
सामग्री तालिका
यस लेखमा, म एक्सेलमा दुई डेटा सेटहरूको सांख्यिकीय तुलनाको बारेमा छलफल गर्नेछु। कहिलेकाहीँ, स्प्रेडसिटहरूसँग काम गर्दा, हामीले तथ्याङ्कीय रूपमा डेटा तुलना गर्नुपर्छ। सौभाग्यवश, डेटा सेटहरू बीचको तुलना गर्न एक्सेलमा केही इनबिल्ट प्रकार्यहरू छन्।
अभ्यास कार्यपुस्तिका डाउनलोड गर्नुहोस्
तपाईले अभ्यास कार्यपुस्तिका डाउनलोड गर्न सक्नुहुन्छ जुन हामीले यसलाई तयार गर्न प्रयोग गरेका छौं। लेख।
दुई डाटा सेटको सांख्यिकीय तुलनादुई डेटा सेटको एक्सेल तथ्याङ्कीय तुलना परिचय
हाम्रो उदाहरणमा, हामी स्टिल-कट ओट्स र रोल्ड ओट्सको दुई मासिक बिक्री डेटा सेटहरू प्रयोग गर्नेछौं। एक्सेल मार्फत सांख्यिकीय तुलना गरेर, हामी यी दुई प्रकारका ओट्सको बिक्री समयसँगै कसरी परिवर्तन हुन्छ भनेर पत्ता लगाउनेछौं। यसबाहेक, हामी बिक्री ग्राफिक रूपमा पनि देखाउनेछौं। यसबाहेक, हाम्रो सांख्यिकीय तुलनाको सहजताको लागि, हामीले स्टिल-कट ओट्स अर्थात् दायरा ( C5:C11 ) को लागि मीन, मानक विचलन, भिन्नताको गुणांक, र दायरा फेला पार्नेछौं।

चरणहरू :
- सुरुमा, स्टील कट ओट्सको मीन प्राप्त गर्न, निम्न सूत्र टाइप गर्नुहोस् सेल C12 .
=AVERAGE(C5:C11) 
यहाँ, AVERAGE प्रकार्य ले अंकगणितीय माध्य फर्काउँछ डेटासेटको C5:C11 ।
- अर्को, हामी डेटासेट C5:C11 को मानक विचलन पत्ता लगाउनेछौं। त्यसैले, निम्न टाइप गर्नुहोस् सेल C13 मा सूत्र।
=STDEV.S(C5:C11) 
यहाँ, STDEV। S प्रकार्य नमूनामा आधारित मानक विचलन अनुमान गर्दछ (नमूनामा तार्किक मान र पाठलाई बेवास्ता गर्दछ)
- त्यसपछि, हामी डेटासेटको भिन्नताको गुणांक गणना गर्नेछौं ( C5:C11<४>)। CV गणना गर्ने सूत्र हो:
(मानक विचलन/मीन)*100
- त्यसैले, माथिको समीकरणलाई विचार गर्दै, तल टाइप गर्नुहोस्। स्टिल-कट ओट्स बिक्री प्राप्त गर्न सूत्र:
=C13/C12 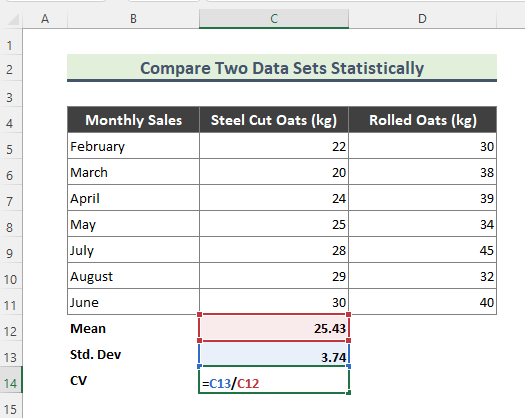
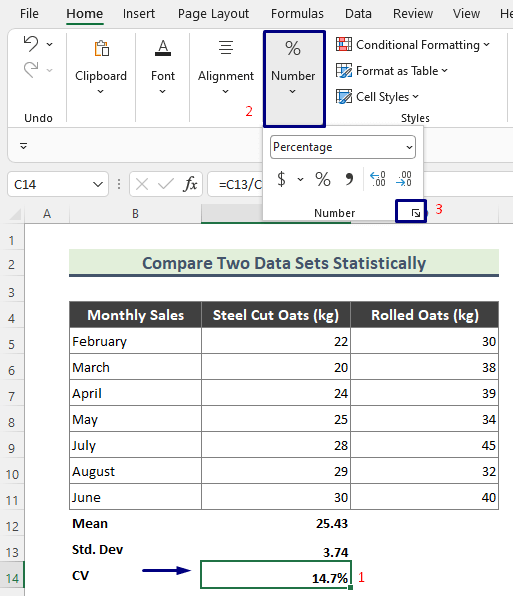
- तथापि, निश्चित गर्नुहोस् कि तपाइँ प्रतिशतमा CV गणना गर्नुहोस्। त्यसो गर्नको लागि, सम्बन्धित सेल ( C14 ) चयन गर्नुहोस्, Home > नम्बर मा जानुहोस्।
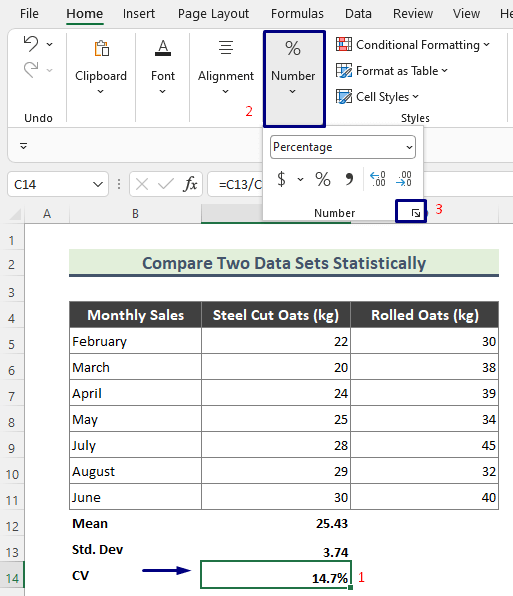
- अब १ दशमलव स्थान भित्र मान राख्न प्रयास गर्नुहोस्, र थिच्नुहोस् ठीक । 14>
- त्यस पछि, हामी डेटा सेटको दायरा गणना गर्नेछौं ( C5:C11 )। माथि उल्लेखित डेटा सेटको दायरा गणना गर्न, यहाँ हाम्रो सूत्र छ:
- अन्तमा, फिल ह्यान्डल ( ) लाई तल तान्नुहोस्। + ) माध्य, STD विचलन, CV, र रोलेड ओट्स डाटाको दायरा गणना गर्न सबै सूत्रहरू प्रतिलिपि गर्न उपकरण।सेट।
=MAX(C5:C11)-MIN(C5:C11) 
MAX प्रकार्य डेटासेट C5:C13 को सबैभन्दा ठूलो मान फर्काउँछ। र, MIN प्रकार्य ले त्यो दायराको सबैभन्दा सानो मान फर्काउँछ। अन्तमा, यी न्यूनतम मानहरूलाई अधिकतमबाट घटाएर, हामीले स्टिल-कट ओट्सको दायरा प्राप्त गर्नेछौं।
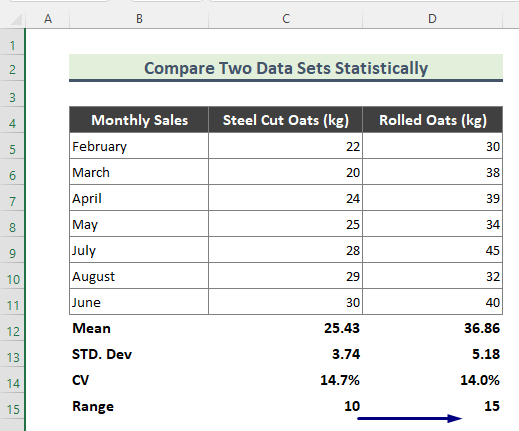
एक्सेलमा डाटा सेटहरू बीचको तथ्याङ्कीय तुलना
हामीले पाएको नतिजाको आधारमा डेटा सेटहरू तुलना गरौं। माथिको गणनाबाट।
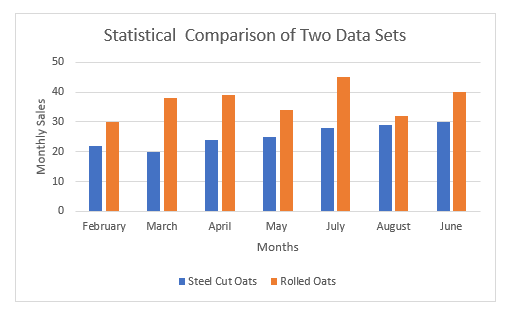
मीन: मीन भनेको डेटासेटको अंकगणितीय औसत हो। र, माथिको गणनाबाट, हामी देख्न सक्छौं कि रोल्ड ओटको बिक्रीको मतलब स्टील कटको भन्दा ठूलो छ। यसको मतलब, समय बित्दै जाँदा, रोल्ड ओट्सको बिक्री अर्को एक भन्दा बढि हुन्छ।
मानक विचलन: मानक विचलन भनेको डेटा बिन्दु वा मानहरूको सापेक्ष भिन्नताको मापन हो। तिनीहरूको औसत वा औसतमा। उदाहरणका लागि, कम मानक विचलनले हामीलाई मानहरू डेटासेटको माध्यको नजिक भएको बताउँछ। अर्कोतर्फ, उच्च मानक विचलन भनेको मानहरू फराकिलो दायरामा फैलिएको हो। यहाँ, हाम्रो नतिजाबाट रोल्ड ओट्सको लागि मानक विचलन ठूलो छ। यसरी, यसले रोल्ड ओट्सको बिक्री मूल्यहरू स्टिल-कट ओट्सको तुलनामा फराकिलो दायरामा फैलिएको संकेत गर्दछ।
CV: भिन्नताको गुणांक (CV) एक सापेक्ष हो। परिवर्तनशीलताको मापन जसले यसको औसतमा मानक विचलनको आकारलाई संकेत गर्दछ। हाम्रो माथिको गणनाबाट, हामी देख्न सक्छौं कि स्टील कट ओट्सको CV रोल्ड ओट्सको भन्दा अलि बढी छ। फलस्वरूप, हामी संक्षेपमा भन्न सक्छौं कि रोल्ड ओट्सको बिक्री मूल्यहरू स्टिल-कटहरूको तुलनामा अधिक सुसंगत छन्।
दायरा: भित्रतथ्याङ्कहरू, डेटाको सेटको दायरा सबैभन्दा ठूलो र सानो मानहरू बीचको भिन्नता हो। रोल्ड ओट्सको दायरा उच्च छ भन्ने डाटासेटहरूबाट स्पष्ट हुन्छ। यो नतिजाले संकेत गर्छ कि, केही महिनाको लागि, रोल्ड ओट्सको बिक्रीको उतारचढाव स्टिल कटको भन्दा बढी छ।
निष्कर्ष
माथिको लेखमा, मैले तथ्याङ्कीय तुलना विधिलाई विस्तृत रूपमा छलफल गर्ने प्रयास गरेको छु। आशा छ, यो विधि र व्याख्या तपाईंको समस्या समाधान गर्न पर्याप्त हुनेछ। कृपया मलाई थाहा दिनुहोस् यदि तपाईंसँग कुनै प्रश्नहरू छन्।
