
Სარჩევი
რამდენად კარგი იქნება თუ უჯრედები ავტომატურად ივსება? უმეტეს შემთხვევაში ჩვენ ეს გვიყვარს. დღეს ჩვენ ვაპირებთ გაჩვენოთ, თუ როგორ ავტომატური შევსება უჯრედები Excel-ში სხვა უჯრედის მნიშვნელობის მიხედვით. ამ სესიისთვის ჩვენ ვაპირებთ გამოვიყენოთ Excel 2019. მოგერიდებათ გამოიყენოთ თქვენი სასურველი ვერსია.
პირველ რიგში, მოდით გავეცნოთ მონაცემთა ბაზას, რომელიც არის ჩვენი დღევანდელი მაგალითების საფუძველი.
0> 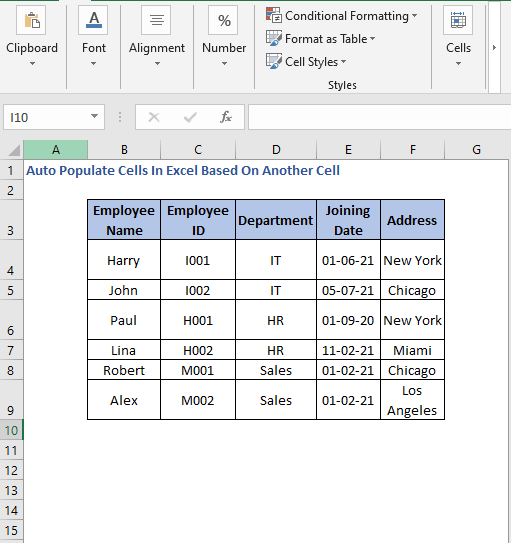
აქ გვაქვს ცხრილი, რომელიც შეიცავს თანამშრომლების ინფორმაციას, როგორიცაა მათი სახელი, პირადობის მოწმობა, მისამართი, შესაბამისი დეპარტამენტი და გაწევრიანების თარიღი. ამ მონაცემების გამოყენებით ჩვენ დავინახავთ, როგორ შევავსოთ უჯრედები ავტომატურად.
გაითვალისწინეთ, რომ ეს არის ძირითადი მონაცემთა ნაკრები მოტყუებული მონაცემებით. რეალურ სცენარში შეიძლება შეგხვდეთ ბევრად უფრო დიდი და რთული მონაცემთა ნაკრები.
სავარჯიშო სამუშაო წიგნი
მოგესალმებით, ჩამოტვირთოთ პრაქტიკის სამუშაო წიგნი ქვემოთ მოცემული ბმულიდან.
უჯრედების ავტომატური შევსება Excel-ში სხვა Cell.xlsx-ზე დაფუძნებული
უჯრედების ავტომატური შევსება სხვა უჯრედზე დაყრდნობით
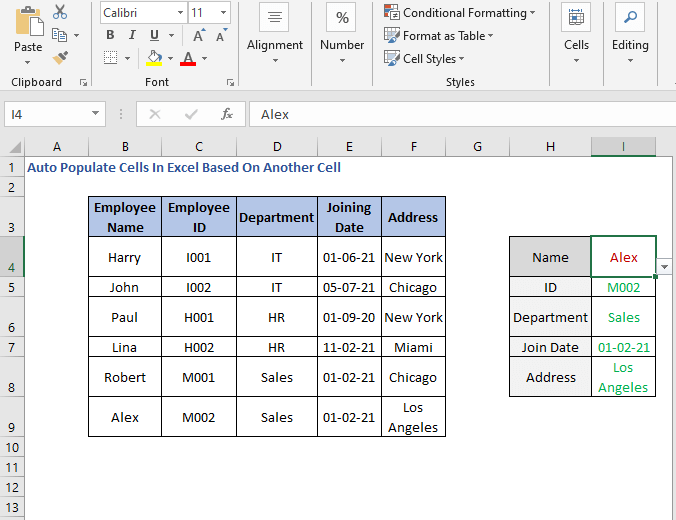
აქ ჩვენ ვაძლევთ ჩვენს მაგალითს ისე, რომ თანამშრომლის სახელის მითითებით, ჩვენ ავტომატურად ვიპოვით მის ინფორმაციას.
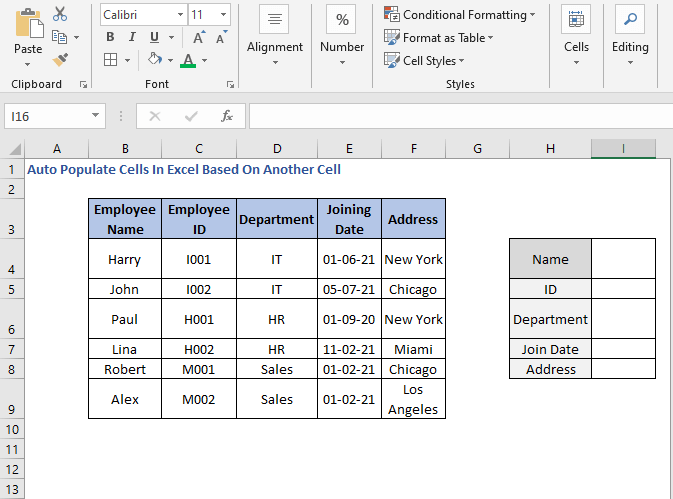
აქ შემოვიღეთ ორიგინალური ცხრილისგან გამოყოფილი ინფორმაციის ველები. ვთქვათ, დავაყენეთ Name, Robert .
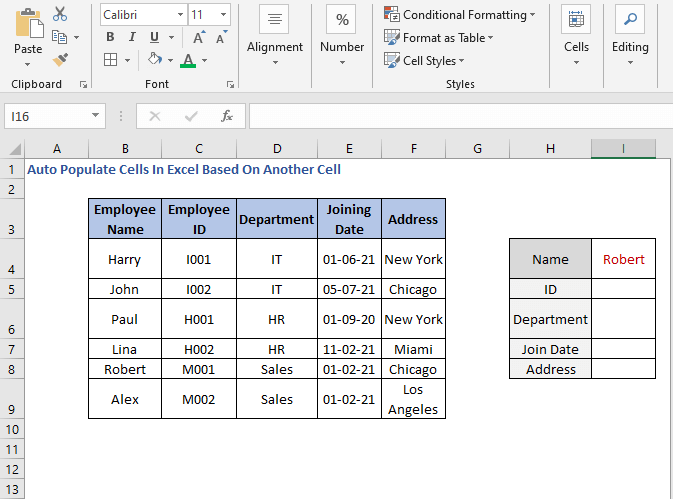
შემდეგ ჩვენ უნდა მივიღოთ Robert დეტალები. მოდით გამოვიკვლიოთ როგორ შეგვიძლია ამის გაკეთება.
1. VLOOKUP ფუნქციის გამოყენება
მხოლოდ ერთი წუთით დაივიწყეთ „ავტომატური პოპულაცია“ დაიფიქრეთ კრიტერიუმების შესაბამისი მონაცემების მოძიებაზე, რომელი ფუნქციები შემოდის თქვენს გონებაში? სავსებით აშკარაა, VLOOKUP ერთ-ერთი მათგანია.
VLOOKUP ეძებს მონაცემებს, ორგანიზებულ ვერტიკალურად. დამატებითი ინფორმაციისთვის შეამოწმეთ ეს VLOOKUP სტატია.
ახლა ჩვენ ვაპირებთ დავწეროთ ფორმულა VLOOKUP ფუნქციის გამოყენებით, რომელიც მოიტანს ზუსტ მონაცემებს, რაც ჩვენ გვინდა უჯრედში.
მოდით დავწეროთ თანამშრომლის ID-ის გამოყვანის ფორმულა
=IFERROR(VLOOKUP($I$4,$B$4:$F$9,2,0),"") 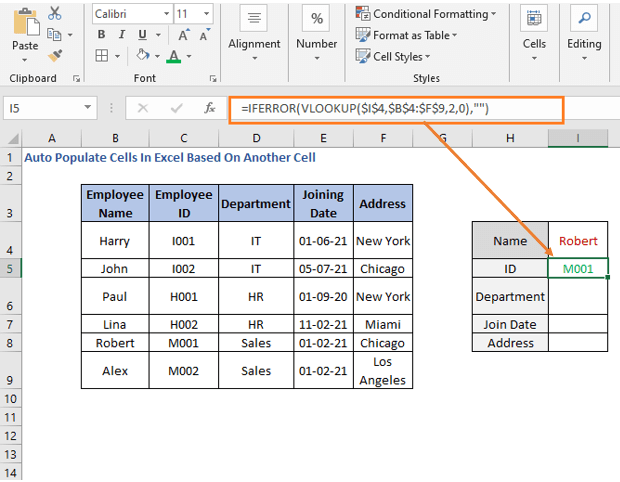
VLOOKUP <-ში 14>ფუნქციაში, ჩვენ ჩავსვით სახელი ( I4) როგორც lookup_value . შემდეგ მთელი ცხრილის დიაპაზონი, როგორც lookup_array .
Employee ID არის მე-2 სვეტი, ამიტომ ჩვენ დავაყენეთ 2 როგორც column_num .
ჩვენ გამოვიყენეთ IFERROR ფუნქცია VLOOKUP ფორმულის შესასრულებლად. ეს აღმოფხვრის ყველა შეცდომას, რომელიც წარმოიქმნება ფორმულიდან (ფუნქციის შესახებ რომ იცოდეთ, ეწვიეთ სტატიას: IFERROR).
განყოფილების სახელის გამოსატანად, ჩვენ უნდა შევცვალოთ ფორმულა,
=IFERROR(VLOOKUP($I$4,$B$4:$F$9,3,0),"") 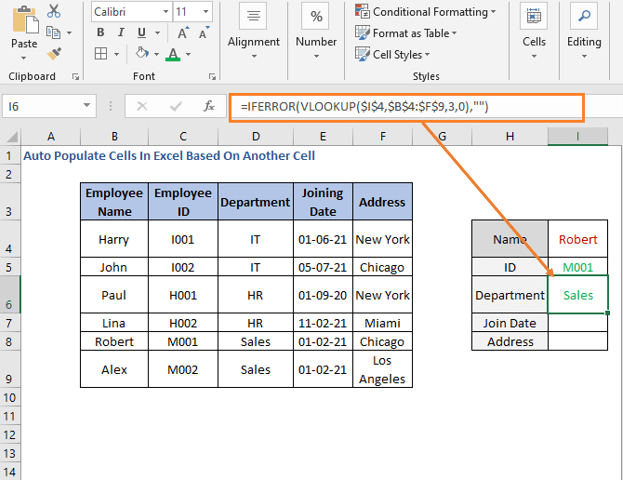
აქ ჩვენ შევცვალეთ სვეტის_რიცხვი თავდაპირველი ცხრილის პოზიციის მიხედვით. განყოფილება არის მე-3 სვეტი, ამიტომ ჩვენ გამოვიყენეთ 3.
შეერთების თარიღისთვის და მისამართისთვის, ფორმულა იქნება
=IFERROR(VLOOKUP($I$4,$B$4:$F$9,4,0),"") 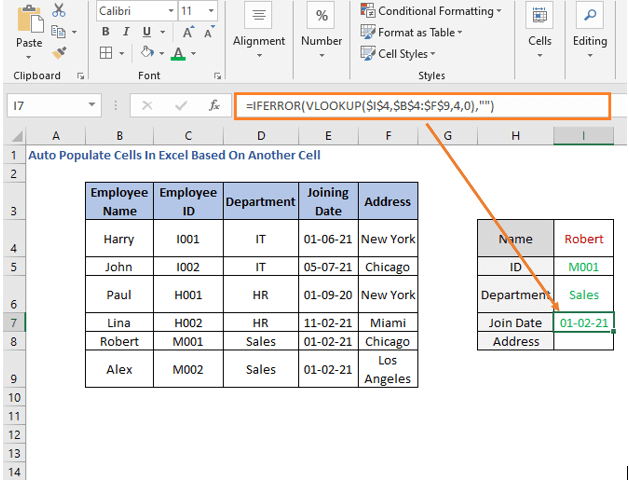
და
=IFERROR(VLOOKUP($I$4,$ B$4:$F$9,5,0)””) 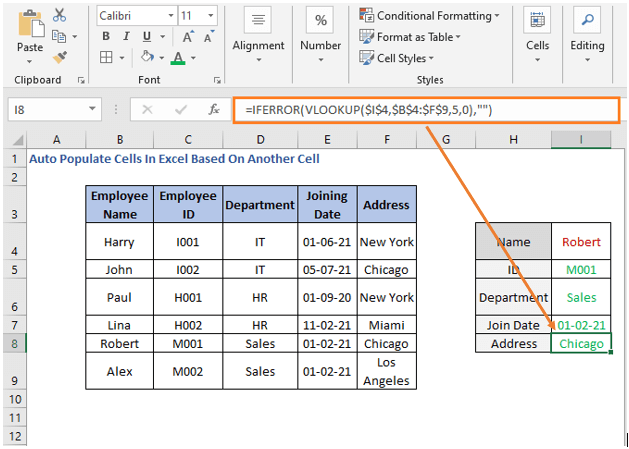
ჩვენ ვიპოვეთ დეტალებიდაქირავებული. ახლა შეცვალეთ სახელი და უჯრედები ავტომატურად განახლდება.
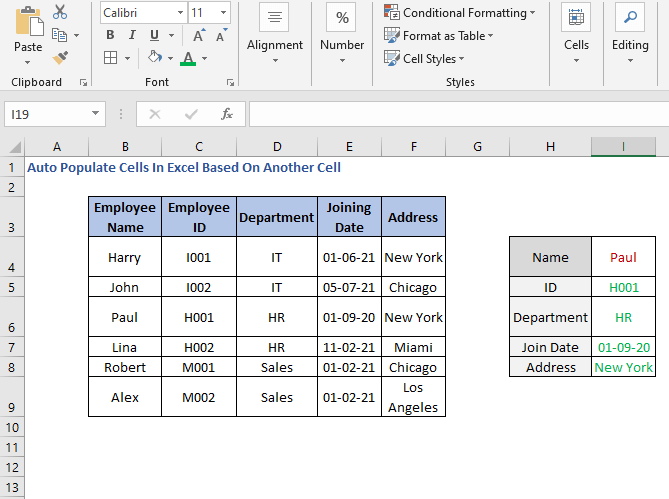
VLOOKUP ჩამოსაშლელი სიით
ადრე მივაწოდეთ სახელი ხელით. ზოგჯერ შეიძლება ჩანდეს როგორც შრომატევადი, ასევე დამაბნეველი.
ამ პრობლემის გადასაჭრელად შეგვიძლია შევქმნათ ჩამოსაშლელი სია თანამშრომლის სახელისთვის. შეამოწმეთ სტატია, რათა იცოდეთ ჩამოსაშლელი სიის შექმნის შესახებ.
მონაცემთა დადასტურება დიალოგურ ველში აირჩიეთ სია და ჩადეთ სახელების უჯრედის მითითება.
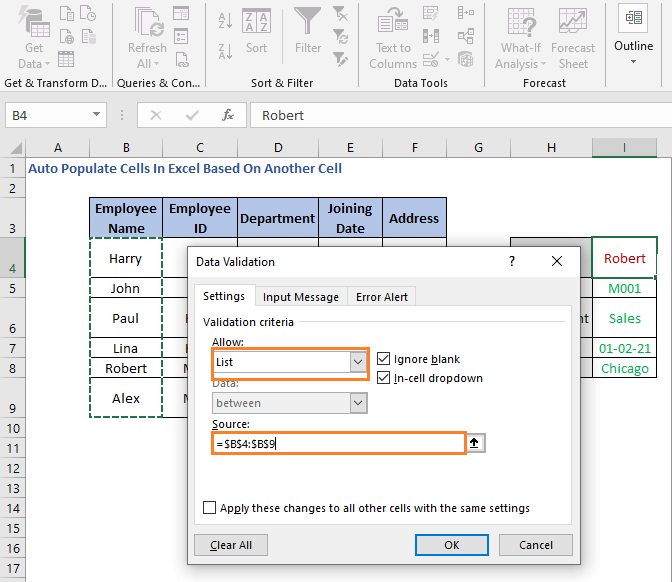
B4:B9 ეს არის დიაპაზონი, რომელიც შეიცავს სახელებს.
ახლა ჩვენ ვიპოვით ჩამოსაშლელ სიას.
<. 0>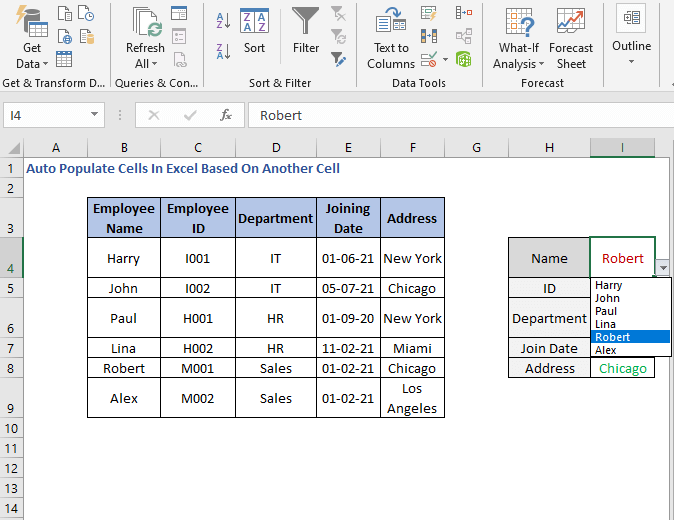
ჩვენ შეგვიძლია ავირჩიოთ სახელი უფრო ეფექტურად და სწრაფად.
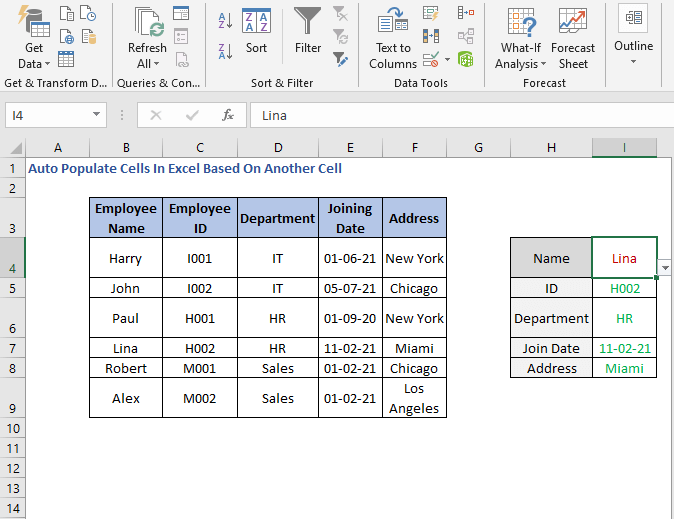
სხვა უჯრედები ავტომატურად ივსება, როგორც ვიყენებდით VLOOKUP .
2. INDEX – MATCH ფუნქციის გამოყენებით
ოპერაცია, რომელიც ჩვენ შევასრულეთ VLOOKUP -ის მეშვეობით, შეიძლება განხორციელდეს ალტერნატიულად. ჩვენ შეგვიძლია გამოვიყენოთ კომბინაცია INDEX-MATCH უჯრედების ავტომატურად დასამატებლად.
MATCH განსაზღვრავს საძიებო მნიშვნელობის პოზიციას მწკრივში, სვეტში ან ცხრილში. INDEX აბრუნებს მნიშვნელობას მოცემულ მდებარეობაზე დიაპაზონში. მეტი ინფორმაციისთვის ეწვიეთ სტატიებს: INDEX, MATCH.
ფორმულა იქნება შემდეგი
=IFERROR(INDEX($C$4:$C$9,MATCH($I$4,$B$4:$B$9,0)),"") 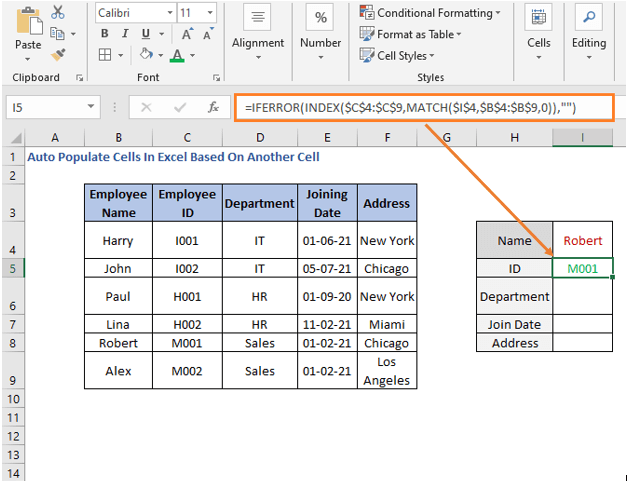
აქ ჩვენი ფორმულა იღებს ID ნომერს, ვინაიდან ჩვენ მივაწოდეთ id დიაპაზონი INDEX და MATCH ფუნქცია უზრუნველყოფს რიგის ნომერს, რომელიც შეესაბამება კრიტერიუმებსმნიშვნელობა ცხრილში ( B4:B9 ).
Department ჩვენ შევცვლით დიაპაზონს INDEX და ფორმულა იქნება იყოს შემდეგი
=IFERROR(INDEX($D$4:$D$9,MATCH($I$4,$B$4:$B$9,0)),"") 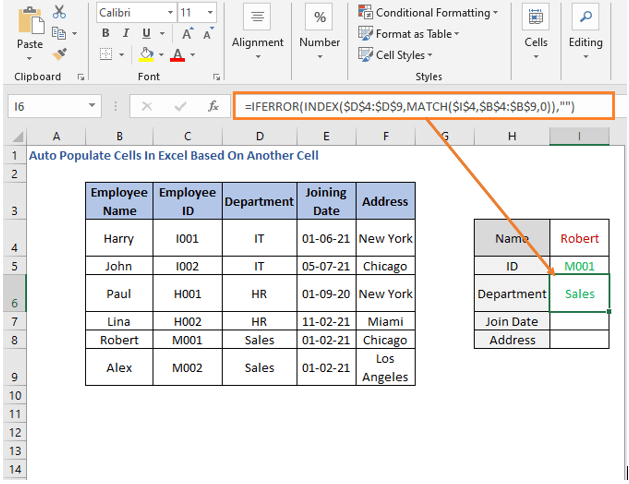
განყოფილებები არის D4 -დან D9-მდე .
ფორმულა შეერთების თარიღისთვის იქნება
=IFERROR(INDEX($E$4:$E$9,MATCH($I$4,$B$4:$B$9,0)),"") 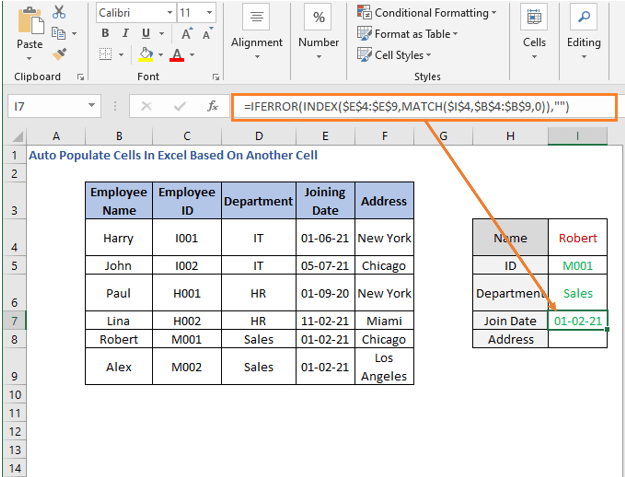
და მისამართისთვის
=IFERROR(INDEX($F$4:$F$9,MATCH($I$4,$B$4:$B$9,0)),"") 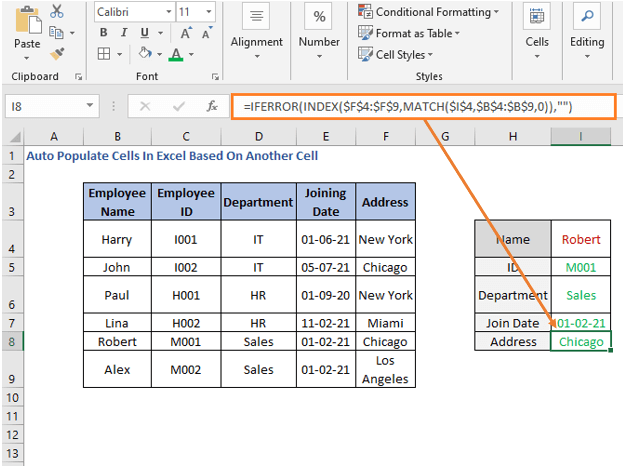
ახლა გასარკვევად, მოდით წავშალოთ არჩევანი და ავირჩიოთ რომელიმე სახელი
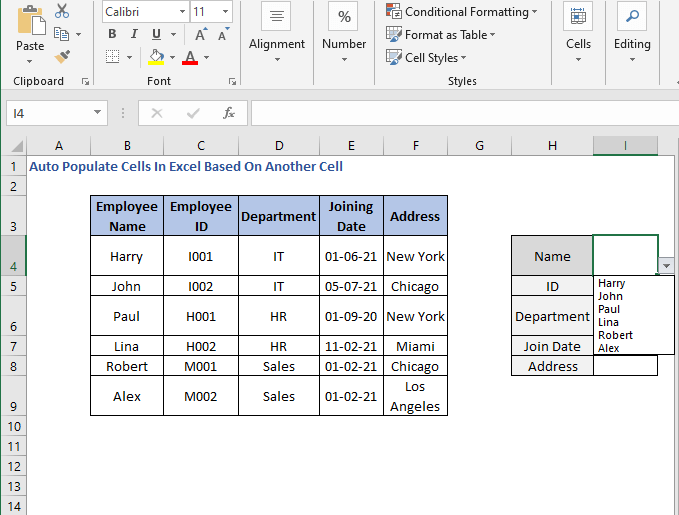
თქვენ ნახავთ, რომ სხვა უჯრედები ავტომატურად ივსება.
3. HLOOKUP ფუნქციის გამოყენება
თუ თქვენი მონაცემები ჰორიზონტალურად არის ორიენტირებული, მაშინ უნდა გამოიყენოთ HLOOKUP ფუნქცია. ფუნქციის შესახებ გასაგებად ეწვიეთ ამ სტატიას: HLOOKUP.
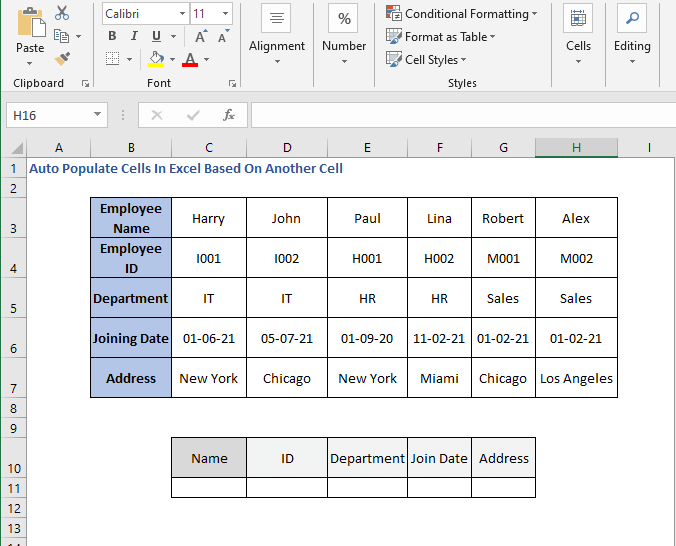
დასახელების ველი დაყენებული იქნება ჩამოსაშლელი სიიდან. და დანარჩენი ველი ავტომატურად ივსება.
ID-ის გამოსაყვანად, ჩვენ ვაპირებთ გამოვიყენოთ შემდეგი ფორმულა
=IFERROR(HLOOKUP($C$11,$C$3:$H$7,2,0),"") 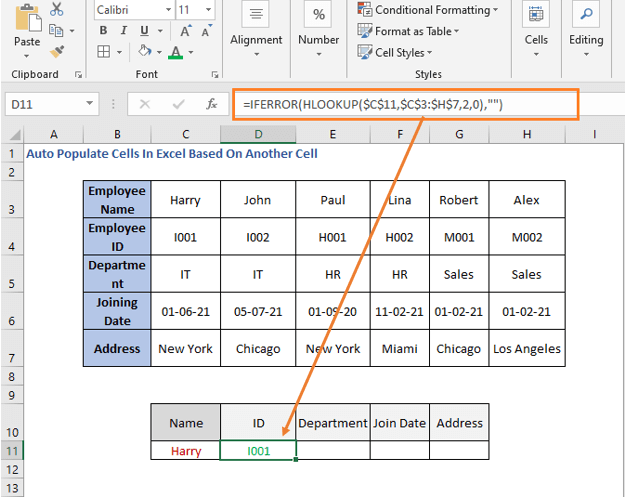
ოპერაცია მსგავსია VLOOKUP ფორმულის. HLOOKUP ფუნქციის ფარგლებში, ჩვენ მივაწოდეთ სახელი როგორც lookup_value და ცხრილი როგორც lookup_array . ID არის მე-2 რიგში, ამიტომ row_num არის 2. და 0 ზუსტი შესატყვისისთვის.
ახლა, დეპარტამენტისთვის, ფორმულა იქნება
<. 6> =IFERROR(HLOOKUP($C$11,$C$3:$H$7,3,0),"") 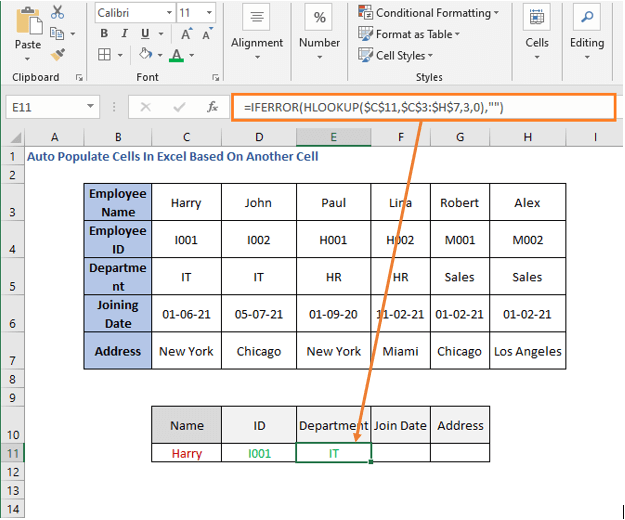
განყოფილება არის მე-3 მწკრივი, ამიტომ row_num არის 3 აქ.
მოდით დავწეროთშეერთების თარიღის ფორმულა
=IFERROR(HLOOKUP($C$11,$C$3:$H$7,4,0),"") 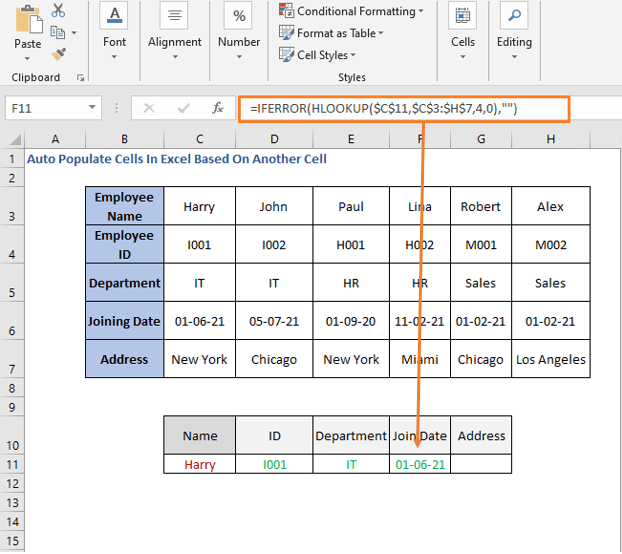
შეერთების თარიღი არის მე-4 რიგი, ამიტომ row_num არის 4 აქ. შემდეგ მისამართისთვის შეცვალეთ რიგის ნომერი 5-ით.
=IFERROR(HLOOKUP($C$11,$C$3:$H$7,5,0),"") 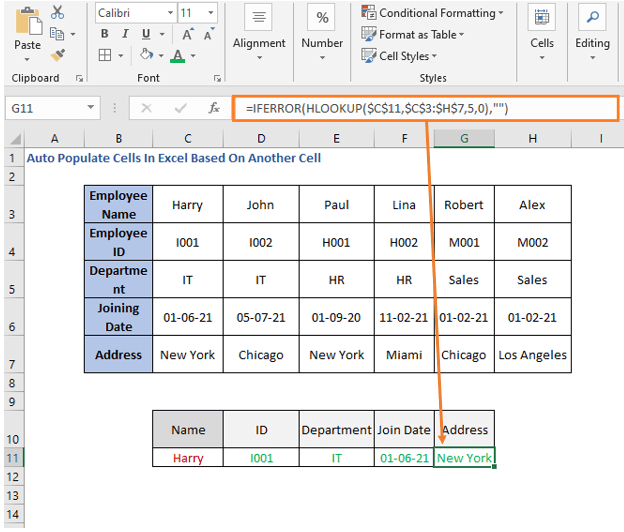
მოდით, წავშალოთ უჯრედები და ავირჩიოთ სახელი წვეთიდან -ქვემო სია
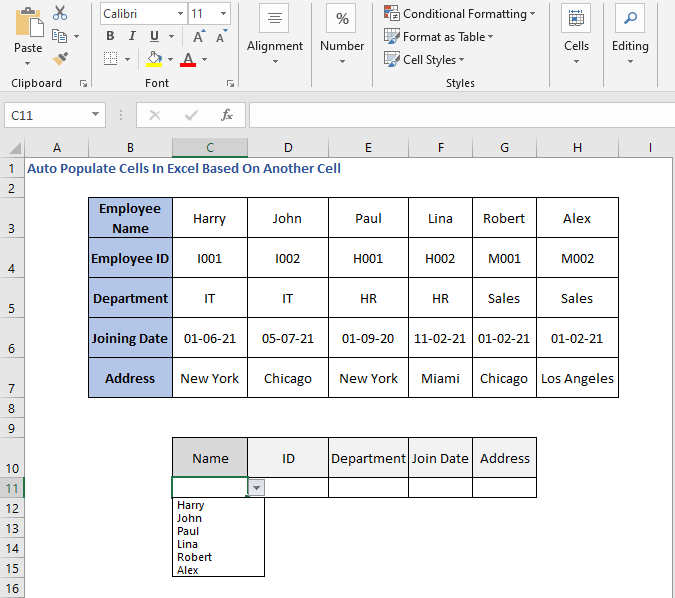
სახელის არჩევის შემდეგ ნახავთ, რომ სხვა უჯრედები ავტომატურად ივსება.
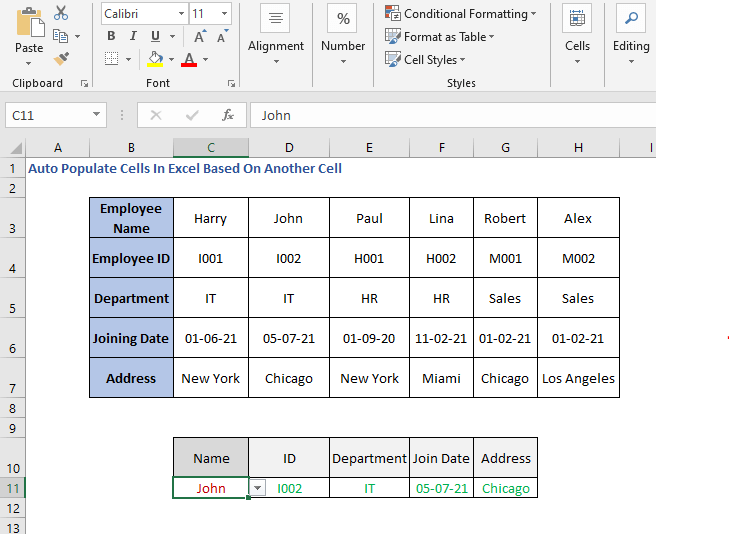
4. INDEX -MATCH რიგებისთვის
ჩვენ ასევე შეგვიძლია გამოვიყენოთ INDEX MATCH კომბინაცია მწკრივებისთვის. ფორმულა იქნება შემდეგი
=IFERROR(INDEX($C$4:$H$4,MATCH($C$11,$C$3:$H$3,0)),"") ეს არის id-ის გამოყვანისთვის, ამიტომ ჩვენ გამოვიყენეთ C4:H4 <13-ში>INDEX ფუნქცია, რომელიც არის თანამშრომლის ID მწკრივი.
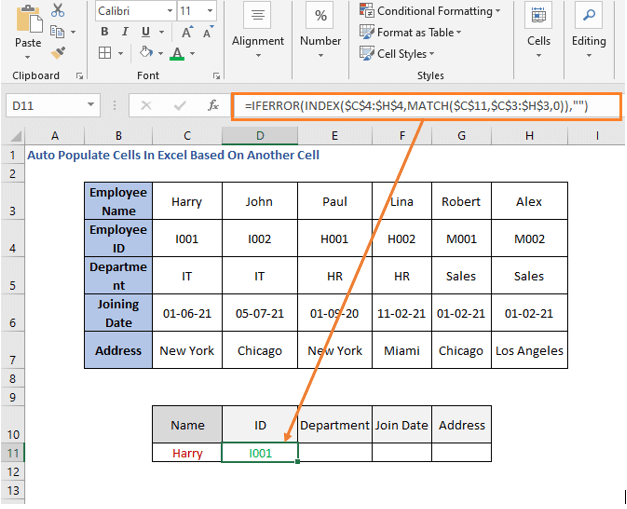
შეცვალეთ მწკრივის დიაპაზონი დეპარტამენტის საპოვნელად
=IFERROR(INDEX($C$5:$H$5,MATCH($C$11,$C$3:$H$3,0)),"") 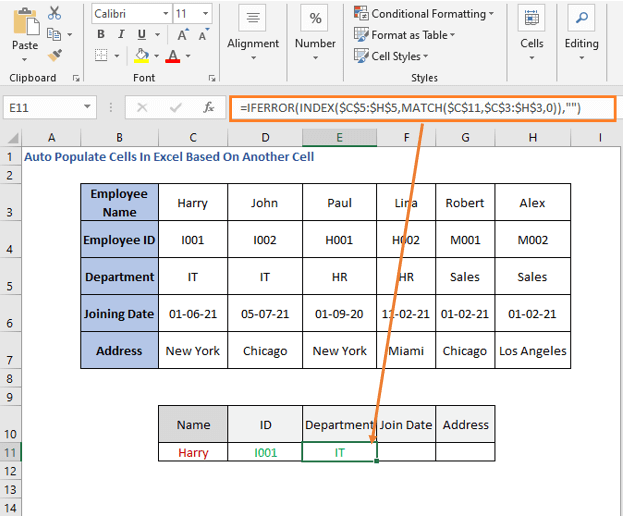
ანალოგიურად, შეცვალეთ რიგის ნომერი შეერთების თარიღისთვის და მისამართისთვის
=IFERROR(INDEX($C$6:$H$6,MATCH($C$11,$C$3:$H$3,0)),"") აქ C6:H6 არის შეერთების თარიღი რიგი.
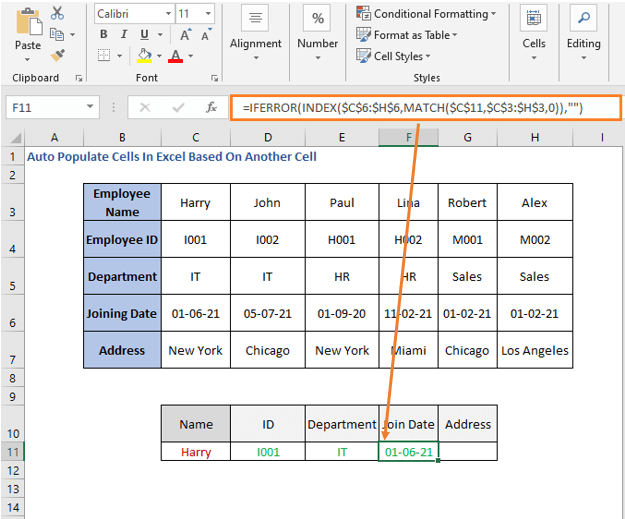
და C7:H7 არის მისამართის რიგი, ამიტომ მისამართის გამოყვანის ფორმულა იქნება ისეთი, როგორიც არის ქვემოთ მოცემული
=IFERROR(INDEX($C$7:$H$7, MATCH($C$11,$C$3:$H$3,0))””) 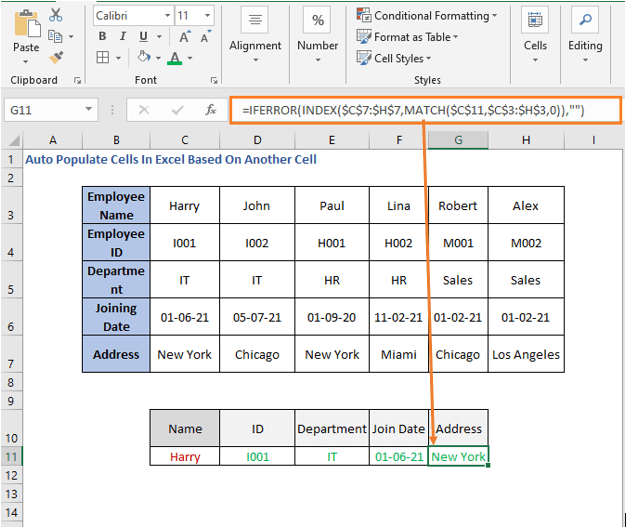
დასკვნა
დღეისთვის სულ ეს არის. ჩვენ ჩამოვთვალეთ უჯრედების ავტომატური შევსების რამდენიმე გზა სხვა უჯრედზე დაყრდნობით. იმედია ეს თქვენთვის სასარგებლო იქნება. მოგერიდებათ კომენტარის გაკეთება, თუ რაიმე რთული გასაგები გეჩვენებათ. შეგვატყობინეთ ნებისმიერი სხვა მეთოდი, რომელიც აქ გამოგვრჩა.
