
विषयसूची
इस लेख में, मैं एक्सेल में दो डेटा सेट की सांख्यिकीय तुलना पर चर्चा करूंगा। कभी-कभी, स्प्रेडशीट्स के साथ काम करते समय, हमें आंकड़ों की सांख्यिकीय रूप से तुलना करनी पड़ती है। सौभाग्य से, डेटा सेट के बीच तुलना करने के लिए एक्सेल में कुछ अंतर्निर्मित कार्य हैं। article.
दो डेटा सेट की सांख्यिकीय तुलना.xlsx
एक्सेल में दो डेटा सेट की सांख्यिकीय तुलना के लिए मुख्य विधि <5
एक्सेल के दो डेटा सेट की सांख्यिकीय तुलना परिचय
हमारे उदाहरण में, हम स्टील-कट ओट्स और रोल्ड ओट्स के दो मासिक बिक्री डेटा सेट का उपयोग करेंगे। एक्सेल के माध्यम से सांख्यिकीय रूप से तुलना करके, हम यह पता लगाएंगे कि समय के साथ इन दो प्रकार के जई की बिक्री कैसे बदलती है। इसके अलावा, हम बिक्री को रेखांकन के रूप में भी दिखाएंगे। इसके अलावा, हमारी सांख्यिकीय तुलना में आसानी के लिए, हम औसत, मानक विचलन, भिन्नता के गुणांक और स्टील-कट ओट्स के लिए रेंज यानी रेंज ( C5:C11 ) पहले पाएंगे।

कदम :
- शुरुआत में, स्टील कट ओट्स का माध्य निकालने के लिए, सेल C12 में निम्न सूत्र टाइप करें .
=AVERAGE(C5:C11) 
यहाँ, औसत फ़ंक्शन अंकगणित माध्य लौटाता है C5:C11 .
- आगे, हम डेटासेट C5:C11 के मानक विचलन का पता लगाएंगे। तो, निम्न टाइप करेंसूत्र सेल C13 में।
=STDEV.S(C5:C11) 
यहाँ, STDEV। S फ़ंक्शन नमूने के आधार पर मानक विचलन का अनुमान लगाता है (नमूने में तार्किक मानों और पाठ को अनदेखा करता है)
- फिर, हम डेटासेट के भिन्नता गुणांक की गणना करेंगे ( C5:C11 ). CV की गणना करने का सूत्र है:
(मानक विचलन/मीन)*100
- इसलिए, उपरोक्त समीकरण पर विचार करते हुए, नीचे टाइप करें स्टील-कट ओट्स की बिक्री पाने का फॉर्मूला:
=C13/C12 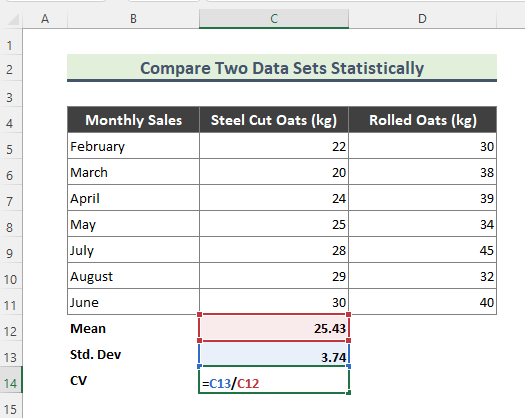
- हालांकि, सुनिश्चित करें कि आप प्रतिशत में सीवी की गणना करें। ऐसा करने के लिए, संबंधित सेल ( C14 ) का चयन करें, होम > नंबर पर जाएं।
- अब मान को 1 दशमलव स्थान के भीतर रखने का प्रयास करें, और ठीक दबाएं।
- उसके बाद, हम डेटा सेट की श्रेणी की गणना करेंगे ( C5:C11 )। उपर्युक्त डेटा सेट की सीमा की गणना करने के लिए, यहाँ हमारा सूत्र है:
=MAX(C5:C11)-MIN(C5:C11) 
मैक्स फ़ंक्शन डेटासेट C5:C13 का सबसे बड़ा मान लौटाता है। और, MIN फ़ंक्शन उस श्रेणी का सबसे छोटा मान लौटाता है। अंत में, इन न्यूनतम मूल्यों को अधिकतम एक से घटाकर, हमें स्टील-कट ओट्स की रेंज मिलेगी।
- अंत में, फिल हैंडल ( को नीचे खींचें + ) रोल्ड ओट्स डेटा के माध्य, एसटीडी विचलन, सीवी और रेंज की गणना करने के लिए सभी फॉर्मूले को कॉपी करने के लिए टूलसेट।
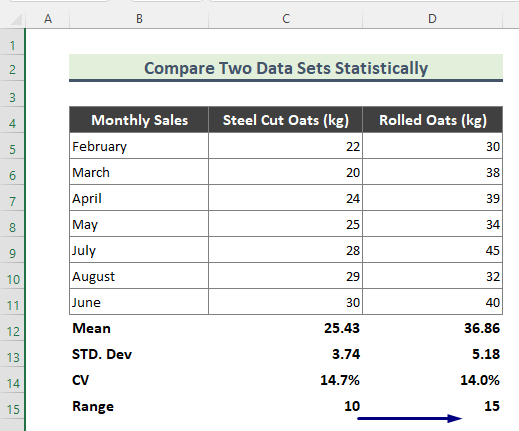
एक्सेल में डेटा सेट के बीच सांख्यिकीय तुलना
हमें प्राप्त परिणाम के आधार पर डेटा सेट की तुलना करते हैं उपरोक्त गणना से।
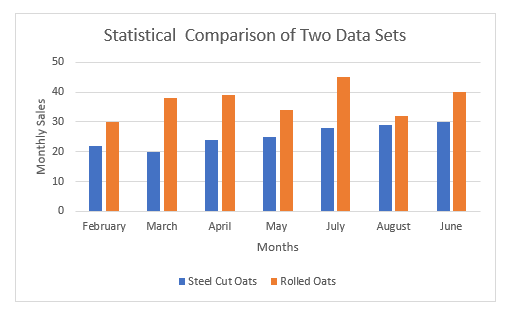
माध्य: माध्य एक डेटासेट का अंकगणितीय औसत है। और, उपरोक्त गणना से, हम देख सकते हैं कि रोल्ड ओट की बिक्री का मतलब स्टील कट वाले की तुलना में अधिक है। इसका मतलब है, समय के साथ, रोल्ड ओट्स की बिक्री अन्य की तुलना में अधिक होती है।
मानक विचलन: मानक विचलन डेटा बिंदुओं या मूल्यों के सापेक्ष भिन्नता की मात्रा का एक उपाय है। उनके औसत या औसत के लिए। उदाहरण के लिए, एक निम्न मानक विचलन हमें बताता है कि मान डेटासेट के माध्य के करीब होते हैं। दूसरी ओर, एक उच्च मानक विचलन का अर्थ है कि मान व्यापक श्रेणी में फैले हुए हैं। यहाँ, हमारे परिणाम से रोल्ड ओट्स के लिए मानक विचलन अधिक है। इस प्रकार, यह इंगित करता है कि रोल्ड ओट्स के बिक्री मूल्य स्टील-कट ओट्स की तुलना में व्यापक रेंज में फैले हुए हैं।
सीवी: भिन्नता का गुणांक (सीवी) एक सापेक्ष है परिवर्तनशीलता का माप जो एक मानक विचलन के आकार को उसके माध्य से इंगित करता है। हमारी उपरोक्त गणना से, हम देख सकते हैं कि स्टील कट ओट्स का सीवी रोल्ड ओट्स की तुलना में थोड़ा अधिक है। नतीजतन, हम संक्षेप में कह सकते हैं कि रोल्ड ओट्स के बिक्री मूल्य स्टील-कट वाले की तुलना में अधिक सुसंगत हैं।
रेंज: मेंआँकड़े, डेटा के एक सेट की सीमा सबसे बड़े और सबसे छोटे मूल्यों के बीच का अंतर है। डेटासेट से यह स्पष्ट है कि रोल्ड ओट्स की रेंज अधिक होती है। यह परिणाम इंगित करता है कि, कुछ महीनों के लिए, रोल्ड जई की बिक्री में उतार-चढ़ाव स्टील कट वाले की तुलना में अधिक है।
निष्कर्ष
उपरोक्त लेख में, मैंने सांख्यिकीय तुलना पद्धति पर विस्तार से चर्चा करने का प्रयास किया है। उम्मीद है, यह तरीका और स्पष्टीकरण आपकी समस्याओं को हल करने के लिए पर्याप्त होगा। यदि आपके कोई प्रश्न हैं तो कृपया मुझे बताएं।
