
सामग्री सारणी
या लेखात, मी एक्सेलमधील दोन डेटा सेटच्या सांख्यिकीय तुलनाबद्दल चर्चा करेन. काही वेळा, स्प्रेडशीटवर काम करताना, आम्हाला डेटाची सांख्यिकीयदृष्ट्या तुलना करावी लागते. सुदैवाने, डेटा संचांमध्ये तुलना करण्यासाठी एक्सेलमध्ये काही इनबिल्ट फंक्शन्स आहेत.
सराव वर्कबुक डाउनलोड करा
आम्ही हे तयार करण्यासाठी वापरलेले सराव वर्कबुक तुम्ही डाउनलोड करू शकता. लेख.
दोन डेटा सेटची सांख्यिकीय तुलना.xlsx
एक्सेलमधील दोन डेटा संचांची सांख्यिकीय तुलना करण्यासाठी मुख्य पद्धत <5
दोन डेटा संचांची एक्सेल सांख्यिकीय तुलना परिचय
आमच्या उदाहरणात, आम्ही स्टील-कट ओट्स आणि रोल्ड ओट्सचे दोन मासिक विक्री डेटा संच वापरू. एक्सेलद्वारे सांख्यिकीय तुलना करून, आम्ही या दोन प्रकारच्या ओट्सची विक्री कालांतराने कशी बदलते हे शोधून काढू. त्याशिवाय, आम्ही विक्री ग्राफिकली देखील दर्शवू. शिवाय, आमच्या सांख्यिकीय तुलना सुलभतेसाठी, आम्ही प्रथम मीन, मानक विचलन, भिन्नतेचे गुणांक आणि स्टील-कट ओट्ससाठी श्रेणी ( C5:C11 ) शोधू.

स्टेप्स :
- सुरुवातीला, स्टील कट ओट्सचे मीन मिळवण्यासाठी, खालील सूत्र सेल C12 मध्ये टाइप करा. .
=AVERAGE(C5:C11) 
येथे, AVERAGE फंक्शन अंकगणितीय सरासरी मिळवते डेटासेटचे C5:C11 .
- पुढे, आम्ही डेटासेटचे मानक विचलन शोधू C5:C11 . तर, खालील टाइप करा सेल C13 मधील सूत्र.
=STDEV.S(C5:C11) 
येथे, STDEV. S फंक्शन नमुन्याच्या आधारे मानक विचलनाचा अंदाज लावते (नमुन्यातील तार्किक मूल्ये आणि मजकूराकडे दुर्लक्ष करते)
- मग, आम्ही डेटासेटच्या भिन्नतेच्या गुणांकाची गणना करू ( C5:C11 ). CV ची गणना करण्याचे सूत्र आहे:
(मानक विचलन/मीन)*100
- तर, वरील समीकरण लक्षात घेऊन, खालील टाइप करा. स्टील कट ओट्सची विक्री मिळविण्यासाठी फॉर्म्युला:
=C13/C12 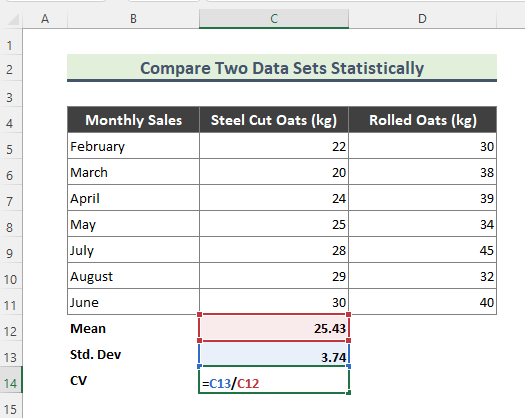
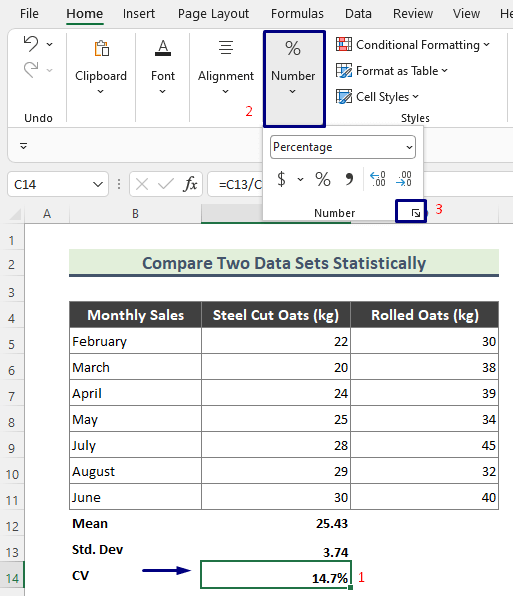
- तथापि, खात्री करा की तुम्ही टक्केवारीत सीव्हीची गणना करा. ते करण्यासाठी, संबंधित सेल निवडा ( C14 ), Home > नंबर वर जा.
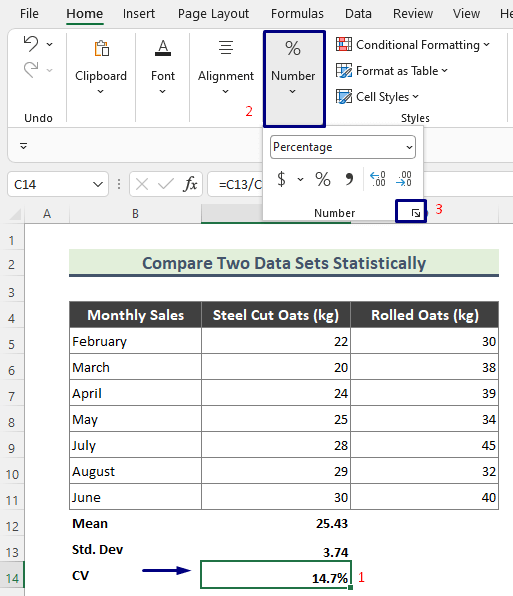
- आता मूल्य 1 दशांश ठिकाणी ठेवण्याचा प्रयत्न करा आणि ठीक आहे दाबा.
- त्यानंतर, आम्ही डेटा सेटच्या श्रेणीची गणना करू ( C5:C11 ). वर नमूद केलेल्या डेटा सेटच्या श्रेणीची गणना करण्यासाठी, येथे आमचे सूत्र आहे:
=MAX(C5:C11)-MIN(C5:C11) 
MAX फंक्शन डेटासेटचे सर्वात मोठे मूल्य C5:C13 मिळवते. आणि, MIN फंक्शन त्या श्रेणीतील सर्वात लहान मूल्य मिळवते. शेवटी, ही किमान मूल्ये जास्तीत जास्त वजा करून, आम्हाला स्टील-कट ओट्सची श्रेणी मिळेल.
- शेवटी, फिल हँडल ( ) खाली ड्रॅग करा. + ) साधन, रोल केलेले ओट्स डेटाची सरासरी, एसटीडी विचलन, सीव्ही आणि श्रेणी मोजण्यासाठी सर्व सूत्रे कॉपी करण्यासाठीसेट.
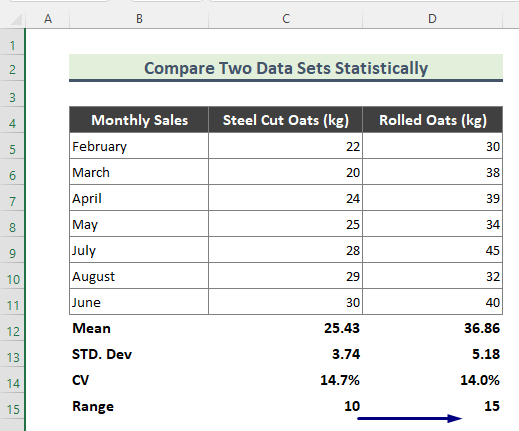
एक्सेलमधील डेटा संचांमधील सांख्यिकीय तुलना
आम्हाला मिळालेल्या निकालानुसार डेटा सेटची तुलना करूया वरील गणनेतून.
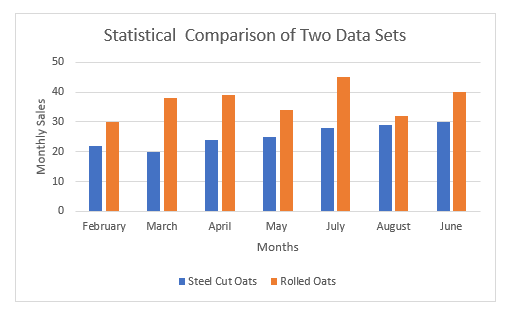
मीन: मीन म्हणजे डेटासेटची अंकगणितीय सरासरी. आणि, वरील गणनेवरून, आम्ही पाहू शकतो की रोलेड ओटची विक्री सरासरी स्टील कटच्या विक्रीपेक्षा जास्त आहे. याचा अर्थ, कालांतराने, रोलेड ओट्सची विक्री इतरांपेक्षा जास्त होते.
मानक विचलन: मानक विचलन हे डेटा पॉइंट्स किंवा मूल्यांच्या सापेक्ष फरकाचे मोजमाप आहे त्यांच्या सरासरी किंवा सरासरीपर्यंत. उदाहरणार्थ, कमी मानक विचलन आम्हाला सांगते की मूल्ये डेटासेटच्या सरासरीच्या जवळ असतात. दुसरीकडे, उच्च मानक विचलनाचा अर्थ असा आहे की मूल्ये विस्तृत श्रेणीमध्ये पसरलेली आहेत. येथे, आमच्या निकालावरून, रोलेड ओट्ससाठी मानक विचलन जास्त आहे. अशा प्रकारे, हे सूचित करते की रोलेड ओट्सची विक्री मूल्ये स्टील-कट ओट्सच्या तुलनेत विस्तृत श्रेणीत पसरलेली आहेत.
सीव्ही: भिन्नता गुणांक (सीव्ही) एक सापेक्ष आहे परिवर्तनशीलतेचे माप जे मानक विचलनाचा आकार त्याच्या सरासरीपर्यंत दर्शवते. आमच्या वरील गणनेवरून, आम्ही पाहू शकतो की स्टील कट ओट्सचा सीव्ही रोलेड ओट्सपेक्षा थोडा जास्त आहे. परिणामी, आम्ही सारांश देऊ शकतो की रोलेड ओट्सची विक्री मूल्ये स्टील-कटच्या तुलनेत अधिक सुसंगत आहेत.
श्रेणी: मध्येआकडेवारी, डेटाच्या संचाची श्रेणी ही सर्वात मोठी आणि सर्वात लहान मूल्यांमधील फरक आहे. डेटासेटवरून हे स्पष्ट होते की रोल्ड ओट्सची श्रेणी जास्त असते. हा परिणाम दर्शवितो की, काही महिन्यांसाठी, रोलेड ओट्सच्या विक्रीतील चढ-उतार स्टील कटच्या तुलनेत जास्त आहे.
निष्कर्ष
वरील लेखात, मी सांख्यिकीय तुलना पद्धतीवर विस्तृतपणे चर्चा करण्याचा प्रयत्न केला आहे. आशा आहे की, ही पद्धत आणि स्पष्टीकरण तुमच्या समस्या सोडवण्यासाठी पुरेसे असेल. कृपया तुमच्या काही शंका असल्यास मला कळवा.
