
Სარჩევი
Filter Unique არის ეფექტური გზა მონაცემთა ნაკრებში მრავალი ჩანაწერის გადასაჭრელად. Excel გთავაზობთ მრავალ ფუნქციას უნიკალური მონაცემების გასაფილტრად ან დუბლიკატების მოსაშორებლად, არ აქვს მნიშვნელობა რას ვუწოდებთ მას. ამ სტატიაში ჩვენ ვაჩვენებთ გზებს, რომ გავფილტროთ უნიკალური მონაცემები ნიმუშების მონაცემთა ნაკრებიდან.
ვთქვათ, რომ გვაქვს სამი მარტივი სვეტი Excel-ის მონაცემთა ბაზაში, რომელიც შეიცავს შეკვეთის თარიღს , კატეგორიას და პროდუქტი . ჩვენ გვინდა უნიკალური შეკვეთილი პროდუქტები მთელ მონაცემთა ბაზაში.
ჩამოტვირთეთ Excel სამუშაო წიგნი
უნიკალური მნიშვნელობების გაფილტვრა .xlsm
8 მარტივი გზა უნიკალური მნიშვნელობების გაფილტვრისთვის Excel-ში
მეთოდი 1: ექსელის გამოყენებით დუბლიკატების ამოღების ფუნქცია უნიკალური მნიშვნელობების გასაფილტრად
უზარმაზარ მონაცემთა ბაზაში ჩანაწერების გასაგებად, ზოგჯერ გვჭირდება დუბლიკატების ამოღება. Excel გთავაზობთ დუბლიკატების წაშლა ფუნქციას მონაცემები ჩანართში მონაცემთა ნაკრებიდან დუბლიკატი ჩანაწერების გამორიცხვის მიზნით. ამ შემთხვევაში, ჩვენ გვინდა წავშალოთ დუბლიკატები კატეგორია და პროდუქტი სვეტიდან. შედეგად, ჩვენ შეგვიძლია გამოვიყენოთ დუბლიკატების წაშლა ფუნქცია ამისთვის.
ნაბიჯი 1: აირჩიეთ დიაპაზონი (მაგ., კატეგორია და პროდუქტი ) შემდეგ გადადით მონაცემები ჩანართზე > აირჩიეთ დუბლიკატების წაშლა ( მონაცემთა ინსტრუმენტები განყოფილებიდან).
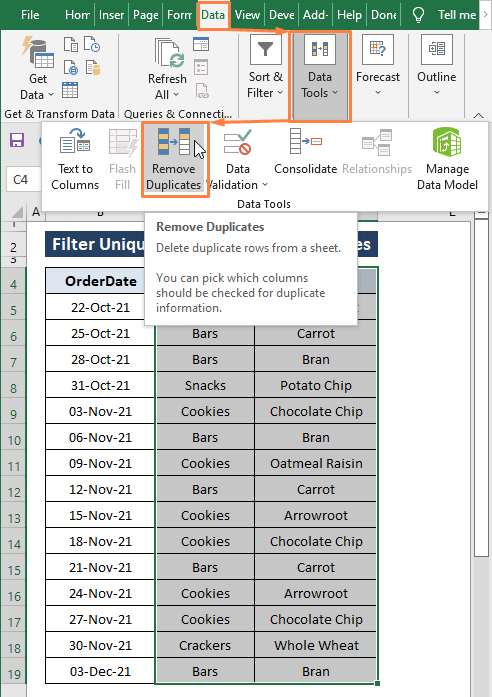
ნაბიჯი 2: <6 ჩნდება ფანჯარა>დუბლიკატების წაშლა . ფანჯარაში დუბლიკატების წაშლა ,
შეამოწმეთ ყველა სვეტი.
მონიშნეთ ვარიანტიTRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), „"), MATCH(ROW($F$5:$F$19) ), ROW ($F$5:$F$19))), 0)) ; აბრუნებს უნიკალურ მნიშვნელობებს მასივიდან.
ნაბიჯი 2: თქვენ უნდა დააჭიროთ საერთოდ CTRL+SHIFT+ENTER და ასოებისადმი მგრძნობიარე უნიკალური მნიშვნელობები გამოჩნდება უჯრედებში.
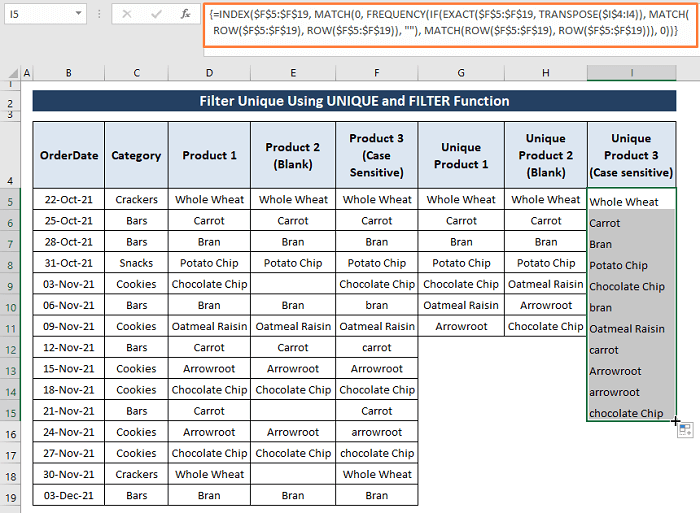
ასე რომ, მთელი მონაცემთა ნაკრები გამოიყურება შემდეგ სურათზე შემდეგში. ყველა ტიპის ჩანაწერის დახარისხება მათ შესაბამის სვეტებში.
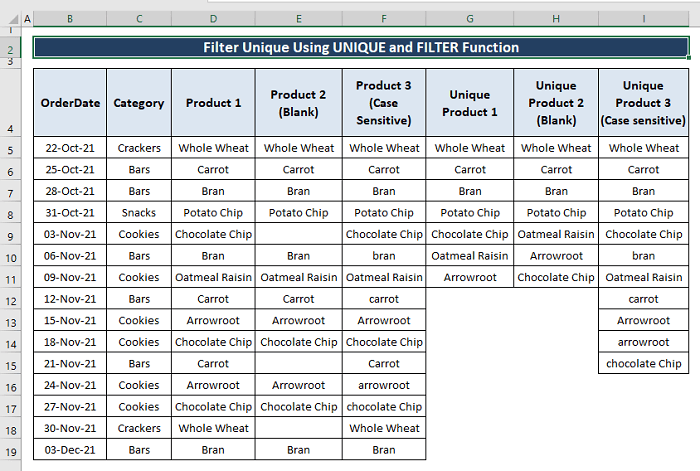
შეგიძლიათ შეცვალოთ პროდუქტის მონაცემთა რომელიმე ტიპი თქვენი მოთხოვნის შესასრულებლად და ამის მიხედვით გამოიყენოთ ფორმულები .
მეთოდი 7: Excel-ის ფილტრის უნიკალური მნიშვნელობები VBA მაკრო კოდის გამოყენებით
მონაცემთა ნაკრებიდან ვიცით, რომ გვაქვს Product სვეტი და გვინდა უნიკალური მნიშვნელობები სვეტი. სამუშაოს მისაღწევად, ჩვენ შეგვიძლია გამოვიყენოთ VBA მაკრო კოდი. ჩვენ შეგვიძლია დავწეროთ კოდი, რომელიც ანიჭებს მნიშვნელობებს შერჩევიდან, შემდეგ კი აგზავნის მას მარყუჟების მეშვეობით, თუ ის არ მოიშორებს ყველა დუბლიკატს.
სანამ VBA მაკრო კოდს გამოვიყენებთ, დავრწმუნდეთ, რომ გვაქვს მონაცემთა ნაკრები. შემდეგი ტიპის და ვირჩევთ დიაპაზონს, საიდანაც გვინდა გავფილტროთ უნიკალური.
ნაბიჯი 1: მაკრო კოდის დასაწერად, დააჭირეთ ALT+F11 , რომ გახსნათ Microsoft Visual Basic ფანჯარა. ფანჯარაში გადადით Insert ჩანართზე ( Toolbar ) > აირჩიეთ მოდული .
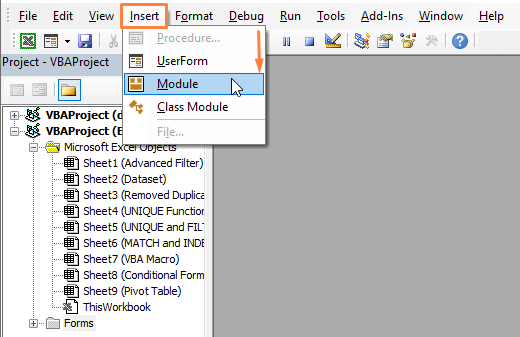
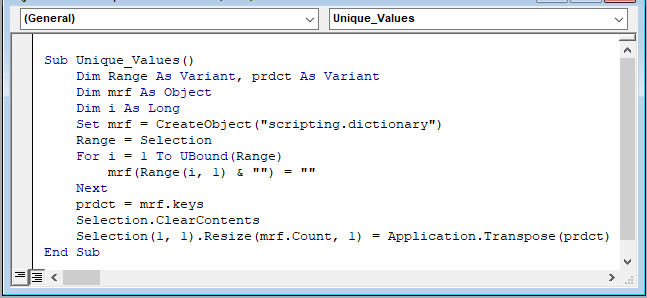
ნაბიჯი 2: გამოჩნდება ფანჯარა მოდული . მოდულში ,ჩასვით შემდეგი კოდი.
4831
მაკრო კოდში,
ცვლადების გამოცხადების შემდეგ, mrf = CreateObject("scripting.dictionary") ქმნის ობიექტს, რომელიც ენიჭება mrf .
არჩევანი მიენიჭა დიაპაზონს . For ციკლი იღებს თითოეულ უჯრედს, შემდეგ ემთხვევა დიაპაზონს დუბლიკატებისთვის. ამის შემდეგ, კოდი ასუფთავებს არჩევანს და გამოჩნდება უნიკალური .
ნაბიჯი 3: დააჭირეთ F5 მაკროს გასაშვებად, შემდეგ სამუშაო ფურცელზე დაბრუნებით ნახავთ ყველა უნიკალურ მნიშვნელობას შერჩეულიდან.
მეთოდი 8: Pivot Table-ის გამოყენება უნიკალური მნიშვნელობების გასაფილტრად
Pivot Table არის ძლიერი ინსტრუმენტი არჩეული უჯრედებიდან უნიკალური ელემენტების სიის ექსპორტისთვის. Excel-ში ჩვენ შეგვიძლია მარტივად ჩავსვათ Pivot Table და მივაღწიოთ იმას, რაც გვსურს აქ.
ნაბიჯი 1: აირჩიეთ გარკვეული დიაპაზონი (მაგ., პროდუქტი ). ამის შემდეგ გადადით Insert Tab > აირჩიეთ Pivot Table ( Tables განყოფილებიდან).
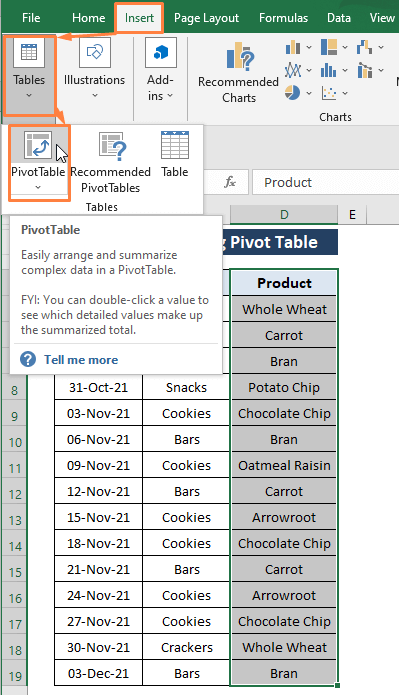
ნაბიჯი 2: PivotTable ცხრილიდან ან დიაპაზონიდან გამოჩნდება ფანჯარა. ფანჯარაში
დიაპაზონი (მაგ., D4:D19 ) ავტომატურად შეირჩევა.
აირჩიეთ არსებული სამუშაო ფურცლები როგორც სადაც გსურთ განთავსდეს PivotTable ვარიანტი.
დააწკაპუნეთ OK .
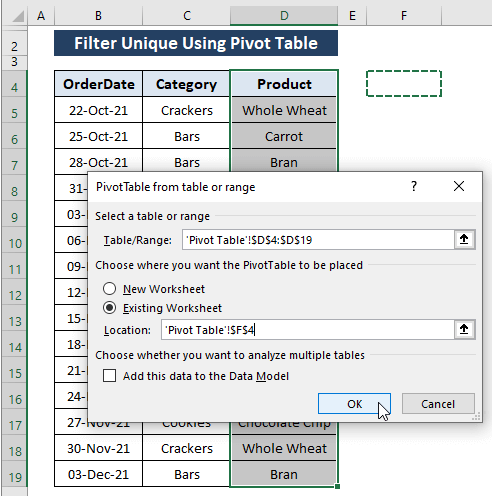
ნაბიჯი 3: გამოჩნდება ფანჯარა PivotTable Fields . PivotTable Fields ფანჯარაში არის მხოლოდ ერთი ველი (ე.ი. პროდუქტი ).
შეამოწმეთ პროდუქტი ველი, რათა გამოჩნდეს უნიკალური პროდუქტების სია, როგორც ნაჩვენებია ქვემოთ მოცემულ სურათზე.
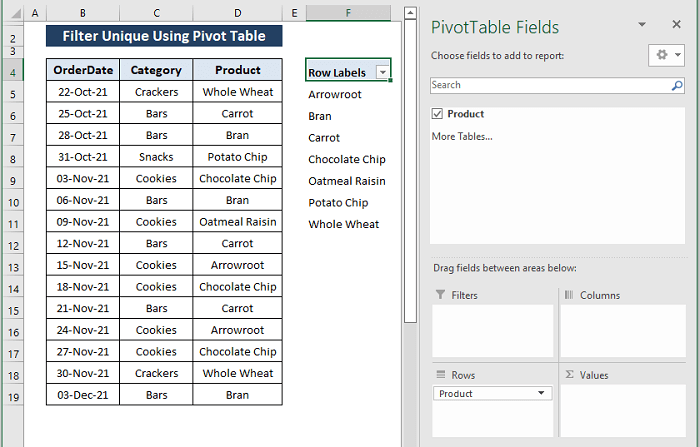
დაწვრილებით: როგორ გავფილტროთ Excel Pivot Table
დასკვნა
უნიკალური ფილტრი ჩვეულებრივი ოპერაციაა Excel-ში შესასრულებლად. ამ სტატიაში ჩვენ ვიყენებთ სხვადასხვა ფუნქციებს, ფუნქციებს, როგორიცაა UNIQUE , FILTER , MATCH , INDEX ასევე VBA მაკრო კოდი უნიკალური მნიშვნელობების გასაფილტრად. ფუნქციები უცვლელად ინახავს ნედლეულ მონაცემებს და აჩვენებს მიღებულ მნიშვნელობებს სხვა სვეტში ან დანიშნულებაში. თუმცა, ფუნქციები ცვლის ნედლეულ მონაცემებს მონაცემთა ნაკრებიდან ჩანაწერების სამუდამოდ წაშლით. ვიმედოვნებ, რომ ეს სტატია მოგცემთ თქვენს მონაცემთა ნაკრებში დუბლიკატებთან და უნიკალური მნიშვნელობების ამოღების მკაფიო კონცეფციას. დაწერეთ კომენტარი, თუ გაქვთ დამატებითი შეკითხვები ან გაქვთ რაიმე დასამატებელი. შევხვდებით ჩემს შემდეგ სტატიაში.
ჩემს მონაცემებს აქვს სათაურები .დააწკაპუნეთ OK .
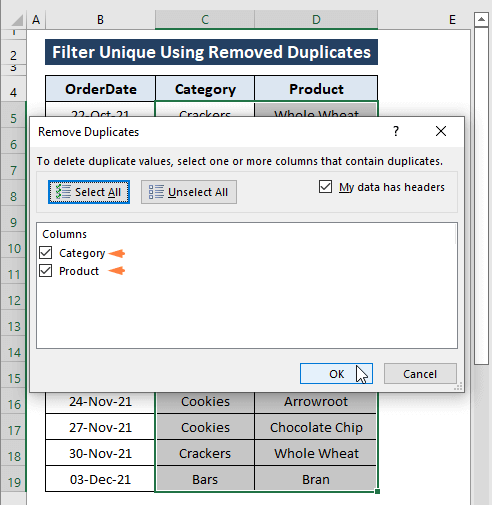
ნაბიჯი 3: ჩნდება დადასტურების დიალოგური ფანჯარა, რომელშიც ნათქვამია: 8 იპოვეს და წაიშალა დუბლიკატები; რჩება 7 უნიკალური მნიშვნელობა .
დააწკაპუნეთ OK .
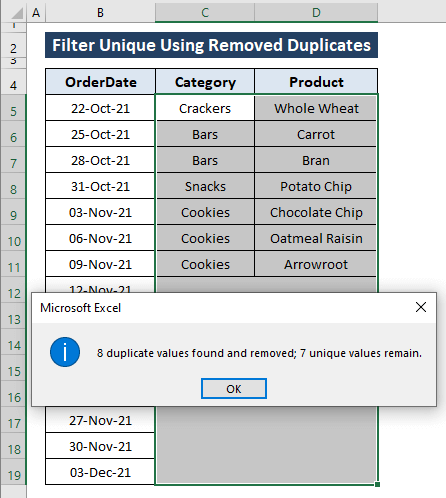
ყველა ნაბიჯი იწვევს შემდეგ შედეგებს, როგორც ეს ნაჩვენებია ქვემოთ მოცემულ სურათზე.
მეთოდი 2: პირობითი ფორმატირების გამოყენება უნიკალური მნიშვნელობების გასაფილტრად
უნიკალურის გაფილტვრის კიდევ ერთი გზაა პირობითი ფორმატირება . Excel პირობითი ფორმატირება შეუძლია უჯრედების დაფორმატება მრავალი კრიტერიუმით. თუმცა, ამ შემთხვევაში, ჩვენ ვიყენებთ ფორმულას უჯრედების პირობითად ფორმატირებისთვის დიაპაზონში (ანუ პროდუქტი სვეტი). ჩვენ გვაქვს ორი ვარიანტი პირობითი ფორმატირების გამოსაყენებლად; ერთი არის პირობითი ფორმატირება უნიკალური მნიშვნელობების გასაფილტრად და მეორე არის დუბლიკატების მნიშვნელობების დამალვა დიაპაზონიდან.
2.1. პირობითი ფორმატირება უნიკალური მნიშვნელობების გასაფილტრად
ამ შემთხვევაში, ჩვენ ვიყენებთ ფორმულას პირობითი ფორმატირების ვარიანტებში Excel-ის უნიკალური ჩანაწერების გასაფილტრად.
ნაბიჯი 1 : აირჩიეთ დიაპაზონი (ე.ი. პროდუქტი 1 ) შემდეგ გადადით მთავარი ჩანართზე > აირჩიეთ პირობითი ფორმატირება (სექციიდან სტილები ) > აირჩიეთ ახალი წესი .
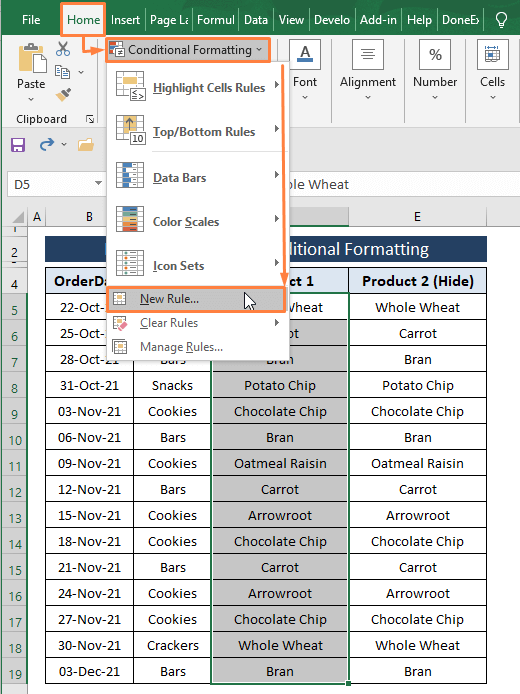
ნაბიჯი 2: იხსნება ფანჯარა ფორმატირების ახალი წესი . ფორმატირების ახალი წესი ფანჯარაში,
აირჩიეთ გამოიყენეთ ფორმულა, რათა დაადგინოთ რომელი უჯრედები დაფორმატოთ აირჩიეთ წესიაკრიფეთ ვარიანტი.
აკრიფეთ შემდეგი ფორმულა წესის აღწერილობის რედაქტირება ვარიანტის ქვეშ.
=COUNTIF($D$5:D5,D5)=1 ფორმულაში ჩვენ მივმართეთ Excel-ს, რომ დაეთვალა თითოეული უჯრედი D სვეტში, როგორც უნიკალურ (ანუ უდრის 1 ). თუ ჩანაწერები ემთხვევა დაწესებულ პირობას, ის უბრუნებს უჯრედებს TRUE და Color Format .
დააწკაპუნეთ Format .
ნაბიჯი 3: ცოტა ხანში გამოჩნდება ფანჯარა უჯრედების ფორმატირება . ფანჯარაში Cells Format ,
Font განყოფილებაში - აირჩიეთ ფორმატის ნებისმიერი ფერი, როგორც ეს ნაჩვენებია ქვემოთ მოცემულ სურათზე.
შემდეგ დააწკაპუნეთ OK .
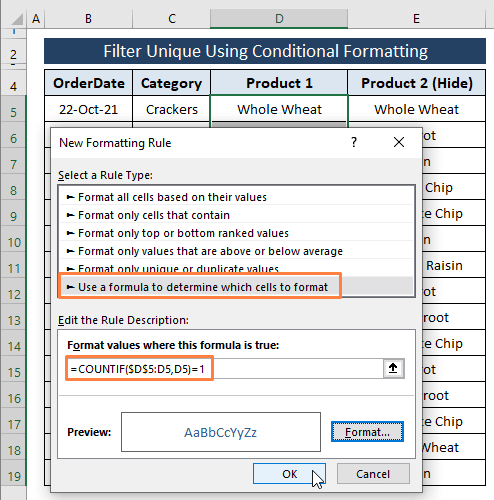
ნაბიჯი 4: დაწკაპუნებით OK წინა ნაბიჯი გადაგიყვანთ ახალზე ისევ ფორმატირების Rule ფანჯარა. ფანჯარაში ფორმატირების ახალი წესი შეგიძლიათ იხილოთ უნიკალური ჩანაწერების გადახედვა.
დააწკაპუნეთ OK .
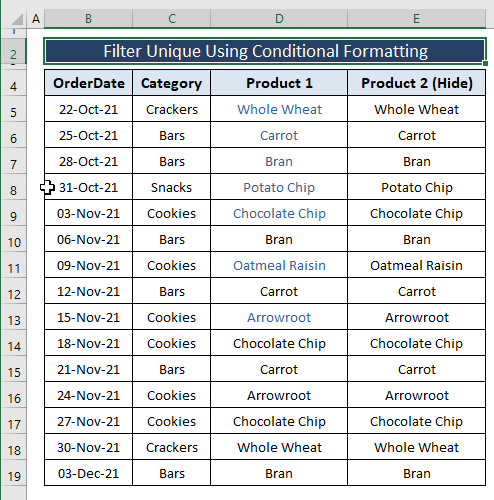
2.2. პირობითი ფორმატირება დუბლიკატების დასამალად
უნიკალურ მნიშვნელობებში ჩარევის გარეშე, ჩვენ შეგვიძლია უბრალოდ დავმალოთ დუბლიკატი მნიშვნელობები პირობითი ფორმატირების გამოყენებით. დუბლიკატების დასამალად, ჩვენ უნდა გამოვიყენოთ იგივე ფორმულა, რაც გავაკეთეთ უნიკალურების გასაფილტრად, გარდა 1 -ზე მეტი მნიშვნელობების მინიჭების გარდა. თეთრი შრიფტის ფერის არჩევის შემდეგ, ჩვენ შეგვიძლია დავმალოთ ისინი დანარჩენი ჩანაწერებიდან.
ნაბიჯი1: გაიმეორეთ ნაბიჯები 1 2 მეთოდი 2.1 , მაგრამ შეცვალეთ ჩასმული ფორმულა ქვემოთ მოცემული ფორმულით.
=COUNTIF($D$5:D5,D5)>1 ფორმულა ავალებს Excel-ს, რომ დაითვალოს თითოეული უჯრედი D სვეტში, როგორც დუბლიკატები (ე.ი. 1 -ზე მეტი). თუ ჩანაწერები ემთხვევა დაწესებულ პირობას, ის აბრუნებს უჯრედებს TRUE და ფერის ფორმატს (ე.ი. დამალვა ).
დააწკაპუნეთ ფორმატი .
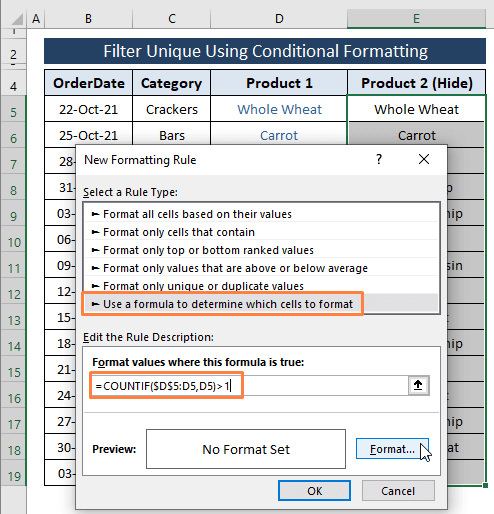
ნაბიჯი 2: ფორმატის დაწკაპუნებით გადაგიყვანთ უჯრედების ფორმატირება ფანჯარაში. ფანჯარაში უჯრედების ფორმატირება
აირჩიეთ შრიფტი ფერი თეთრი .
შემდეგ დააწკაპუნეთ OK .
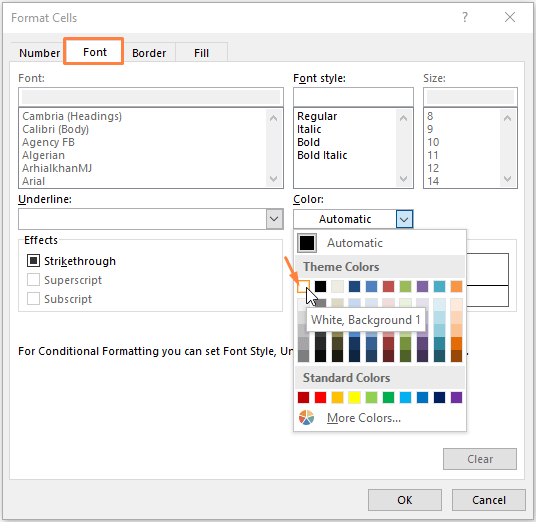
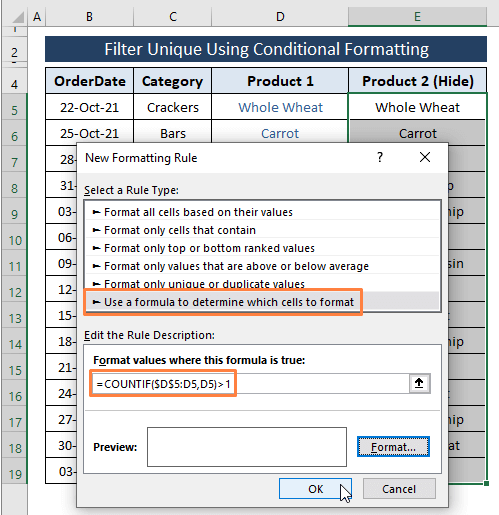
ნაბიჯი 3: შრიფტის ფერის არჩევის შემდეგ, დაწკაპუნებით OK გადაგიყვანთ ახალი ფორმატირების წესი ისევ ფანჯარა. თქვენ შეგიძლიათ ნახოთ წინასწარი გადახედვა, როგორც ბუნდოვანი, რადგან ჩვენ ვირჩევთ თეთრი როგორც ფონტის ფერად.
დააწკაპუნეთ OK .
ყველა ნაბიჯის შემდეგ მიგიყვანთ დუბლიკატი მნიშვნელობებისთვის ქვემოთ მოცემული სურათის მსგავსი გამოსახვამდე.
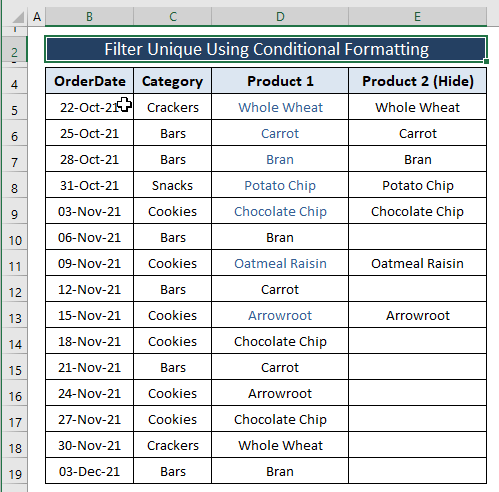
თქვენ უნდა აირჩიოთ თეთრი როგორც ფონტის ფერი, წინააღმდეგ შემთხვევაში დუბლიკატი ჩანაწერები არ დაიმალება.
დაწვრილებით: როგორ გავფილტროთ მონაცემები Excel-ში ფორმულის გამოყენებით
მეთოდი 3: მონაცემთა ჩანართის გაფართოებული ფილტრის ფუნქციის გამოყენება უნიკალური მნიშვნელობების გასაფილტრად
ადრინდელი მეთოდები წაშლის ან წაშლის ჩანაწერებს მონაცემთა ნაკრებიდან უნიკალური გასაფილტრად. ეს საკმაოდ საშიშია, სანამ ჩვენ ვმუშაობთ გარკვეულ მონაცემთა ნაკრებებზე. შეიძლება იყოს სიტუაციები, როდესაც ჩვენ არ შეგვიძლიაშევცვალოთ ნედლეული მონაცემთა ნაკრები, ასეთ შემთხვევებში ჩვენ შეგვიძლია გამოვიყენოთ Advanced Filter ოფცია უნიკალური გასაფილტრად სასურველ პოზიციაზე.
ნაბიჯი 1: აირჩიეთ დიაპაზონი (ე.ი. პროდუქტი სვეტი). შემდეგ გადადით მონაცემები ჩანართზე > აირჩიეთ Advanced ( Sort & Filter განყოფილებიდან).
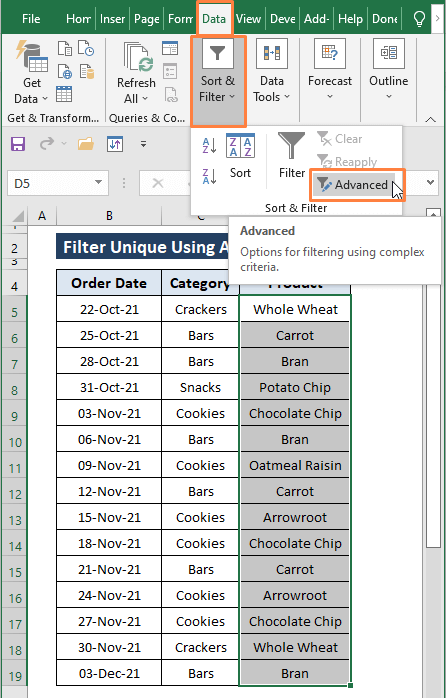
ნაბიჯი 2: <6 ჩნდება ფანჯარა>Advanced Filter . Advanced Filter ფანჯარაში,
აირჩიეთ Copy to other location action Action ოფცია. თქვენ შეგიძლიათ აირჩიოთ სიის გაფილტვრა, ადგილზე, ან კოპირება სხვა ადგილას თუმცა, ჩვენ ვირჩევთ ამ უკანასკნელს, რათა არ შევცვალოთ ნედლეული მონაცემები.
მიანიჭეთ მდებარეობა (მაგ., F4 ) Copy to ოფციაში.
მონიშნეთ უნიკალური ჩანაწერები მხოლოდ ვარიანტი.
დააწკაპუნეთ OK .
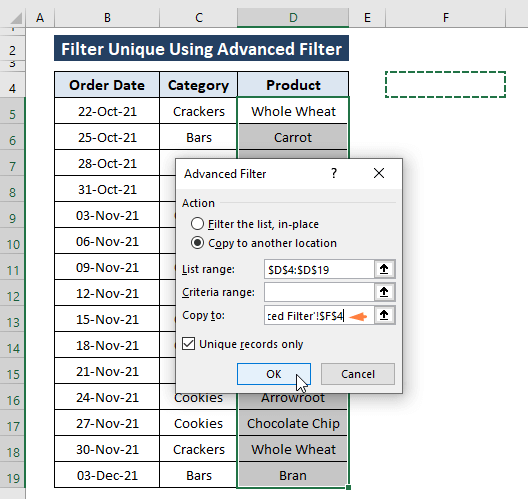
დაწკაპუნებით OK მიიღებთ უნიკალურ მნიშვნელობებს დანიშნულ ადგილას, როგორც ეს მითითებულია ნაბიჯებში.
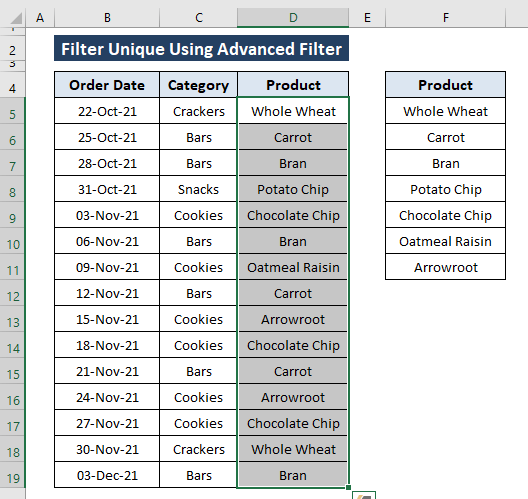
მეთოდი 4: უნიკალური მნიშვნელობების გაფილტვრა Excel UNIQUE ფუნქციის გამოყენებით
უნიკალური მნიშვნელობების სხვა სვეტში ჩვენება ასევე შესაძლებელია UNIQUE ფუნქცია. ფუნქცია UNIQUE იღებს უნიკალური ჩანაწერების სიას დიაპაზონიდან ან მასივიდან. UNIQUE ფუნქციის სინტაქსია
UNIQUE (array, [by_col], [exactly_once])
არგუმენტები,
მასივი ; დიაპაზონი, ან მასივი, საიდანაც ამოღებულია უნიკალური მნიშვნელობები.
[by_col] ; მნიშვნელობების შედარებისა და ამოღების გზები, სტრიქონი = FALSE ( ნაგულისხმევი )და სვეტი = TRUE . <[სურვილისამებრ]
[ზუსტად_ერთხელ] ; ერთხელ არსებული მნიშვნელობები = TRUE და არსებული უნიკალური მნიშვნელობები = FALSE ( ნაგულისხმევი ). [არასავალდებულო]
ნაბიჯი 1: ჩაწერეთ შემდეგი ფორმულა ნებისმიერ ცარიელ უჯრედში (მაგ., E5 ).
=UNIQUE(D5:D19) 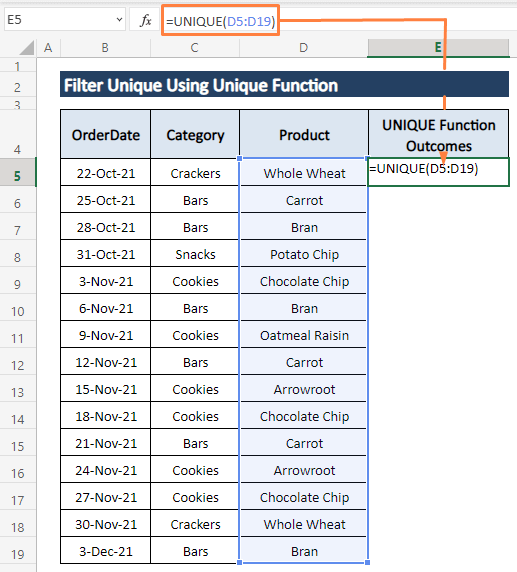
ნაბიჯი 2: დააჭირეთ ENTER და წამში ყველა უნიკალური ჩანაწერი გამოჩნდება სვეტში, როგორც ქვემოთ მოცემული სურათი.
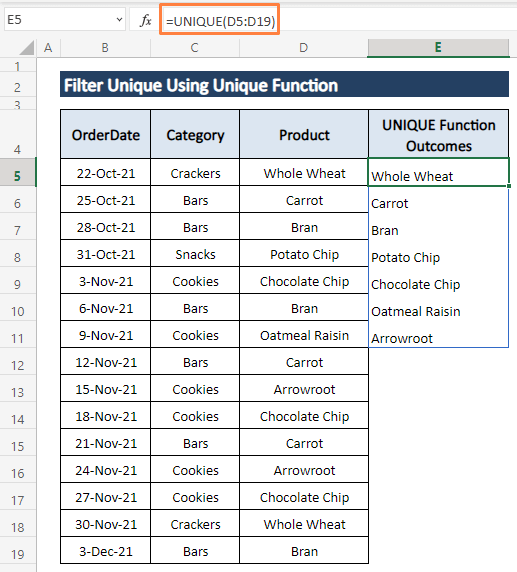
UNIQUE ფუნქცია ავრცელებს ყველა უნიკალურ ჩანაწერს ერთდროულად. თუმცა, თქვენ არ შეგიძლიათ გამოიყენოთ UNIQUE ფუნქცია, გარდა Excel 365 ვერსიისა.
მსგავსი წაკითხვები
- Excel-ის ფილტრის მონაცემები უჯრედის მნიშვნელობის საფუძველზე (6 ეფექტური გზა)
- როგორ დავამატო ფილტრი Excel-ში (4 მეთოდი)
- Excel ფილტრის მალსახმობი (3 სწრაფი გამოყენება მაგალითებით)
- როგორ გამოვიყენოთ ტექსტის ფილტრი Excel-ში (5 მაგალითი)
მეთოდი 5: UNIQUE და FILTER ფუნქციების გამოყენებით (კრიტერიუმებით)
მე-4 მეთოდში ვიყენებთ UNIQUE ფუნქციას უნიკალური მნიშვნელობების გასავრცელებლად. რა მოხდება, თუ ჩვენ გვინდა უნიკალური ჩანაწერები მდგომარეობიდან გამომდინარე? დავუშვათ, რომ გვინდა უნიკალური პროდუქტის სახელები გარკვეული კატეგორიის ჩვენი მონაცემთა ბაზიდან.
ამ შემთხვევაში, ჩვენ გვინდა პროდუქტის უნიკალური სახელები. Bars (ანუ E4 ) კატეგორია ჩვენი მონაცემთა ნაკრებიდან.
ნაბიჯი 1: ჩაწერეთ ქვემოთ მოცემული ფორმულა ნებისმიერ უჯრედში (ე.ი., E5 ).
=UNIQUE(FILTER(D5:D19,C5:C19=E4)) ფორმულა ავალებს D5:D19 დიაპაზონის გაფილტვრას, აწესებს პირობას C5:C19 დიაპაზონზე, რომ იყოს E4 უჯრედის ტოლი.
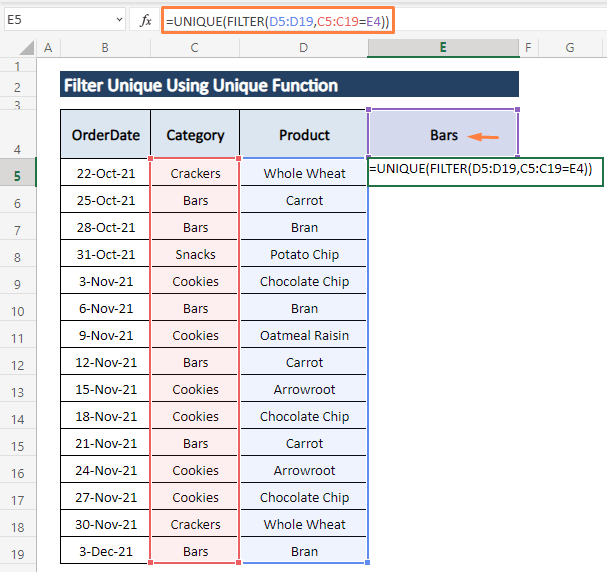
ნაბიჯი 2: დააჭირეთ ENTER . ამის შემდეგ პროდუქტები Bars კატეგორიაში, გამოჩნდება Bars სვეტის უჯრედებში, როგორც ნაჩვენებია შემდეგ ეკრანის სურათზე.
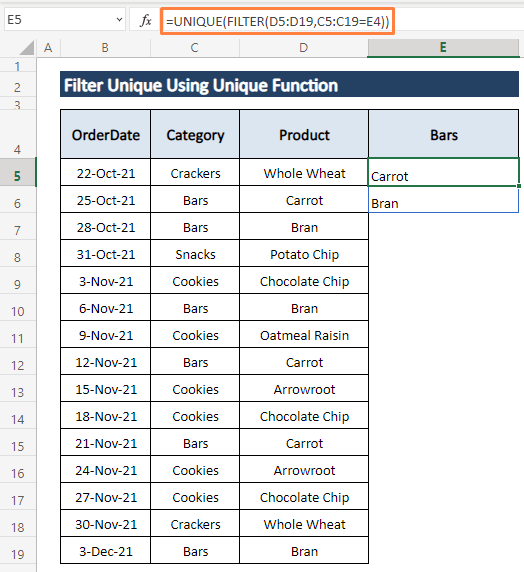
თქვენ შეგიძლიათ აირჩიოთ ნებისმიერი კატეგორია უნიკალური პროდუქტების გასაფილტრად. ეს საკმაოდ ეფექტური გზაა უზარმაზარი გაყიდვების მონაცემთა ნაკრების დასამუშავებლად. ფუნქცია FILTER ხელმისაწვდომია მხოლოდ Excel 365-ში.
დაწვრილებით: გაფილტრეთ მრავალი კრიტერიუმი Excel-ში
მეთოდი 6: MATCH და INDEX ფუნქციების გამოყენება (Array Formula)
უფრო მარტივი დემონსტრირებისთვის, ჩვენ ვიყენებთ მონაცემთა ბაზას ცარიელი ან რეგისტრირებული ჩანაწერების გარეშე. მაშ, როგორ მოვახერხოთ ისეთი მონაცემთა ნაკრები, რომელსაც აქვს ცარიელი და რეგისტრირებული ჩანაწერები? გამოსავლის დემონსტრირებამდე, მოდით გავფილტროთ არა ცარიელი დიაპაზონი (ე.ი. პროდუქტი 1 ) კომბინირებული ფორმულის გამოყენებით. ამ შემთხვევაში, ჩვენ ვიყენებთ MATCH და INDEX ფუნქციებს უნიკალური გასაფილტრად.
6.1. MATCH და INDEX ფუნქციები გავფილტროთ უნიკალური მნიშვნელობები არა ცარიელი დიაპაზონიდან
ჩვენ ვხედავთ, რომ არ არის არსებული ცარიელი უჯრედები პროდუქტის 1 დიაპაზონში.
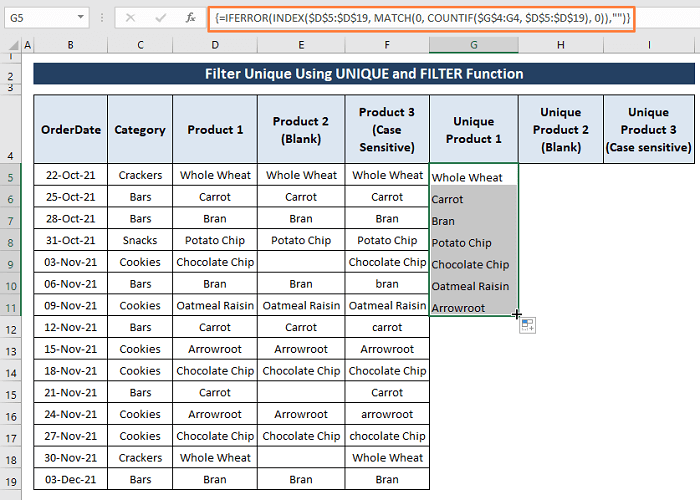
ნაბიჯი 1: ჩაწერეთ შემდეგი ფორმულა უჯრედში G5 უნიკალურის გასაფილტრად.
=IFERROR(INDEX($D$5:$D$19, MATCH(0, COUNTIF($G$4:G4, $D$5:$D$19), 0)),"") ფორმულის მიხედვით,
პირველი, COUNTIF($G$4:G4, $D$5:$D$19) ; ითვლის დიაპაზონში უჯრედების რაოდენობას (ე.ი. $G$4:G4 ) ემორჩილება პირობას (ე.ი., $D$5:$D$19) . COUNTIF აბრუნებს 1 თუ იპოვის $G$4:G4 დიაპაზონში, წინააღმდეგ შემთხვევაში 0 .
მეორე, MATCH(0, COUNTIF($G$4:G4, $D$5:$D$19), 0)) ; აბრუნებს პროდუქტის შედარებით პოზიციას დიაპაზონში.
ბოლოს, INDEX($D$5:$D$19, MATCH(0, COUNTIF($G$4:G4 , $D$5:$D$19), 0)); აბრუნებს უჯრედის შენატანებს, რომლებიც აკმაყოფილებენ პირობას.
IFERROR ფუნქცია ზღუდავს ფორმულას შეცდომის ჩვენება შედეგში.
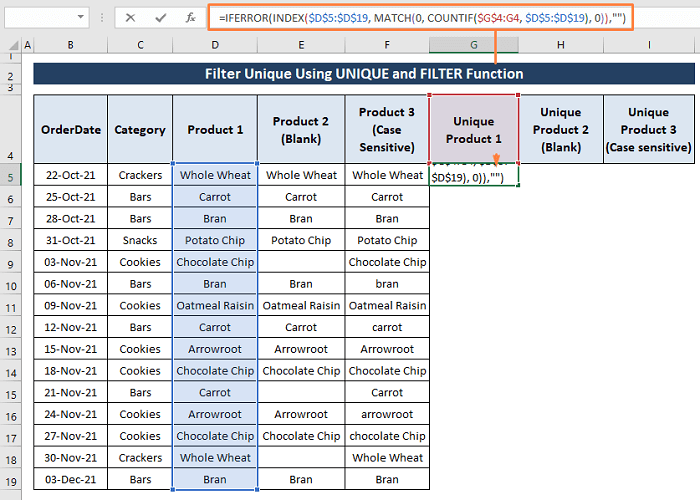
ნაბიჯი 2: რადგან ფორმულა არის მასივის ფორმულა, დააჭირეთ CTRL+SHIFT+ENTER საერთოდ. გამოჩნდება ყველა უნიკალური ჩანაწერი პროდუქტი 1 დიაპაზონიდან.
6.2. MATCH და INDEX ფუნქციები დიაპაზონში არსებული ცარიელი უჯრედებიდან უნიკალური მნიშვნელობების გასაფილტრად
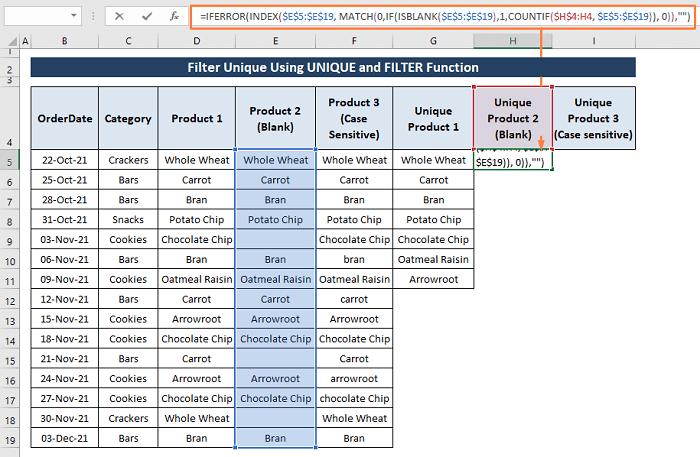
ახლა, პროდუქტი 2 დიაპაზონში, ჩვენ ვხედავთ მრავალი ცარიელი უჯრედის არსებობას. ცარიელ უჯრედებს შორის უნიკალურის გასაფილტრად, უნდა ჩავსვათ ISBLANK ფუნქცია.
ნაბიჯი 1: ჩასვით ქვემოთ მოცემული ფორმულა უჯრედში H5 .
=IFERROR(INDEX($E$5:$E$19, MATCH(0,IF(ISBLANK($E$5:$E$19),1,COUNTIF($H$4:H4, $E$5:$E$19)), 0)),"") ეს ფორმულა მუშაობს ისევე, როგორც ეს აღწერილია 6.1-ში. სექცია . თუმცა, დამატებითი IF ფუნქცია ISBLANK ფუნქციის ლოგიკური ტესტით საშუალებას აძლევს ფორმულას უგულებელყოს ნებისმიერი ცარიელი უჯრედი დიაპაზონში.
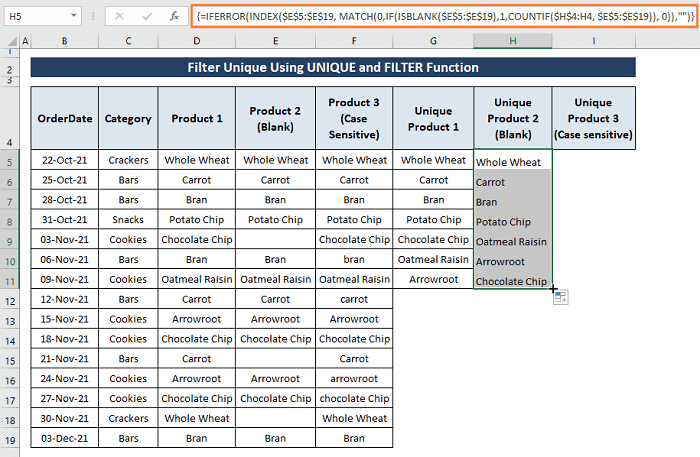
ნაბიჯი 2: დააჭირეთ CTRL+SHIFT+ENTER და ფორმულა იგნორირებას უკეთებს ცარიელ უჯრედებს და იღებს ყველა უნიკალურ ჩანაწერსროგორც ნაჩვენებია შემდეგ სურათზე.
6.3. MATCH და INDEX ფუნქციები, რათა გავფილტროთ უნიკალური მნიშვნელობები რეგისტრის მგრძნობელობის დიაპაზონიდან
თუ ჩვენს მონაცემთა ბაზაში არის ჩანაწერები, რომლებიც მგრძნობიარეა რეგისტრის მიმართ, ჩვენ უნდა გამოვიყენოთ FREQUENCY ფუნქცია <6-თან ერთად>TRANSPOSE და ROW ფუნქციები უნიკალურის გასაფილტრად.
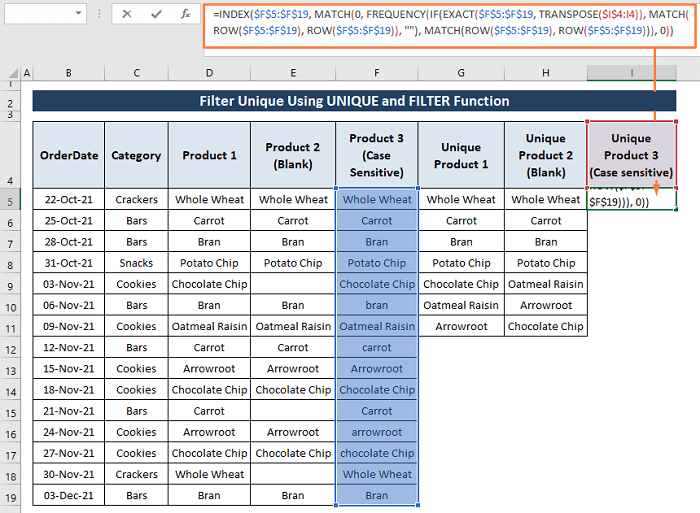
ნაბიჯი 1: გამოიყენეთ ქვემოთ მოცემული ფორმულა უჯრედში I5 .
=INDEX($F$5:$F$19, MATCH(0, FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19))), 0)) ფორმულის სექციები,
- TRANSPOSE($I$4:I4); წინა მნიშვნელობების ტრანსპოზირება მძიმით მძიმით გარდაქმნით. ( ანუ, TRANSPOSE({“unique values (case sensitive)”; Whole Wheat”}) ხდება {“უნიკალური მნიშვნელობები (case sensitive)”,” მთლიანი ხორბალი”}
- EXACT($F$5:$F$19, TRANSPOSE($I$4:I4); ამოწმებს, არის თუ არა სტრიქონები ერთნაირი და რეგისტრის მგრძნობიარეა თუ არა.
- IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F $19)); აბრუნებს სტრიქონის შედარებით პოზიციას მასივში, თუ TRUE .
- FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE ($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), „“) ; ითვლის რამდენჯერ არის სტრიქონი წარმოდგენილი მასივი.
- MATCH(0, სიხშირე(თუ(ზუსტი($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F $19), ROW ($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19))), 0)) ; პოულობს პირველ ცრუ (ე.ი. ცარიელი ) მნიშვნელობებს მასივში.
- INDEX($F$5:$F$19, MATCH(0, FREQUENCY(IF(EXACT( $F$5:$F$19,
