datovým souborem, který obsahuje prázdná místa a položky rozlišující velká a malá písmena? Než si ukážeme východisko, odfiltrujme rozsah bez prázdných míst (tj, Výrobek 1 ) pomocí kombinovaného vzorce. V tomto případě použijeme vzorec MATCH a INDEX funkce pro filtrování jedinečných.
6.1. Funkce MATCH a INDEX filtrují jedinečné hodnoty z neprázdného rozsahu
Vidíme, že v rozsahu Produkt 1 nejsou žádné prázdné buňky.
Krok 1: Do buňky zadejte následující vzorec G5 odfiltrovat jedinečné.
=IFERROR(INDEX($D$5:$D$19, MATCH(0, COUNTIF($G$4:G4, $D$5:$D$19), 0)),"") Podle vzorce,
Za prvé, COUNTIF($G$4:G4, $D$5:$D$19) ; počítá počet buněk v rozsahu (tj, $G$4:G4 ) splňující podmínku (tj, $D$5:$D$19) . COUNTIF vrací 1 pokud najde $G$4:G4 v rozsahu jinak 0 .
Druhý, MATCH(0, COUNTIF($G$4:G4, $D$5:$D$19), 0)) ; vrací relativní poloha výrobku v rozsahu.
Konečně, INDEX($D$5:$D$19, MATCH(0, COUNTIF($G$4:G4, $D$5:$D$19), 0)); vrátí položky buněk, které splňují podmínku.
Na stránkách IFERROR funkce omezuje zobrazování chyb ve výsledcích vzorce.
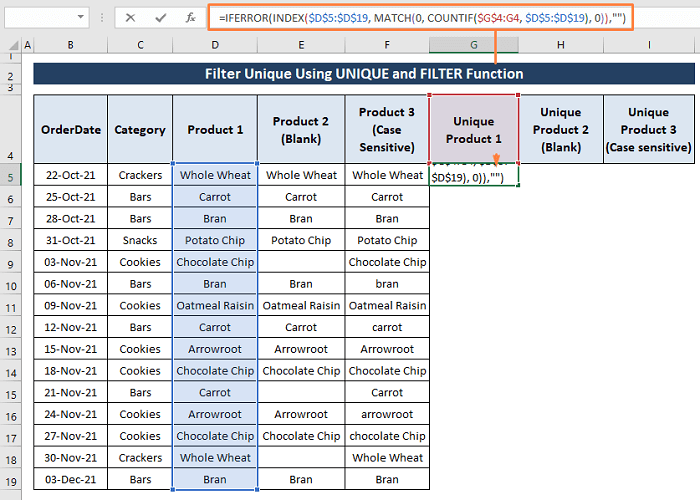
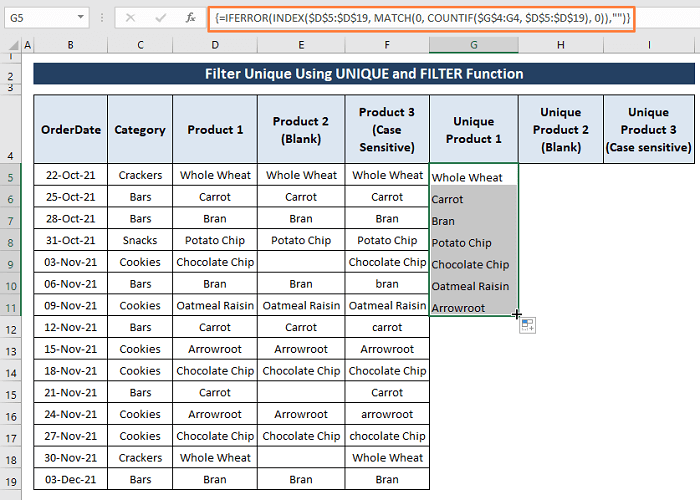
Krok 2: Protože vzorec je vzorec pole, stiskněte tlačítko CTRL+SHIFT+ENTER celkem. Všechny jedinečné záznamy z databáze Výrobek 1 se objeví rozsah.
6.2. Funkce MATCH a INDEX pro filtrování jedinečných hodnot z existujících prázdných buněk v rozsahu
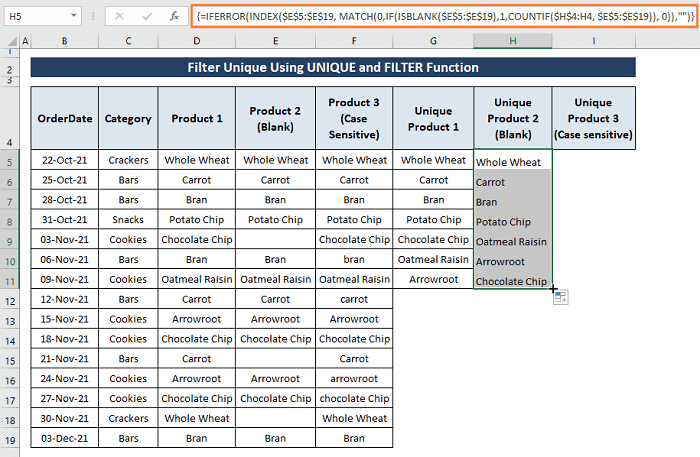
Nyní v Výrobek 2 vidíme, že existuje více prázdných buněk. Abychom odfiltrovali jedinečné z prázdných buněk, musíme vložit příkaz ISBLANK funkce.
Krok 1: Vložte níže uvedený vzorec do buňky H5 .
=IFERROR(INDEX($E$5:$E$19, MATCH(0,IF(ISBLANK($E$5:$E$19),1,COUNTIF($H$4:H4, $E$5:$E$19)), 0)),"") Tento vzorec funguje stejným způsobem, jak jsme ho popsali v části 6.1. oddíl . Nicméně, extra IF funkce s logickým testem ISBLANK funkce umožňuje, aby vzorec ignoroval prázdné buňky v rozsahu.
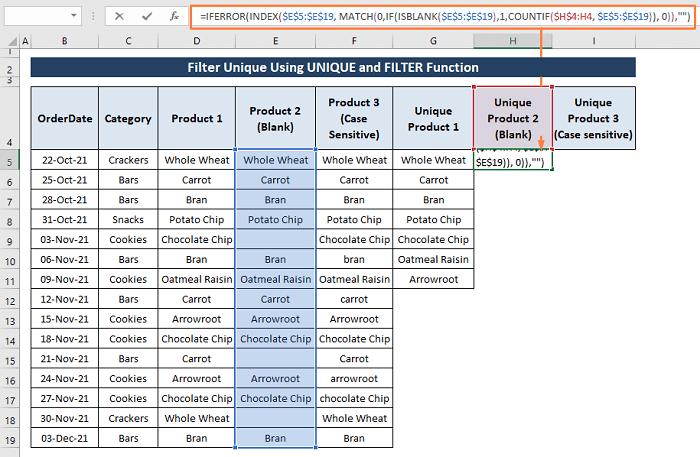
Krok 2: Hit CTRL+SHIFT+ENTER a vzorec ignoruje prázdné buňky a načte všechny jedinečné položky, jak je znázorněno na následujícím obrázku.
6.3. Funkce MATCH a INDEX pro filtrování jedinečných hodnot z rozsahu rozlišujícího velká a malá písmena
Pokud náš soubor dat obsahuje položky rozlišující malá a velká písmena, musíme použít příkaz FREKVENCE spolu s funkcí TRANSPOSE a ROW funkce pro odfiltrování jedinečných.
Krok 1: Použijte následující vzorec v buňce I5 .
=INDEX($F$5:$F$19, MATCH(0, FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19))), 0))) Oddíly vzorce,
- TRANSPOSE($I$4:I4); transponovat předchozí hodnoty převodem středníku na čárku. ( Tj. z TRANSPOSE({"unikátní hodnoty (rozlišuje velká a malá písmena)";Celá pšenice"}) se stane {"unikátní hodnoty (rozlišuje velká a malá písmena)", "Celá pšenice"}
- EXACT($F$5:$F$19, TRANSPOSE($I$4:I4); kontroluje, zda jsou řetězce stejné a zda rozlišují velká a malá písmena.
- IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)); vrátí relativní pozici řetězce v poli, pokud TRUE .
- FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), "") ; vypočítá, kolikrát se řetězec v poli vyskytuje.
- MATCH(0, FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19))), 0))) ; najde první False (tj, Prázdné stránky ) v poli.
- INDEX($F$5:$F$19, MATCH(0, FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19))), 0))) ; vrací jedinečné hodnoty z pole.
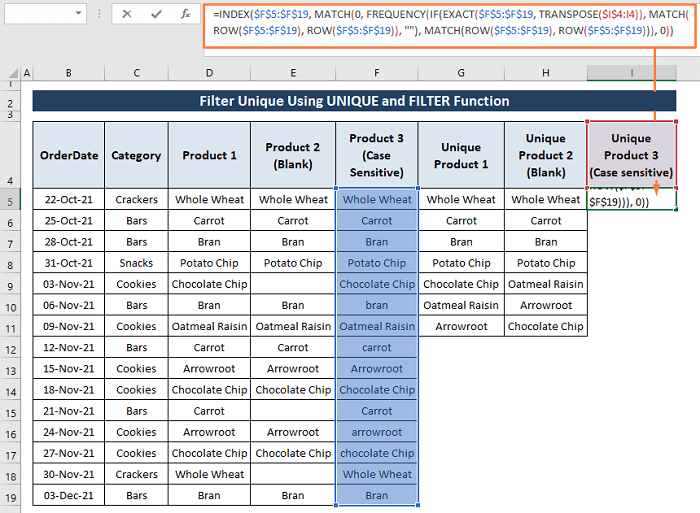
Krok 2: Musíte stisknout CTRL+SHIFT+ENTER dohromady a v buňkách se objeví jedinečné hodnoty rozlišující malá a velká písmena.
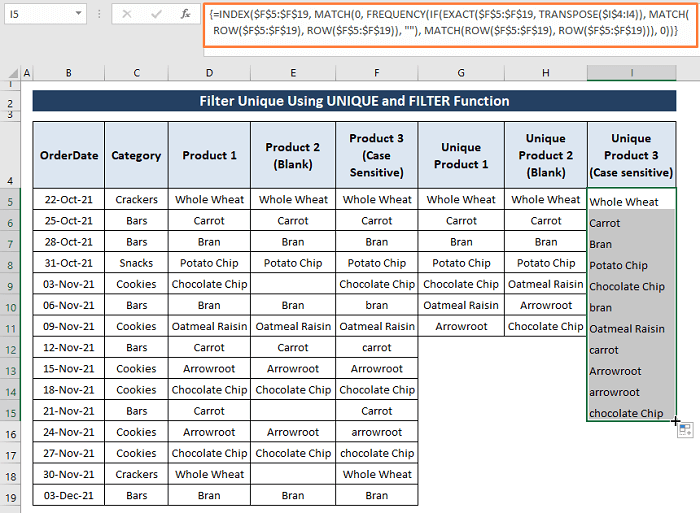
Po seřazení všech typů záznamů do příslušných sloupců vypadá celý soubor dat jako na následujícím obrázku.
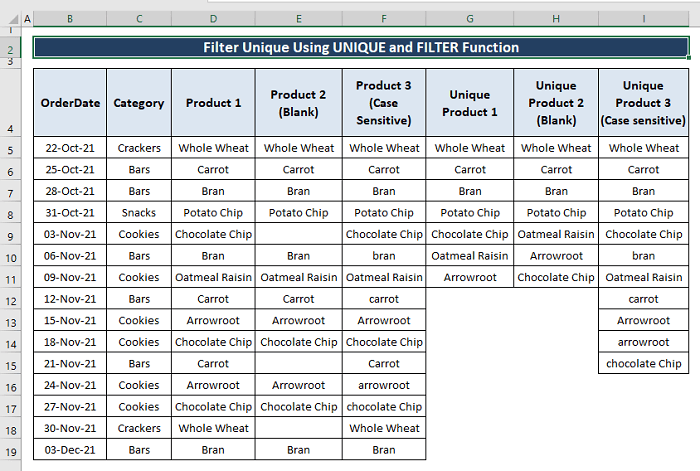
Můžete změnit kterýkoli z Produkt datových typů, abyste splnili svůj požadavek, a podle toho použijte vzorce.
Metoda 7: Filtrování jedinečných hodnot v aplikaci Excel pomocí kódu makra VBA
Z datového souboru víme, že máme sloupec Product, a chceme získat jedinečné hodnoty z tohoto sloupce. K dosažení tohoto úkolu můžeme použít následující příkaz VBA Makrokód. Můžeme napsat kód, který přiřadí hodnoty z výběru a pak je pošle přes smyčky, dokud se nezbaví všech duplicit.
Než použijeme VBA Makro kód, zajistíme, že máme datovou sadu následujícího typu a vybereme rozsah, ze kterého chceme filtrovat jedinečné.
Krok 1: Chcete-li napsat kód makra, stiskněte tlačítko ALT+F11 otevřít Microsoft Visual Basic V okně přejděte na položku Vložte (na kartě Panel nástrojů )> Vyberte Modul .
Krok 2: Na stránkách Modul Zobrazí se okno Modul , vložte následující kód.
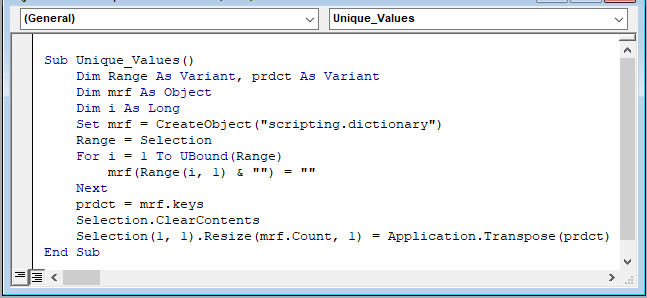
Sub Unique_Values() Dim Range As Variant, prdct As Variant Dim mrf As Object Dim i As Long Set mrf = CreateObject("scripting.dictionary") Range = Selection For i = 1 To UBound(Range) mrf(Range(i, 1) & "") = "" Next prdct = mrf.keys Selection.ClearContents Selection(1, 1).Resize(mrf.Count, 1) = Application.Transpose(prdct) End Sub V kódu makra,
Po deklaraci proměnných, mrf = CreateObject("scripting.dictionary") vytvoří objekt, který je přiřazen mrf .
Výběr přiděleno Rozsah . Pro Smyčka vezme každou buňku a porovná ji s Rozsah Poté kód vymaže pole Výběr a objevuje se s jedinečným .
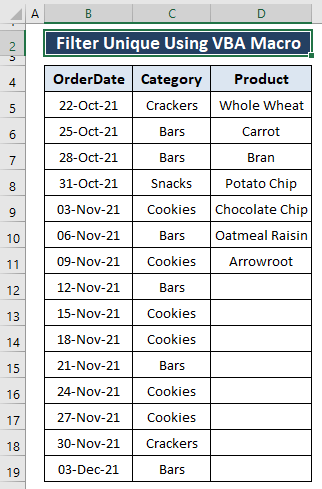
Krok 3: Hit F5 spustit makro, pak se po návratu na pracovní list zobrazí všechny jedinečné hodnoty z výběru.
Metoda 8: Použití tabulky Pivot k filtrování jedinečných hodnot
Otočná tabulka je silným nástrojem pro export seznamu jedinečných položek z vybraných buněk. V Excelu můžeme snadno vložit Pivot Table a dosáhnout toho, co si zde přejeme.
Krok 1: Vyberte určitý rozsah (tj, Produkt ). Poté přejděte na Vložte Karta> Vybrat Otočná tabulka (od Tabulky sekce).
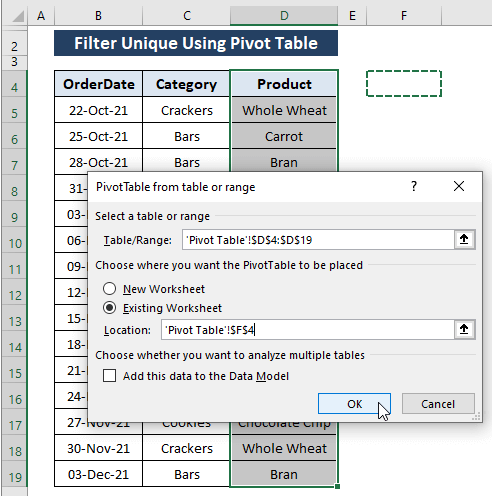
Krok 2: Na stránkách PivotTable z tabulky nebo rozsahu V okně se zobrazí okno,
Rozsah (tj, D4:D19 ) se automaticky vybere.
Vyberte si Stávající pracovní listy jako kam chcete umístit tabulku PivotTable. možnost.
Klikněte na OK .
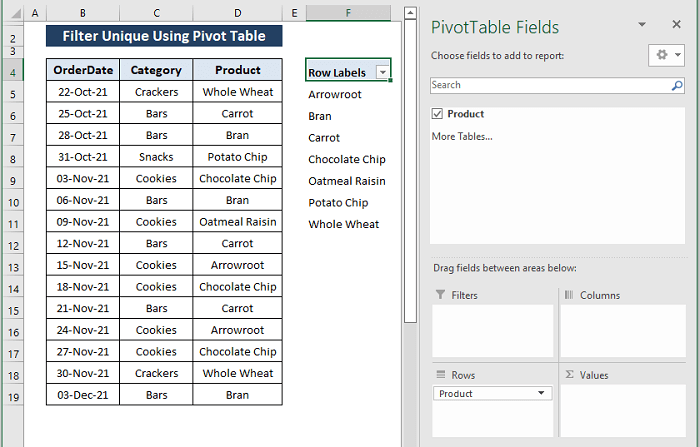
Krok 3: Na stránkách Pole PivotTable Zobrazí se okno Pole PivotTable okno, je zde pouze jedno pole (tj, Produkt ).
Zkontroloval jsem Produkt pole, aby se jedinečný seznam produktů zobrazil tak, jak je znázorněno na obrázku níže.
Přečtěte si více: Jak filtrovat tabulku Excel Pivot
Závěr
Jedinečný filtr je běžnou operací, kterou lze v Excelu provádět. V tomto článku používáme různé funkce, např. UNIKÁTNÍ , FILTR , MATCH , INDEX a také Makro VBA kód pro odfiltrování jedinečných hodnot. Funkce zachovávají surová data nedotčená a výsledné hodnoty zobrazují v jiném sloupci nebo cíli. Funkce však mění surová data tím, že trvale odstraňují položky z datového souboru. Doufám, že vám tento článek poskytne přehlednou představu o řešení duplicit v datových souborech a extrakci jedinečných hodnot. Pokud máte další dotazy nebo máteněco dodat. Uvidíme se v dalším článku.
