
Inhoudsopgave
In dit artikel bespreek ik de statistische vergelijking van twee gegevensverzamelingen in Excel. Soms moeten we bij het werken met spreadsheets gegevens statistisch vergelijken. Gelukkig heeft Excel een aantal ingebouwde functies om gegevensverzamelingen met elkaar te vergelijken.
Download het oefenwerkboek
U kunt het oefenwerkboek downloaden dat wij hebben gebruikt om dit artikel voor te bereiden.
Statistische vergelijking van twee gegevensreeksen.xlsxSleutelmethode voor statistische vergelijking van twee gegevensreeksen in Excel
Excel Statistische vergelijking van twee gegevensverzamelingen Inleiding
In ons voorbeeld gebruiken we twee maandelijkse verkoopdatasets van Steel-cut oats en Rolled oats. Door statistisch te vergelijken via Excel, zullen we te weten komen hoe de verkoop van deze twee soorten haver verandert in de tijd. Bovendien zullen we de verkoop ook grafisch weergeven. Verder zullen we, om onze statistische vergelijking te vergemakkelijken, het gemiddelde, de standaardafwijking, de variatiecoëfficiënt en het bereik vinden voorSteel-cut haver, d.w.z. range ( C5:C11 ) eerst.

Stappen :
- Om in eerste instantie de Mean of Steel cut oats te krijgen, typt u de volgende formule in Cel C12 .
=GEMIDDELDE(C5:C11) 
Hier, de functie AVERAGE geeft het rekenkundig gemiddelde van dataset C5:C11 .
- Vervolgens zullen we de standaardafwijking van de dataset bepalen C5:C11 Dus typ de volgende formule in Cel C13 .
=STDEV.S(C5:C11) 
Hier, de functie STDEV.S schat standaardafwijking op basis van steekproef (negeert logische waarden en tekst in de steekproef)
- Vervolgens berekenen we de variatiecoëfficiënt van de dataset ( C5:C11 ). De formule om de CV te berekenen is:
(standaardafwijking/gemiddelde)*100
- Dus, gezien de bovenstaande vergelijking, typ de onderstaande formule om de verkoop van Steel-cut haver te krijgen:
=C13/C12 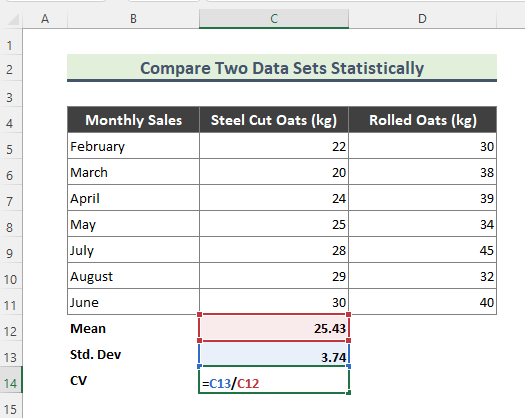
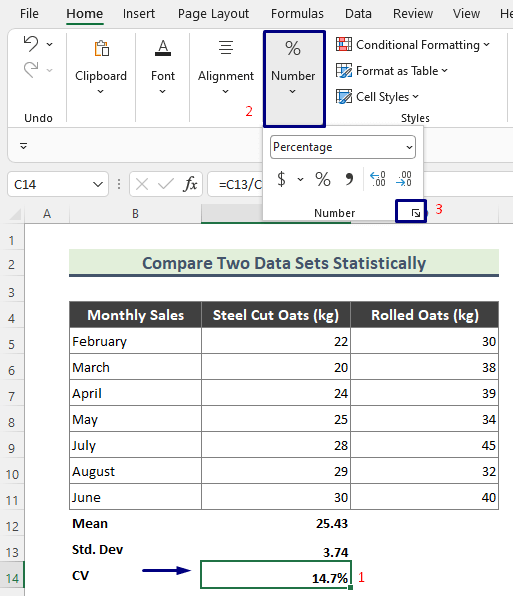
- Zorg er echter voor dat u de CV in procenten berekent. Selecteer daartoe de overeenkomstige cel ( C14 ), ga naar Home > Nummer .
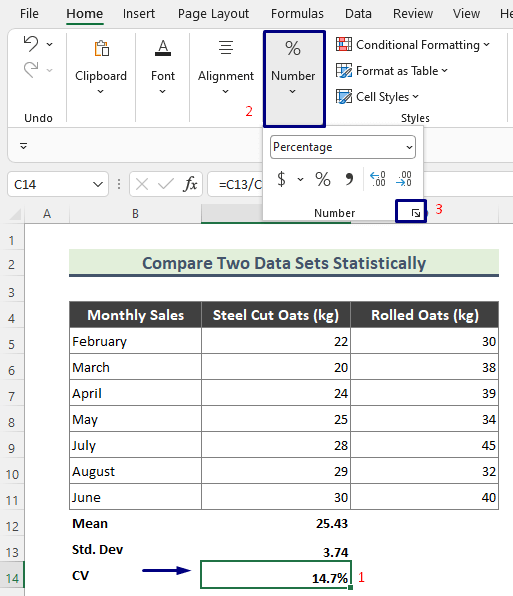
- Probeer nu de waarde binnen 1 decimaal te houden, en druk op OK .
- Daarna berekenen we het bereik van de gegevensverzameling ( C5:C11 ). Om het bereik van de bovengenoemde gegevensreeks te berekenen, volgt hier onze formule:
=MAX(C5:C11)-MIN(C5:C11) 
De MAX-functie geeft de grootste waarde van de dataset C5:C13. En, de MIN functie geeft de kleinste waarde van dat bereik. Door tenslotte deze minimumwaarden af te trekken van het maximum, krijgen we het bereik van de Steel-Cut Oats.
- Sleep tenslotte de Vulgreep ( + ) om alle formules te kopiëren voor de berekening van het gemiddelde, de standaardafwijking, de CV en het bereik van de gegevensverzameling over haver.
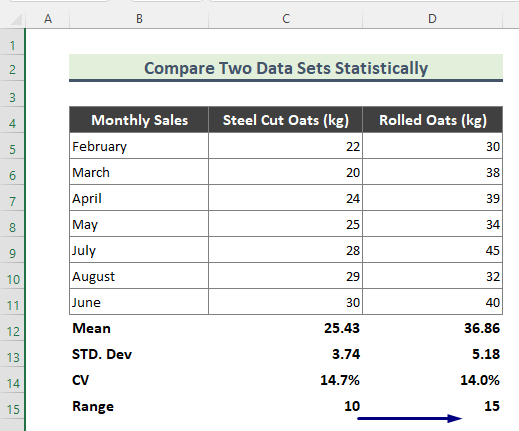
Statistische vergelijking tussen gegevenssets in Excel
Laten we de gegevensreeksen vergelijken aan de hand van het resultaat van de bovenstaande berekening.
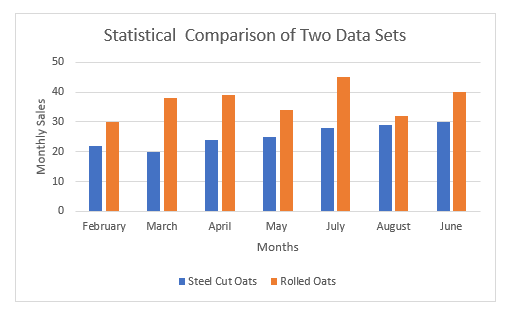
Gemeen: Het gemiddelde is het rekenkundig gemiddelde van een dataset. En uit de bovenstaande berekening blijkt dat het gemiddelde van de verkoop van gerolde haver groter is dan die van staal gesneden haver.
Standaard afwijking: De standaardafwijking is een maat voor de hoeveelheid variatie van datapunten of waarden ten opzichte van hun gemiddelde. Een lage standaardafwijking vertelt ons bijvoorbeeld dat de waarden meestal dicht bij het gemiddelde van de dataset liggen. Een hoge standaardafwijking daarentegen betekent dat de waarden over een groter bereik zijn verspreid. Uit ons resultaat blijkt dat de standaardafwijking groter is voor RolledDit wijst erop dat de verkoopwaarden van havervlokken over een grotere bandbreedte zijn verspreid dan die van havervlokken.
CV: De variatiecoëfficiënt (CV) is een relatieve maat voor de variabiliteit die de grootte van een standaardafwijking ten opzichte van het gemiddelde aangeeft. Uit onze bovenstaande berekening blijkt dat de CV van Steel cut haver iets hoger is dan die van Rolled haver. Bijgevolg kunnen we samenvatten dat de verkoopwaarden van Rolled haver consistenter zijn dan die van Steel-cut.
Bereik: In de statistiek is het bereik van een reeks gegevens het verschil tussen de grootste en de kleinste waarde. Uit de datasets blijkt dat de verkoop van gerolde haver een groter bereik heeft. Dit resultaat wijst erop dat de verkoop van gerolde haver in sommige maanden sterker fluctueert dan die van de Steel cut haver.
Conclusie
In het bovenstaande artikel heb ik geprobeerd de statistische vergelijkingsmethode uitvoerig te bespreken. Hopelijk is deze methode en uitleg voldoende om uw problemen op te lossen. Laat het me weten als u vragen heeft.
