
विषयसूची
फ़िल्टर यूनिक एक डेटासेट में कई प्रविष्टियों के साथ काम करने का एक प्रभावी तरीका है। एक्सेल अद्वितीय डेटा को फ़िल्टर करने या डुप्लिकेट को हटाने के लिए कई सुविधाएँ प्रदान करता है, इससे कोई फर्क नहीं पड़ता कि हम इसे क्या कहते हैं। इस लेख में, हम एक नमूना डेटासेट से अद्वितीय डेटा को फ़िल्टर करने के तरीके प्रदर्शित करेंगे।
मान लें कि हमारे पास एक्सेल डेटासेट में तीन सरल कॉलम हैं जिनमें आदेश दिनांक , श्रेणी शामिल है , और उत्पाद । हम संपूर्ण डेटासेट में अद्वितीय ऑर्डर किए गए उत्पाद चाहते हैं।
Excel वर्कबुक डाउनलोड करें
अद्वितीय मानों को फ़िल्टर करना .xlsm
एक्सेल में अद्वितीय मानों को फ़िल्टर करने के 8 आसान तरीके
पद्धति 1: एक्सेल का उपयोग करके अद्वितीय मानों को फ़िल्टर करने के लिए डुप्लिकेट निकालें सुविधा
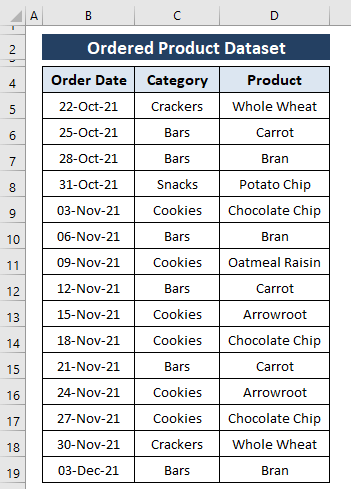
एक विशाल डेटासेट में प्रविष्टियों की थाह लेने के लिए, हमें कभी-कभी डुप्लीकेट को हटाने की आवश्यकता होती है। एक्सेल डेटा टैब में डुप्लिकेट हटाएं सुविधा प्रदान करता है ताकि डेटासेट से डुप्लिकेट प्रविष्टियों को हटाया जा सके। इस मामले में, हम डुप्लिकेट को श्रेणी और उत्पाद कॉलम से हटाना चाहते हैं। परिणामस्वरूप, हम ऐसा करने के लिए डुप्लिकेट हटाएं सुविधा का उपयोग कर सकते हैं।
चरण 1: श्रेणी का चयन करें (यानी, श्रेणी और उत्पाद ) फिर डेटा टैब > डुप्लिकेट हटाएं चुनें ( डेटा टूल्स अनुभाग से)।
चरण 2: डुप्लिकेट हटाएं विंडो प्रकट होती है। डुप्लिकेट हटाएं विंडो में,
सभी कॉलम चेक किए गए।
विकल्प को चेक करेंTRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19) ), ROW($F$5:$F$19))), 0)) ; सरणी से अद्वितीय मान देता है।
चरण 2: आपको CTRL+SHIFT+ENTER एक साथ दबाना होगा और केस-संवेदी अद्वितीय मान कोशिकाओं में दिखाई देते हैं। सभी प्रकार की प्रविष्टियों को उनके संबंधित कॉलम में क्रमबद्ध करना।
आप अपनी मांग को पूरा करने के लिए किसी भी उत्पाद डेटा प्रकार को बदल सकते हैं और उसके अनुसार सूत्र लागू कर सकते हैं। .
विधि 7: VBA मैक्रो कोड का उपयोग करके एक्सेल फ़िल्टर अद्वितीय मान
डेटासेट से, हम जानते हैं कि हमारे पास एक उत्पाद कॉलम है, और हम अद्वितीय मान चाहते हैं कॉलम। कार्य को प्राप्त करने के लिए, हम VBA मैक्रो कोड का उपयोग कर सकते हैं। हम एक कोड लिख सकते हैं जो चयन से मूल्यों को निर्दिष्ट करता है और फिर इसे लूप के माध्यम से भेजता है जब तक कि यह सभी डुप्लीकेट से छुटकारा नहीं पाता।
इससे पहले कि हम VBA मैक्रो कोड लागू करें, आइए सुनिश्चित करें कि हमारे पास एक डेटासेट है निम्न प्रकार का और हम उस श्रेणी का चयन करते हैं जहाँ से हम अद्वितीय को फ़िल्टर करना चाहते हैं।
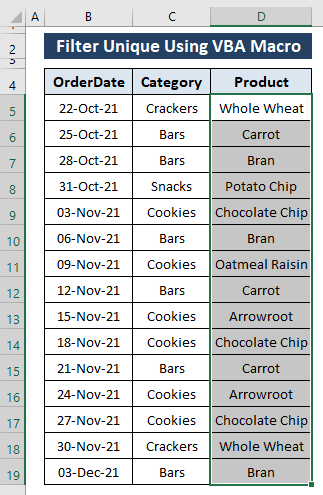
चरण 1: एक मैक्रो कोड लिखने के लिए, Microsoft Visual Basic विंडो खोलने के लिए ALT+F11 दबाएं. विंडो में, इन्सर्ट टैब पर जाएं ( टूलबार में) > मॉड्यूल चुनें।
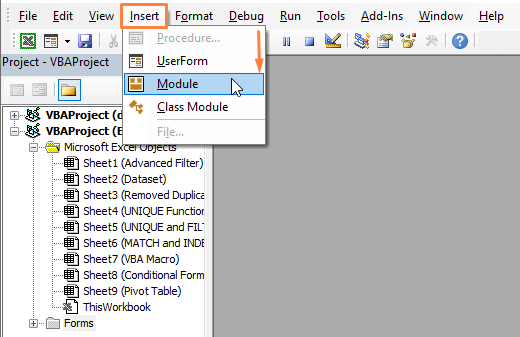
चरण 2: मॉड्यूल विंडो दिखाई देती है। मॉड्यूल में,निम्नलिखित कोड पेस्ट करें।
8465
मैक्रो कोड में,
वैरिएबल घोषित करने के बाद, mrf = CreateObject(“scripting.dictionary”) एक ऑब्जेक्ट बनाता है जिसे असाइन किया गया है एमआरएफ ।
चयन श्रेणी को सौंपा गया। फॉर लूप प्रत्येक सेल लेता है फिर डुप्लिकेट के लिए रेंज के साथ मेल खाता है। उसके बाद, कोड चयन को साफ़ करता है और अद्वितीय के साथ दिखाई देता है।
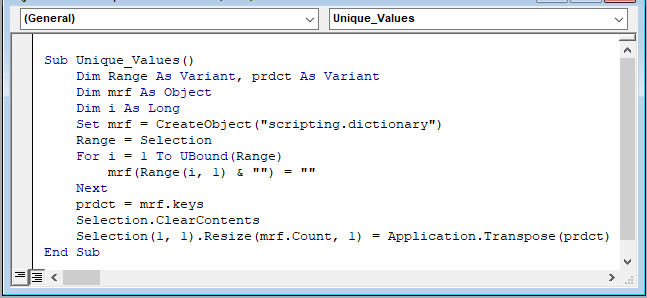
चरण 3: मैक्रो को चलाने के लिए F5 हिट करें फिर वर्कशीट पर वापस आकर, आप चयन से सभी अद्वितीय मान देख सकते हैं।
विधि 8: अद्वितीय मानों को फ़िल्टर करने के लिए पिवट तालिका का उपयोग करना
पाइवट टेबल चयनित सेल से अद्वितीय आइटम सूची निर्यात करने के लिए एक मजबूत टूल है। एक्सेल में, हम आसानी से एक पिवोट टेबल डाल सकते हैं और यहां हम जो चाहते हैं उसे प्राप्त कर सकते हैं।
चरण 1: एक निश्चित सीमा का चयन करें (यानी, उत्पाद )। बाद में, सम्मिलित करें टैब > पाइवट टेबल चुनें ( टेबल्स अनुभाग से)।
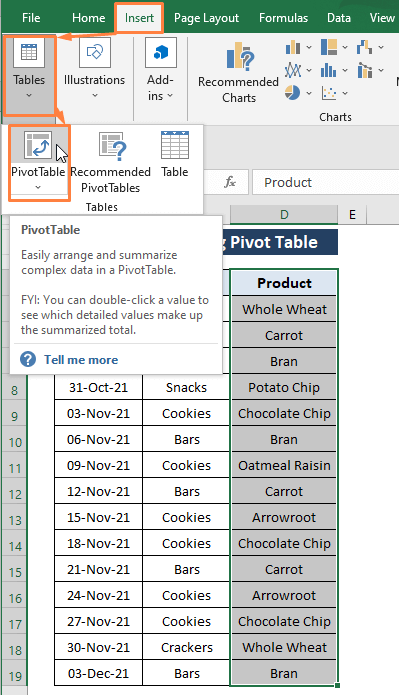
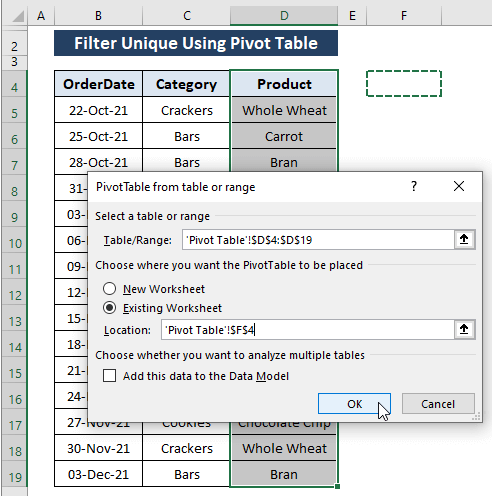
चरण 2: पिवोटटेबल तालिका या श्रेणी से विंडो प्रकट होती है। विंडो में,
श्रेणी (यानी, D4:D19 ) स्वचालित रूप से चुनी जाएगी।
मौजूदा वर्कशीट को जहां चुनें आप चाहते हैं कि PivotTable को रखा जाए विकल्प।
ठीक क्लिक करें।
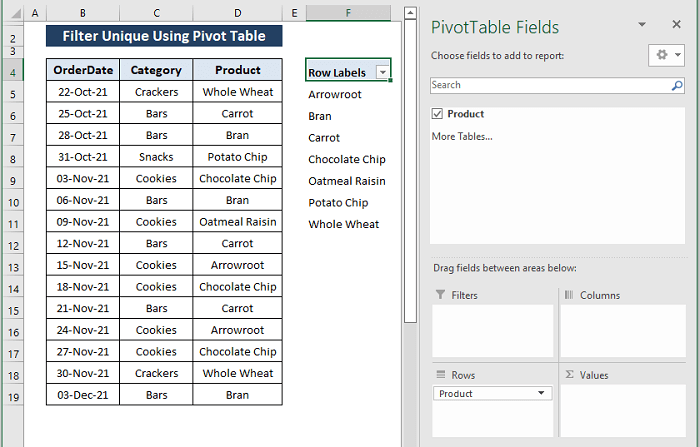
चरण 3: PivotTable फ़ील्ड्स विंडो प्रकट होती है। PivotTable फ़ील्ड्स विंडो में, केवल एक फ़ील्ड है (अर्थात, उत्पाद )।
विशिष्ट उत्पाद सूची को नीचे दी गई तस्वीर के अनुसार प्रदर्शित करने के लिए उत्पाद फ़ील्ड को चेक किया गया।
 <1
<1
और पढ़ें: एक्सेल पिवट टेबल को कैसे फ़िल्टर करें
निष्कर्ष
फ़िल्टर यूनिक एक सामान्य ऑपरेशन है एक्सेल में प्रदर्शन करने के लिए। इस लेख में, हम विभिन्न विशेषताओं, कार्यों का उपयोग करते हैं जैसे UNIQUE , FILTER , MATCH , INDEX साथ ही VBA मैक्रो अद्वितीय मानों को फ़िल्टर करने के लिए कोड। कार्य कच्चे डेटा को बरकरार रखते हैं और परिणामी मूल्यों को दूसरे कॉलम या गंतव्य में प्रदर्शित करते हैं। हालाँकि, सुविधाएँ स्थायी रूप से डेटासेट से प्रविष्टियों को हटाकर कच्चे डेटा को बदल देती हैं। मुझे उम्मीद है कि यह लेख आपको अपने डेटासेट में डुप्लिकेट से निपटने और अद्वितीय मान निकालने की एक स्पष्ट अवधारणा देता है। टिप्पणी, यदि आपके पास और प्रश्न हैं या कुछ जोड़ने के लिए है। मिलते हैं मेरे अगले लेख में।
मेरे डेटा में हेडर हैं ।ठीक क्लिक करें।
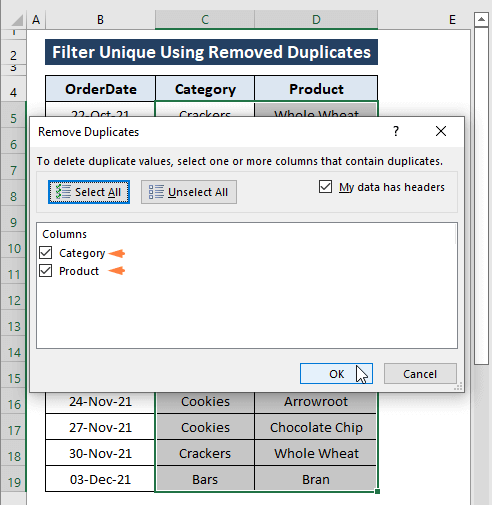
चरण 3: एक पुष्टिकरण संवाद बॉक्स प्रकट होता है, जिसमें कहा गया है कि 8 डुप्लिकेट मान पाए गए और हटा दिए गए; 7 अद्वितीय मान बने रहें ।
ठीक क्लिक करें .
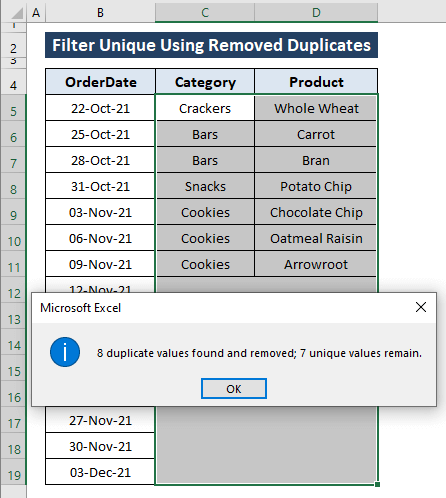
नीचे दी गई छवि में दिखाए गए अनुसार सभी कदम निम्नलिखित परिणामों की ओर ले जाते हैं।
विधि 2: विशिष्ट मानों को फ़िल्टर करने के लिए सशर्त स्वरूपण का उपयोग
विशिष्ट को फ़िल्टर करने का दूसरा तरीका सशर्त स्वरूपण है। एक्सेल सशर्त स्वरूपण कई मानदंडों के साथ कोशिकाओं को प्रारूपित कर सकता है। हालाँकि, इस मामले में, हम एक श्रेणी (यानी, उत्पाद कॉलम) में कोशिकाओं को सशर्त रूप से स्वरूपित करने के लिए एक सूत्र का उपयोग करते हैं। सशर्त स्वरूपण लागू करने के लिए हमारे पास दो विकल्प हैं; एक अद्वितीय मानों को फ़िल्टर करने के लिए सशर्त स्वरूपण है और दूसरा श्रेणी से डुप्लिकेट मानों को छिपाने के लिए है।
2.1। अद्वितीय मानों को फ़िल्टर करने के लिए सशर्त स्वरूपण
इस मामले में, हम सशर्त स्वरूपण विकल्पों में एक्सेल फ़िल्टर अद्वितीय प्रविष्टियों के लिए एक सूत्र का उपयोग करते हैं।
चरण 1 : श्रेणी का चयन करें (यानी, उत्पाद 1 ) फिर होम टैब पर जाएं > सशर्त स्वरूपण चुनें ( शैली अनुभाग से) > नया नियम चुनें।
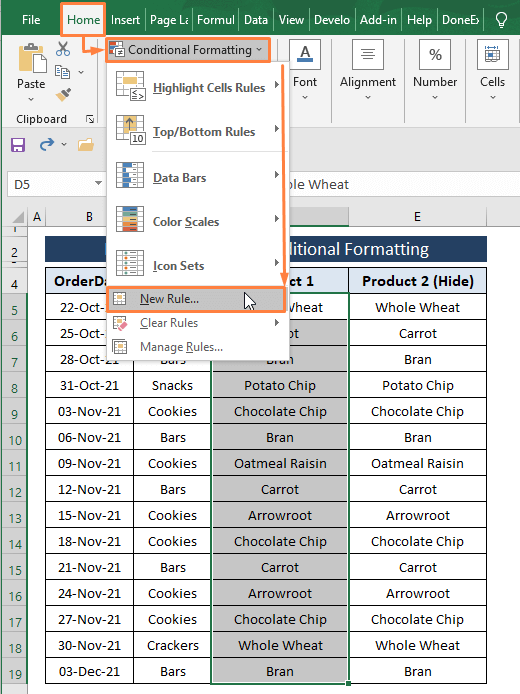
चरण 2: नया फ़ॉर्मेटिंग नियम विंडो खुलती है। नया फ़ॉर्मेटिंग नियम विंडो में,
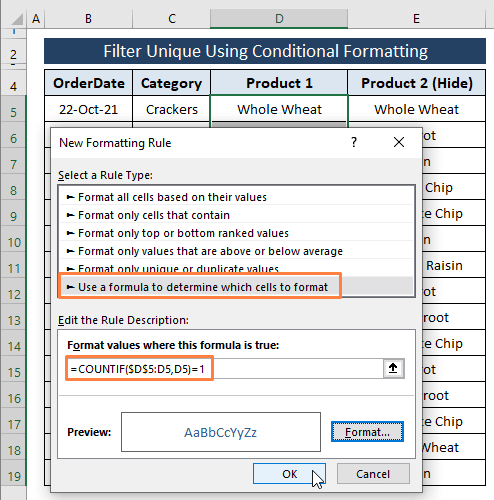
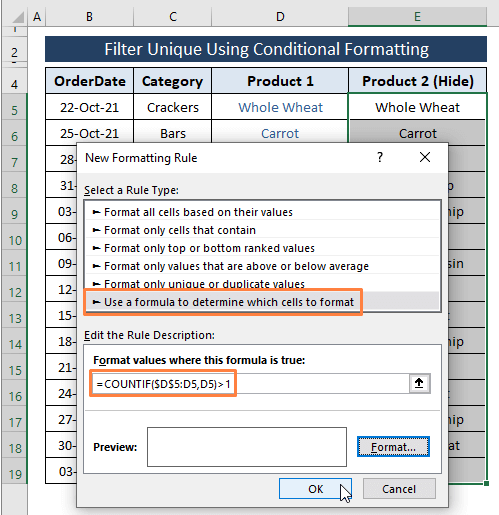
चुनें यह निर्धारित करने के लिए एक सूत्र का उपयोग करें कि कौन से सेल को प्रारूपित करना है एक नियम का चयन करेंटाइप करें विकल्प।
नियम विवरण संपादित करें विकल्प के तहत निम्न सूत्र टाइप करें।
=COUNTIF($D$5:D5,D5)=1 सूत्र में, हमने एक्सेल को D कॉलम में प्रत्येक सेल को Unique (यानी, 1 के बराबर) के रूप में गिनने का निर्देश दिया। यदि प्रविष्टियाँ लगाई गई शर्त से मेल खाती हैं तो यह TRUE और रंग स्वरूप सेल लौटाती हैं।
प्रारूप पर क्लिक करें।
<0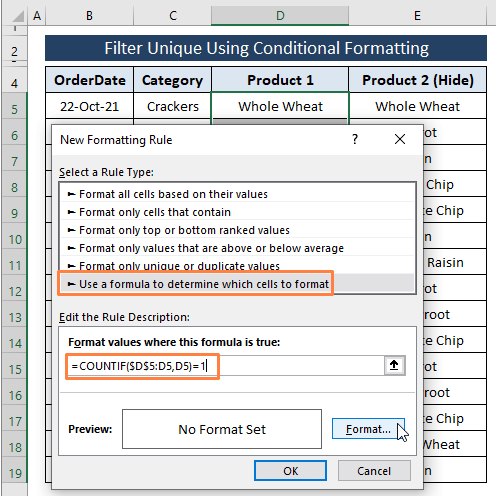
चरण 3: एक क्षण में, प्रारूप कक्ष विंडो प्रकट होती है। फ़ॉर्मेट सेल विंडो में,
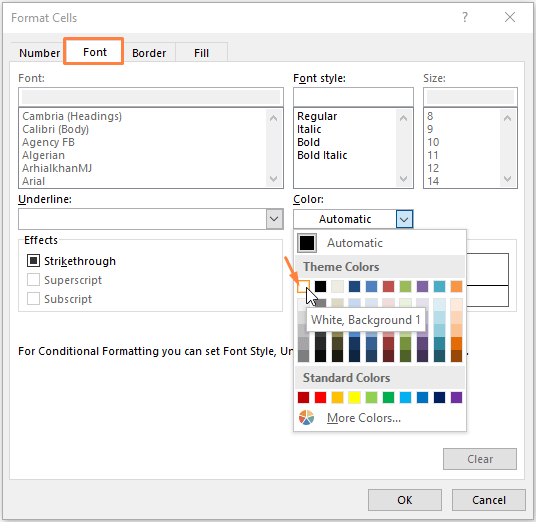
फ़ॉन्ट सेक्शन में- नीचे दी गई छवि में दर्शाए अनुसार किसी भी फ़ॉर्मेटिंग रंग का चयन करें।
फिर <6 पर क्लिक करें>ठीक ।
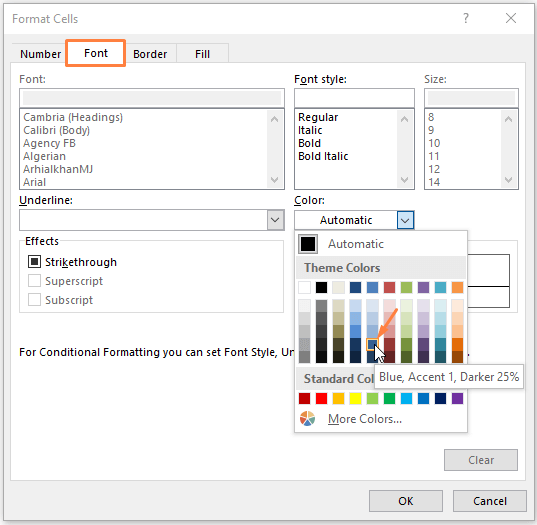
चरण 4: पिछले चरण में ठीक क्लिक करने से आप नए पर पहुंच जाते हैं स्वरूपण नियम विंडो फिर से। नए फ़ॉर्मेटिंग नियम विंडो में, आप अद्वितीय प्रविष्टियों का पूर्वावलोकन देख सकते हैं।
ठीक क्लिक करें।
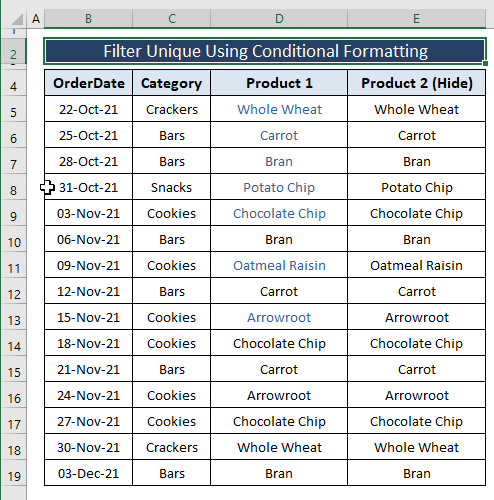
अंत में, आपको अद्वितीय प्रविष्टियों का रंग स्वरूपित मिलता है जैसा कि आप उन्हें नीचे दी गई तस्वीर के समान चाहते हैं।
2.2। डुप्लिकेट को छिपाने के लिए सशर्त स्वरूपण
अद्वितीय मानों में हस्तक्षेप किए बिना, हम सशर्त स्वरूपण का उपयोग करके डुप्लिकेट मानों को आसानी से छुपा सकते हैं। डुप्लीकेट को छिपाने के लिए, हमें उसी फॉर्मूले को लागू करना होगा जैसा हमने यूनीक को फ़िल्टर करने के लिए किया था सिवाय इसके कि उन्हें 1 से बड़े मान पर असाइन किया जाए। सफ़ेद फ़ॉन्ट रंग का चयन करने के बाद, हम उन्हें बाकी प्रविष्टियों से छुपा सकते हैं।
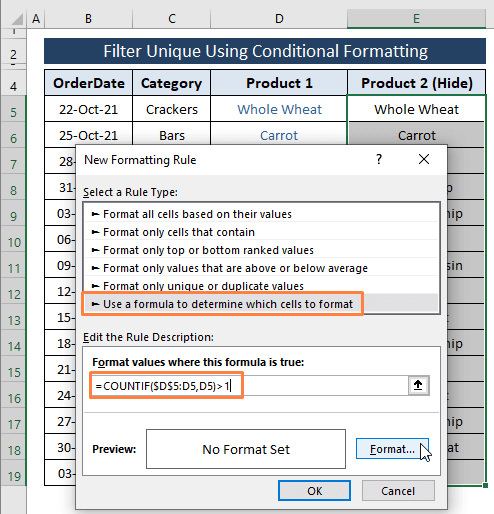
चरण1: दोहराएँ चरण 1 से 2 विधि 2.1 लेकिन नीचे दिए गए सूत्र के साथ सम्मिलित सूत्र को बदलें।
=COUNTIF($D$5:D5,D5)>1 सूत्र एक्सेल को D कॉलम में प्रत्येक सेल को डुप्लिकेट (यानी, 1 से अधिक) के रूप में गिनने का निर्देश देता है। यदि प्रविष्टियाँ अधिरोपित शर्त से मेल खाती हैं तो यह TRUE और रंग स्वरूप (अर्थात, छिपाएँ ) सेल लौटाती हैं।
<6 पर क्लिक करें>फॉर्मेट ।
स्टेप 2: फॉर्मेट पर क्लिक करने से आप फॉर्मेट सेल विंडो पर पहुंच जाते हैं। फ़ॉर्मेट सेल विंडो में,
फ़ॉन्ट रंग सफ़ेद चुनें.
फिर ठीक क्लिक करें .
चरण 3: फ़ॉन्ट रंग चुनने के बाद, ठीक पर क्लिक करने से आप <पर होवर हो जाते हैं 6>नया फ़ॉर्मेटिंग नियम फिर से विंडो। आप पूर्वावलोकन को धूमिल के रूप में देख सकते हैं क्योंकि हम सफेद को फ़ॉन्ट रंग के रूप में चुनते हैं।
ठीक क्लिक करें।
सभी चरणों का पालन करने से आप डुप्लीकेट मानों के लिए नीचे दी गई छवि के समान चित्रण पर पहुंच जाते हैं।
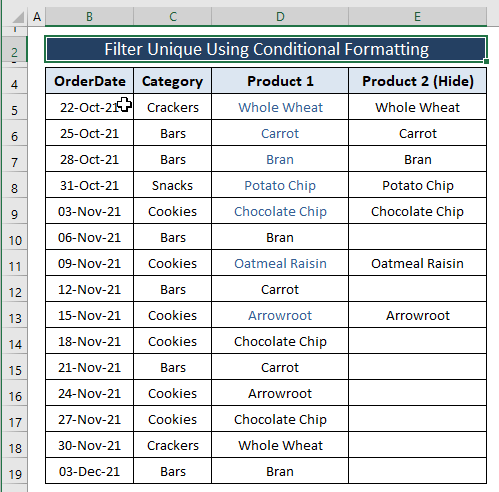
आपको सफ़ेद<का चयन करना होगा 7> फ़ॉन्ट रंग के रूप में अन्यथा डुप्लिकेट प्रविष्टियां छिपी नहीं रहेंगी।
और पढ़ें: सूत्र का उपयोग करके एक्सेल में डेटा कैसे फ़िल्टर करें
विधि 3: अद्वितीय मानों को फ़िल्टर करने के लिए डेटा टैब उन्नत फ़िल्टर सुविधा का उपयोग करना
पहले के तरीके अद्वितीय फ़िल्टर करने के लिए डेटासेट से प्रविष्टियों को हटाते या हटाते हैं। जब हम कुछ डेटासेट पर काम करते हैं तो यह काफी खतरनाक होता है। ऐसी स्थितियाँ हो सकती हैं जहाँ हम नहीं कर सकतेअपरिष्कृत डेटासेट को बदलें, उन मामलों में हम वांछित स्थिति में अद्वितीय फ़िल्टर करने के लिए उन्नत फ़िल्टर विकल्प का उपयोग कर सकते हैं।
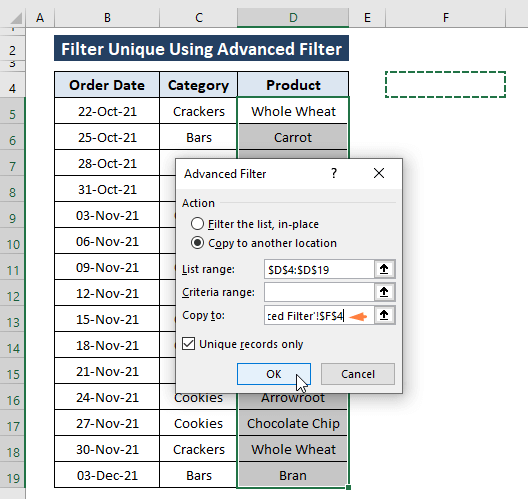
चरण 1: श्रेणी का चयन करें (यानी, उत्पाद कॉलम)। इसके बाद डेटा Tab > उन्नत चुनें ( सॉर्ट और फ़िल्टर अनुभाग से)।
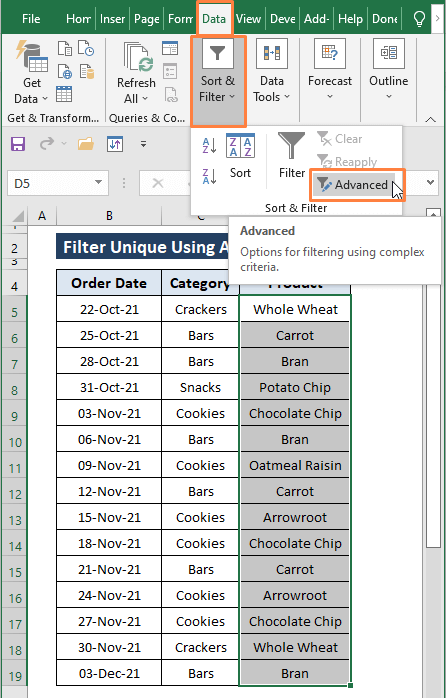
चरण 2: उन्नत फ़िल्टर विंडो प्रकट होती है। उन्नत फ़िल्टर विंडो में,
कार्रवाई विकल्प के तहत दूसरे स्थान पर कॉपी करें कार्रवाई चुनें। आप या तो चुन सकते हैं सूची को इन-प्लेस फ़िल्टर करें, या किसी अन्य स्थान पर कॉपी करें हालांकि, कच्चे डेटा में बदलाव न करने के लिए हम बाद वाले को चुन रहे हैं।
इसमें कॉपी करें विकल्प में एक स्थान निर्दिष्ट करें (अर्थात, F4 )। 0> ओके क्लिक करें।
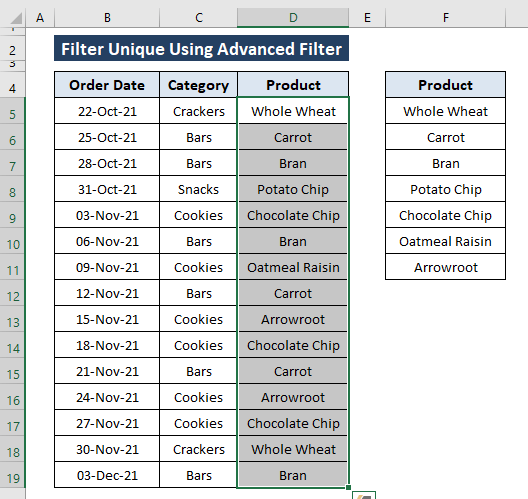
ओके क्लिक करने से आपको नियत स्थान में अद्वितीय मान मिलते हैं जैसा कि चरणों में निर्देशित किया गया है।
विधि 4: एक्सेल UNIQUE फ़ंक्शन का उपयोग करके अद्वितीय मानों को फ़िल्टर करें
दूसरे कॉलम में अद्वितीय मानों को प्रदर्शित करना भी <6 द्वारा प्राप्त किया जा सकता है> अद्वितीय समारोह। अद्वितीय फ़ंक्शन किसी श्रेणी या सरणी से अद्वितीय प्रविष्टियों की सूची प्राप्त करता है। UNIQUE फंक्शन का सिंटैक्स है
UNIQUE (array, [by_col], [exactly_once])
द आर्गुमेंट्स,
सरणी ; रेंज, या सरणी जहां से अद्वितीय मान निकाले जाते हैं।
[by_col] ; पंक्ति = FALSE ( डिफ़ॉल्ट ) द्वारा मानों की तुलना करने और निकालने के तरीकेऔर कॉलम = TRUE द्वारा। [वैकल्पिक]
[बिल्कुल_एक बार] ; एक बार होने वाले मान = TRUE और मौजूदा अनन्य मान = FALSE ( डिफ़ॉल्ट द्वारा)। [वैकल्पिक]
चरण 1: किसी भी खाली सेल में निम्न सूत्र टाइप करें (यानी, E5 )।
=UNIQUE(D5:D19) 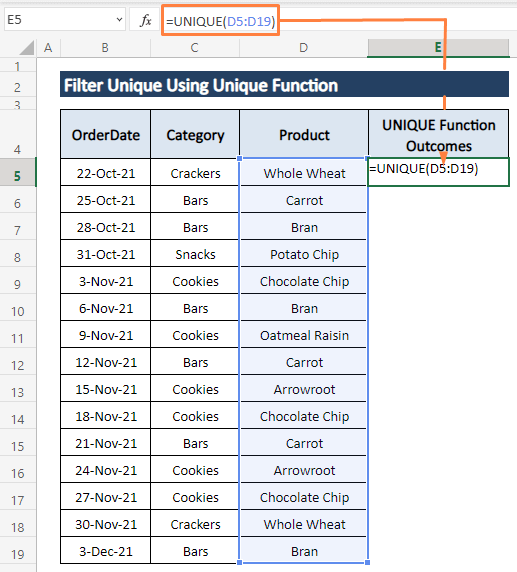
चरण 2: ENTER दबाएं फिर एक सेकंड में सभी अनूठी प्रविष्टियां नीचे दी गई तस्वीर के समान कॉलम में पॉप अप हो जाती हैं।
<32
UNIQUE फ़ंक्शन एक बार में सभी अद्वितीय प्रविष्टियों को फैला देता है। हालांकि, एक्सेल 365 वर्जन के अलावा आप यूनिक फंक्शन का इस्तेमाल नहीं कर सकते।
समान रीडिंग
- <34 सेल वैल्यू के आधार पर एक्सेल फ़िल्टर डेटा (6 कुशल तरीके)
- एक्सेल में फ़िल्टर कैसे जोड़ें (4 तरीके)
- एक्सेल फ़िल्टर के लिए शॉर्टकट (उदाहरण के साथ 3 त्वरित उपयोग)
- एक्सेल में टेक्स्ट फ़िल्टर का उपयोग कैसे करें (5 उदाहरण)
विधि 5: UNIQUE और FILTER फ़ंक्शंस (मापदंडों के साथ) का उपयोग करना
विधि 4 में, हम UNIQUE फ़ंक्शन का उपयोग अद्वितीय मानों को फैलाने के लिए करते हैं। क्या होगा यदि हम शर्त के आधार पर अद्वितीय प्रविष्टियां चाहते हैं? मान लें कि हम अपने डेटासेट से उत्पाद एक निश्चित श्रेणी के नाम चाहते हैं।
इस मामले में, हम अद्वितीय उत्पाद के नाम चाहते हैं हमारे डेटासेट से बार्स (यानी, E4 ) श्रेणी।
चरण 1: नीचे दिए गए सूत्र को किसी भी सेल में लिखें (यानी, E5 ).
=UNIQUE(FILTER(D5:D19,C5:C19=E4)) दसूत्र D5:D19 श्रेणी को फ़िल्टर करने का निर्देश देता है, श्रेणी C5:C19 पर एक शर्त लगाता है कि यह सेल E4 के बराबर हो।
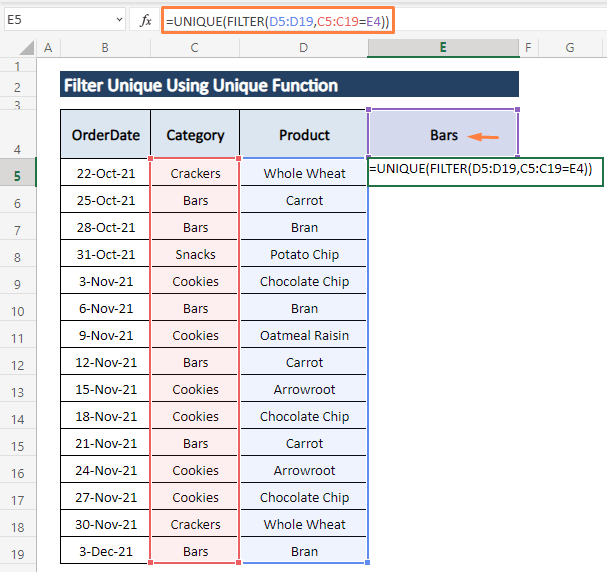
चरण 2: ENTER दबाएं। उसके बाद बार्स श्रेणी के अंतर्गत उत्पाद, बार्स कॉलम के कक्षों में दिखाई देते हैं जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
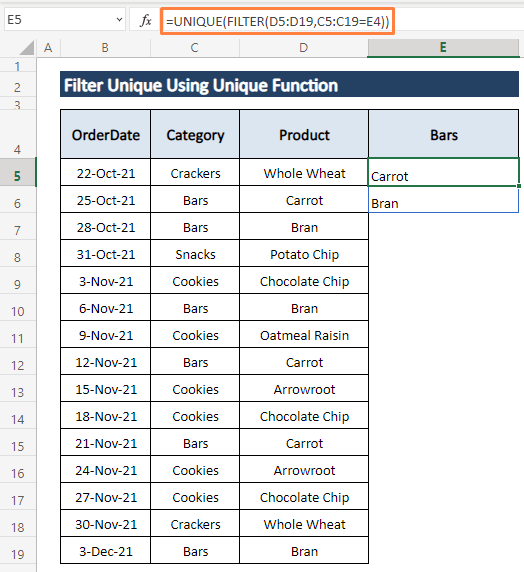
आप अद्वितीय उत्पादों को फ़िल्टर करने के लिए कोई भी श्रेणी चुन सकते हैं। विशाल बिक्री डेटासेट को संभालने का यह काफी प्रभावी तरीका है। FILTER फ़ंक्शन केवल Excel 365 में उपलब्ध है।
और पढ़ें: Excel में एकाधिक मानदंड फ़िल्टर करें <1
विधि 6: MATCH और INDEX फ़ंक्शंस (ऐरे फ़ॉर्मूला) का उपयोग करना
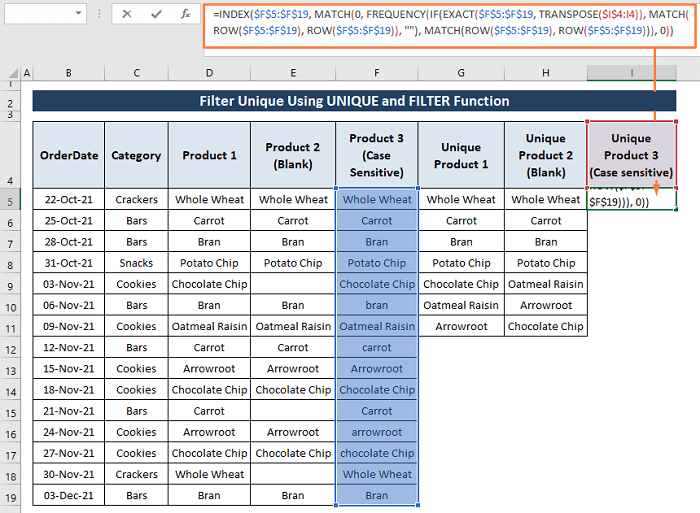
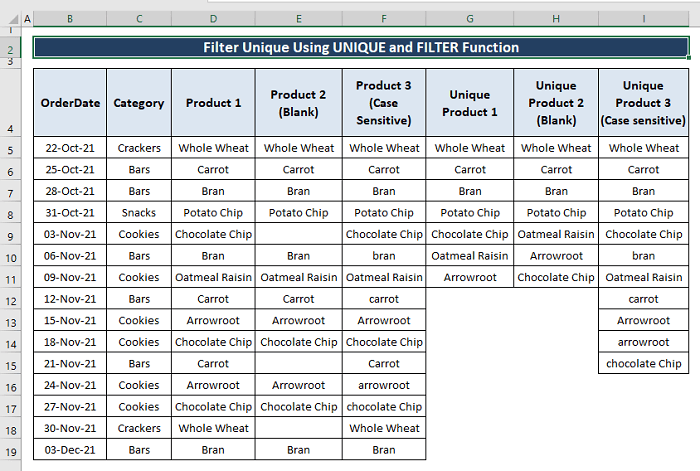
सरल प्रदर्शन के लिए, हम बिना किसी रिक्त या केस-संवेदी प्रविष्टियों वाले डेटासेट का उपयोग करते हैं। तो, हम ऐसे डेटासेट को कैसे संभाल सकते हैं जिसमें रिक्त स्थान और केस-संवेदी प्रविष्टियाँ हों? कोई रास्ता दिखाने से पहले, आइए एक संयुक्त सूत्र का उपयोग करके गैर-रिक्त श्रेणी (यानी, उत्पाद 1 ) को फ़िल्टर करें। इस मामले में, हम अद्वितीय फ़िल्टर करने के लिए MATCH और INDEX फ़ंक्शन का उपयोग करते हैं।
6.1। MATCH और INDEX फ़ंक्शंस एक गैर-रिक्त श्रेणी से अद्वितीय मानों को फ़िल्टर करते हैं
हम देख सकते हैं कि उत्पाद 1 श्रेणी में कोई मौजूदा रिक्त कक्ष नहीं हैं।
चरण 1: अद्वितीय को फ़िल्टर करने के लिए सेल G5 में निम्न सूत्र टाइप करें।
=IFERROR(INDEX($D$5:$D$19, MATCH(0, COUNTIF($G$4:G4, $D$5:$D$19), 0)),"") सूत्र द्वारा,
पहले, COUNTIF($G$4:G4, $D$5:$D$19) ; श्रेणी में कक्षों की संख्या की गणना करता है (अर्थात, $G$4:G4 ) शर्त का पालन करना (यानी, $D$5:$D$19) । COUNTIF रिटर्न 1 देता है अगर यह $G$4:G4 अन्यथा 0 रेंज में मिलता है।
दूसरा, मैच(0, COUNTIF($G$4:G4, $D$5:$D$19), 0)) ; किसी उत्पाद की सापेक्ष स्थिति श्रेणी में लौटाता है।
अंत में, INDEX($D$5:$D$19, MATCH(0, COUNTIF($G$4:G4) , $D$5:$D$19), 0)); शर्तों को पूरा करने वाली सेल प्रविष्टियां लौटाता है।
IFERROR फ़ंक्शन परिणामों में किसी भी त्रुटि को प्रदर्शित करने से सूत्र को प्रतिबंधित करता है।
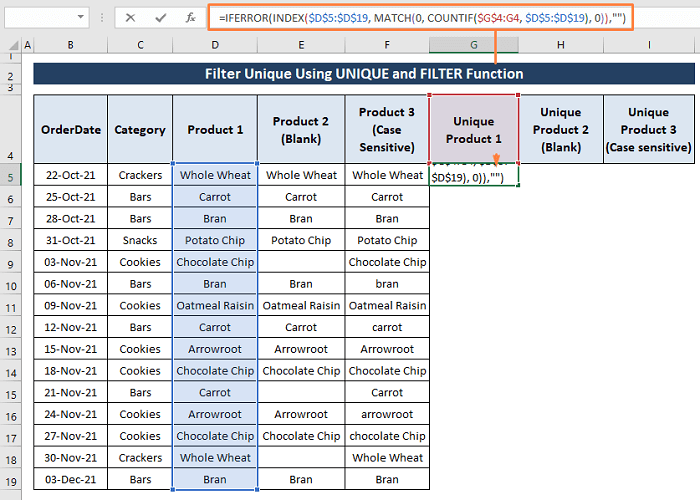
चरण 2: चूंकि सूत्र एक सरणी सूत्र है, इसलिए CTRL+SHIFT+ENTER एक साथ दबाएं. उत्पाद 1 श्रेणी से सभी अनूठी प्रविष्टियां दिखाई देती हैं।
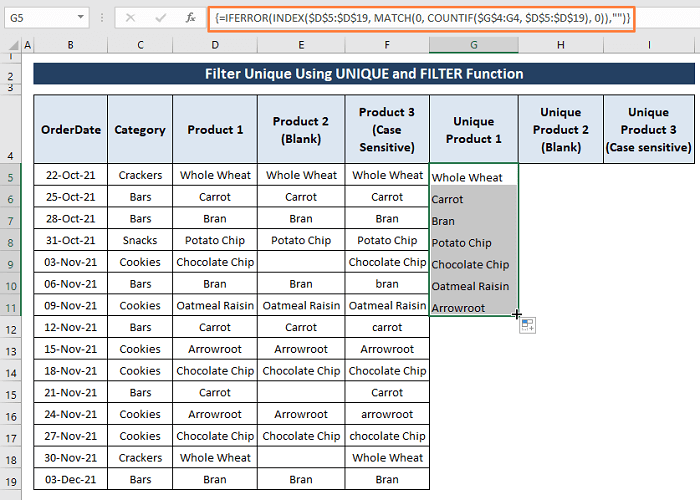
6.2। एक श्रेणी
अब, उत्पाद 2 श्रेणी में मौजूदा रिक्त कक्षों से अद्वितीय मानों को फ़िल्टर करने के लिए MATCH और INDEX फ़ंक्शन, हम कई रिक्त कक्षों को मौजूद देख सकते हैं। रिक्त कक्षों के बीच अद्वितीय को फ़िल्टर करने के लिए, हमें ISBLANK फ़ंक्शन सम्मिलित करना होगा।
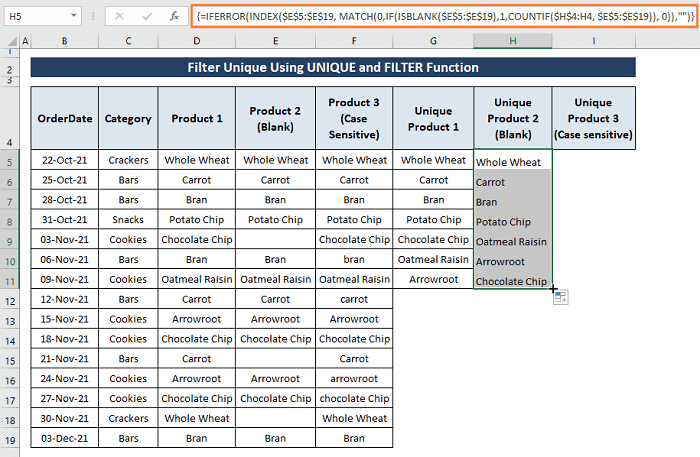
चरण 1: नीचे दिए गए सूत्र को सेल H5<में चिपकाएं 7>.
=IFERROR(INDEX($E$5:$E$19, MATCH(0,IF(ISBLANK($E$5:$E$19),1,COUNTIF($H$4:H4, $E$5:$E$19)), 0)),"") यह फ़ॉर्मूला ठीक उसी तरह काम करता है जैसा हमने 6.1 में बताया था. खंड । हालांकि, ISBLANK फ़ंक्शन के तार्किक परीक्षण के साथ अतिरिक्त IF फ़ंक्शन सूत्र को श्रेणी में किसी भी रिक्त कक्षों को अनदेखा करने में सक्षम बनाता है।
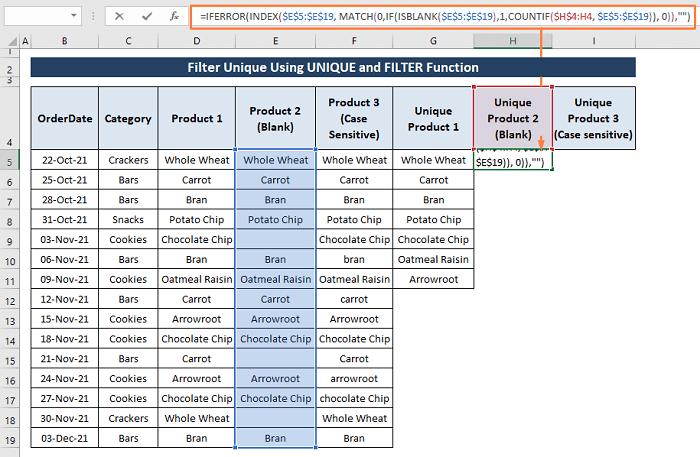
चरण 2: CTRL+SHIFT+ENTER हिट करें और सूत्र रिक्त कक्षों पर ध्यान नहीं देता और सभी अद्वितीय प्रविष्टियां प्राप्त करता हैजैसा कि निम्नलिखित चित्र में दिखाया गया है।
6.3। केस-संवेदी श्रेणी से अद्वितीय मानों को फ़िल्टर करने के लिए MATCH और INDEX फ़ंक्शंस
यदि हमारे डेटासेट में केस-संवेदी प्रविष्टियाँ हैं, तो हमें FREQUENCY फ़ंक्शन का उपयोग <6 के साथ करना होगा>TRANSPOSE और ROW अद्वितीय को फ़िल्टर करने के लिए कार्य करता है।
चरण 1: नीचे दिए गए सूत्र को सेल I5 में लागू करें।
=INDEX($F$5:$F$19, MATCH(0, FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19))), 0)) सूत्र के अनुभाग,
- TRANSPOSE($I$4:I4); अर्धविराम को अल्पविराम में परिवर्तित करके पिछले मानों को स्थानांतरित करें। ( यानी, TRANSPOSE({"unique Values (केस सेंसिटिव)";Whole Wheat"}) बन जाता है {"unique Values (केस सेंसिटिव)"," होल व्हीट”
- EXACT($F$5:$F$19, TRANSPOSE($I$4:I4); जांचें कि स्ट्रिंग्स समान और केस-संवेदी हैं या नहीं।<35
- IF(EXACT($F$5:$F$19, TRANSPOSE($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F) $19)); सरणी में एक स्ट्रिंग की सापेक्ष स्थिति देता है यदि TRUE .
- FREQUENCY(IF(EXACT($F$5:$F$19, TRANSPOSE) ($I$4:I4)), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), “”) ; गणना करता है कि स्ट्रिंग कितनी बार मौजूद है सरणी। $19), ROW($F$5:$F$19)), ""), MATCH(ROW($F$5:$F$19), ROW($F$5:$F$19)), 0)) ; सरणी में पहले गलत (यानी, खाली ) मान पाता है।
- INDEX($F$5:$F$19, MATCH(0, FREQUENCY(IF(EXACT)) $F$5:$F$19,
