
विषयसूची
बिखरे हुए डेटा बिंदुओं के लिए, आकार में बहुत बड़ा नहीं, उपयोगकर्ताओं को फैलाव की पहचान करने के लिए एक्सेल में जनसंख्या प्रसरण खोजने की आवश्यकता होती है। जनसंख्या भिन्नता का अपना पारंपरिक सूत्र है। इसके अलावा, एक्सेल VAR.P , VARP , और VARPA जनसंख्या भिन्नता खोजने के लिए कार्य प्रदान करता है।
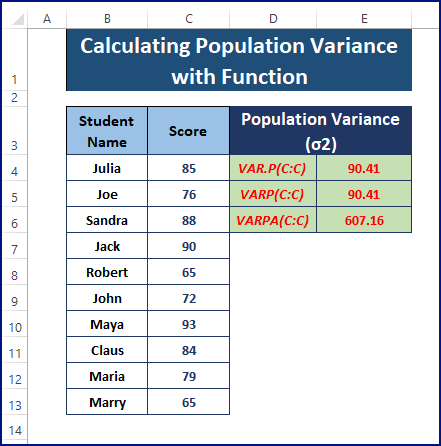
इस लेख में, हम जनसंख्या भिन्नता और एक्सेल में जनसंख्या भिन्नता खोजने के तरीकों पर चर्चा करते हैं।
एक्सेल वर्कबुक डाउनलोड करें
<7 जनसंख्या भिन्नता.xlsx
जनसंख्या भिन्नता को समझना
भिन्नता माध्य से विशेष बिंदुओं की दूरी को मापता है। यह नमूना डेटासेट के भीतर औसत मान से डेटा फैलाव को संदर्भित करने के लिए भी एक पैरामीटर है। इसलिए, विचरण जितना अधिक होगा, माध्य से डेटा बिंदुओं का फैलाव उतना ही अधिक होगा, या इसके विपरीत होगा। जनसंख्या भिन्नता उसी तरह काम करती है। यह इंगित करता है कि जनसंख्या डेटा बिंदु कितने बिखरे हुए हैं। विशाल डेटासेट के लिए, उपयोगकर्ताओं को नमूना भिन्नता अन्यथा जनसंख्या भिन्नता की गणना करने की आवश्यकता होती है।
जनसंख्या भिन्नता ( σ2) = Σ (X – µ)2 / N
यहाँ,
- X - जनसंख्या अंक .
- µ – परिकलित माध्य।
- N - जनसंख्या बिंदुओं की कुल संख्या।
एक्सेल में जनसंख्या भिन्नता खोजने के 2 आसान तरीके
एक्सेल में जनसंख्या भिन्नता खोजने के लिए निम्न विधियों में से किसी एक का पालन करें।
विधि 1: पारंपरिक का उपयोग करनाजनसंख्या भिन्नता की गणना करने का सूत्र
इस लेख में पहले, हमने जनसंख्या भिन्नता की गणना करने के लिए पारंपरिक जनसंख्या भिन्नता सूत्र का उल्लेख किया था। जनसंख्या प्रसरण का अंतत: पता लगाने के लिए उपयोगकर्ताओं को सभी आवश्यक घटकों को संकलित करने की आवश्यकता है।
- फ़ॉर्मूला घटक दर्ज करें (X - µ) , (X - µ)2 , N , कार्यपत्रक में माध्य , जनसंख्या प्रसरण ।
- बाद वाले COUNT सूत्र का उपयोग जनसंख्या बिंदुओं की कुल संख्या प्रदर्शित करने के लिए करें।
=COUNT(C:C) 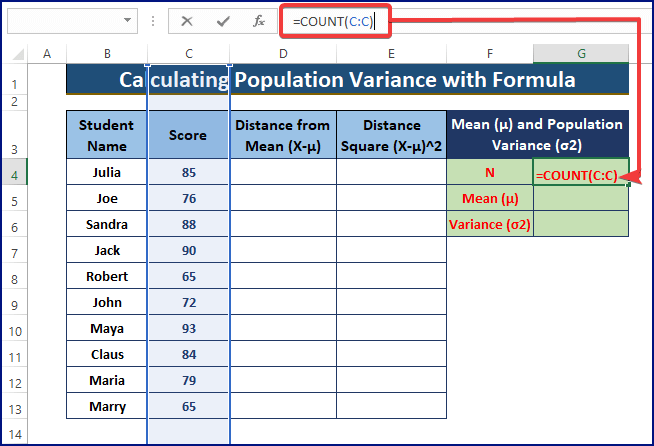
- औसत फ़ंक्शन का परिणाम माध्य<होता है 2>.
=AVERAGE(C:C) 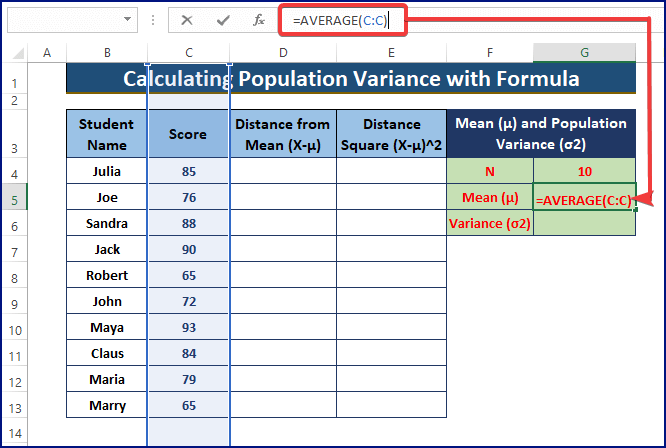
- अब, माध्य से जनसंख्या बिंदुओं की दूरी ज्ञात करें। बाद में, नीचे दी गई तस्वीर में दिखाए अनुसार दूरी को वर्ग करें।
=C4-$G$5 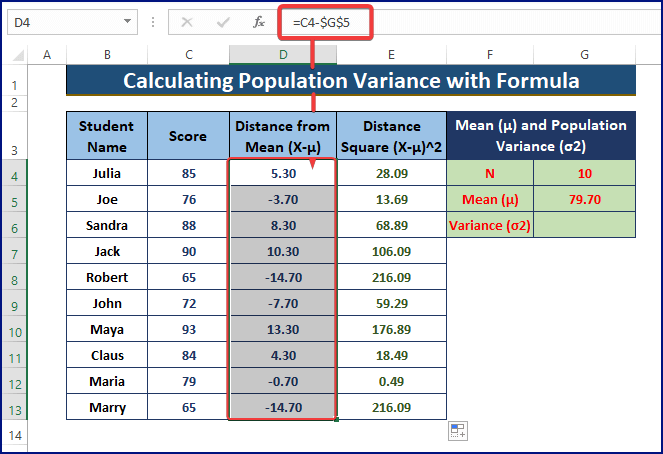
- जैसा कि जनसंख्या भिन्नता सूत्र है = Σ (X – µ)2 / N , स्तंभ E योग को N से विभाजित करें। <12
- वर्कशीट का अंतिम चित्रण नीचे दी गई छवि जैसा दिख सकता है।
=SUM(E:E)/G4 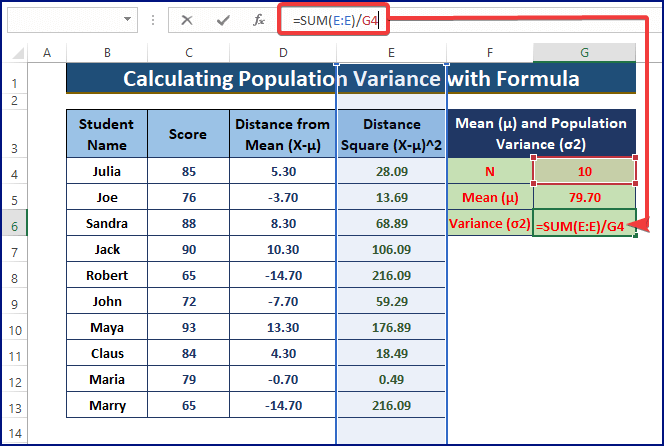

और पढ़ें: कैसे करें एक्सेल में भिन्नता विश्लेषण (त्वरित के साथचरण)
विधि 2: एक्सेल में जनसंख्या प्रसरण का पता लगाने के लिए VAR.P, VARP, या VARPA फ़ंक्शंस का उपयोग करना
Excel के 3 प्रकार प्रदान करता है VAR फ़ंक्शन जनसंख्या भिन्नता की गणना करने के लिए। वे VAR.P , VARP , और VARPA हैं।
VAR.P फ़ंक्शन एक अद्यतन संस्करण है VARP फ़ंक्शन का। 2010 के बाद के एक्सेल संस्करण इसका समर्थन करते हैं। हालांकि VARP फ़ंक्शन एक्सेल के नए संस्करणों में भी उपलब्ध है।
VAR.P(number1, [number2], …) एक्सेल संस्करण 2000 से 2019 में कार्यशील VARP फ़ंक्शन है।
VARP(number1, [number2], …) लेकिन VARPA फ़ंक्शन जनसंख्या भिन्नता पाता है नंबर , टेक्स्ट , और तार्किक मान युक्त डेटा। फ़ंक्शन एक्सेल में 2000 से सक्रिय है।
VARPA(value1, [value2], …)
- किसी भी प्रकार का उपयोग कॉलम सी की जनसंख्या भिन्नता खोजने के लिए करें .
और पढ़ें: एक्सेल में वैरियंस की गणना कैसे करें (3 सुविधाजनक तरीके) )
VAR.P, VARP, और VARPA कार्यों के बीच अंतर
चूंकि VARPA फ़ंक्शन संख्याओं के अलावा डेटा प्रकार लेता है ( यानी, टेक्स्ट और तार्किक मान भी लेता है), एक पूरे कॉलम के परिणाम को उसके समकक्ष से भिन्न मूल्य में निर्दिष्ट करता है। VAR.P और VARP कार्य समान हैं। इसलिए, उपयोगकर्ताओं को सटीक सीमा निर्दिष्ट करने की आवश्यकता होती है, यदि वे इसके अलावा डेटा को अनदेखा करना चाहते हैंnumbers.

निष्कर्ष
यह लेख जनसंख्या भिन्नता और एक्सेल में जनसंख्या भिन्नता खोजने के तरीकों पर चर्चा करता है। जनसंख्या विचरण की गणना करने के लिए उपयोगकर्ता पारंपरिक सूत्र या एक्सेल फ़ंक्शंस का उपयोग कर सकते हैं। यदि आपको और पूछताछ की आवश्यकता है या कुछ जोड़ना है तो टिप्पणी करें।
हमारी शानदार वेबसाइट, ExcelWIKI देखें। एक्सेल और इसके मुद्दों के बारे में सैकड़ों लेख हैं।
