
Sadržaj
Koristimo regresionu analizu kada imamo podatke iz dvije varijable iz dva različita izvora i želimo izgraditi odnos između njih. Regresiona analiza nam pruža linearni model koji nam omogućava da predvidimo moguće ishode. Postojaće neke razlike između predviđenih i stvarnih vrijednosti iz očiglednih razloga. Kao rezultat, mi izračunavamo standardnu grešku koristeći regresijski model, koji je prosječna greška između predviđenih i stvarnih vrijednosti. U ovom vodiču ćemo vam pokazati kako izračunati standardnu grešku regresijske analize u Excelu .
Preuzmite radnu svesku za vježbe
Preuzmite ovu radnu svesku za vježbanje da biste vježbali dok ste čitajući ovaj članak.
Standardna greška regresije.xlsx
4 jednostavna koraka za izračunavanje standardne greške regresije u Excelu
Pretpostavimo da imate skup podataka sa nezavisnom varijablom ( X ) i zavisnom varijablom ( Y ) . Kao što vidite, nemaju značajnu vezu. Ali želimo da ga izgradimo. Kao rezultat toga, koristit ćemo Regresijska analiza da stvorimo linearni odnos između to dvoje. Izračunat ćemo standardnu grešku između dvije varijable koristeći regresionu analizu. Proći ćemo preko nekih parametara regresijskog modela u drugoj polovici članka kako bismo vam pomogli da ga protumačite.

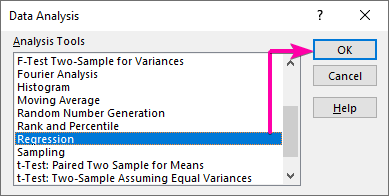
Korak 1: Primijenite naredbu za analizu podataka naKreirajte regresijski model
- Prvo, idite na karticu Podaci i kliknite na Analiza podataka naredba.

- U listi Analiza podataka odaberite Regresija opcija.
- Zatim kliknite OK .
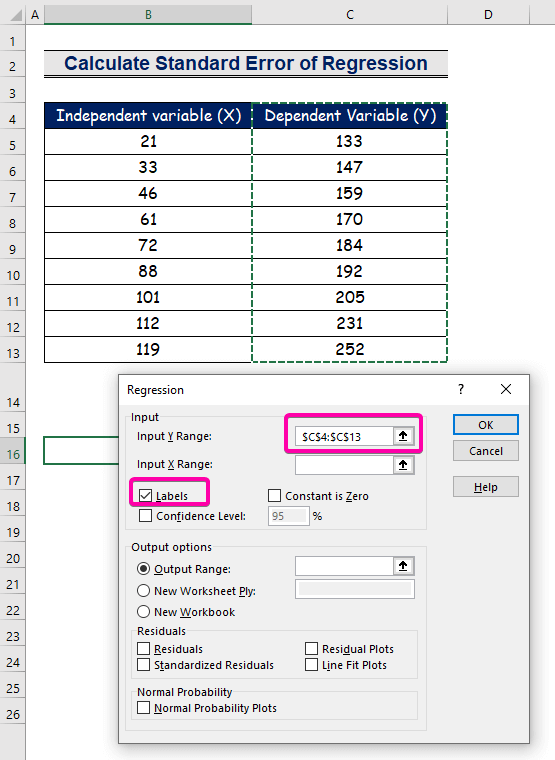
Korak 2: Umetnite ulazni i izlazni raspon u regresijski okvir
- Za Oseg unosa Y odaberite raspon C4:C13 sa zaglavljem.
- Kliknite na Oznake potvrdni okvir.
- Odaberite raspon B4:B13 za Oseg unosa X .
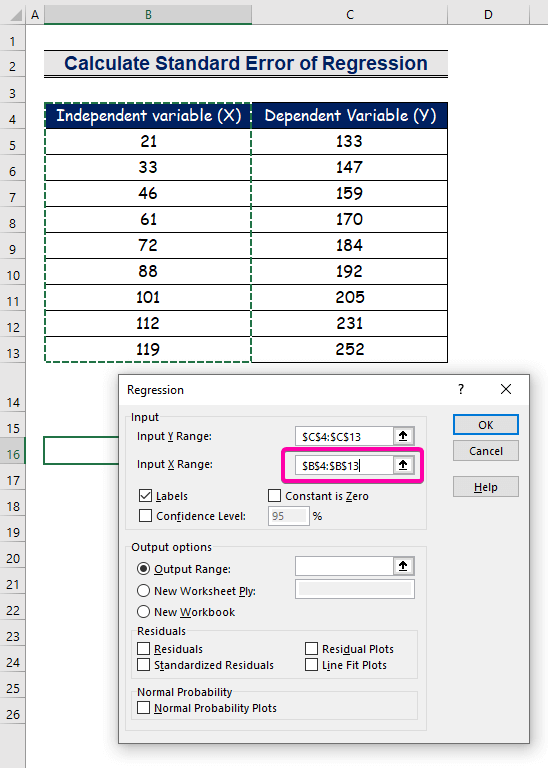
- Da dobijete rezultat na željenoj lokaciji, odaberite bilo koju ćeliju ( B16 ) za Izlazni raspon .
- Na kraju kliknite OK .

Pročitajte više: Kako izračunati standardnu grešku proporcije u Excelu (sa jednostavnim koracima)
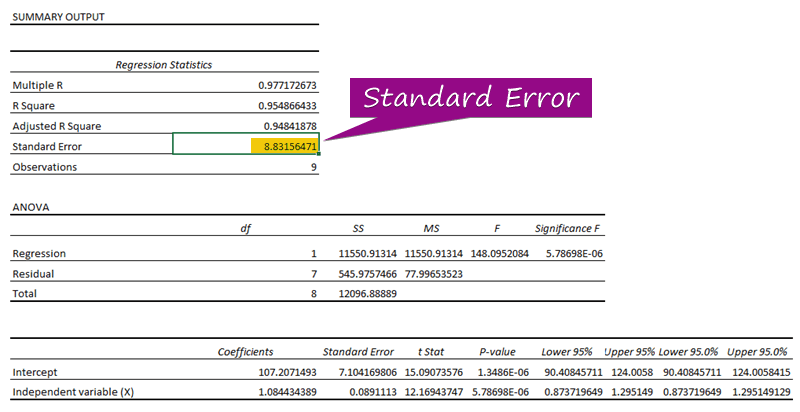
Korak 3: Saznajte standardnu grešku
- Od regresionom analizom možete dobiti vrijednost od standardna greška ( 3156471 ).
Pročitajte više: Kako za pronalaženje preostale standardne greške u Excelu (2 jednostavne metode)
Korak 4: Iscrtajte grafikon regresijskog modela
- Prvo, kliknite na Insert kartica.
- Iz grupe Grafikoni odaberite Raspojeno grafikon.
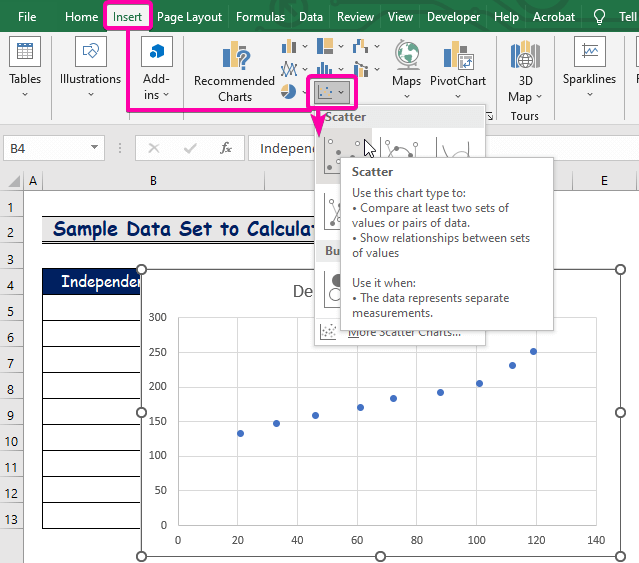
- Kliknite desnim tasterom miša preko jednog odbodova.
- Iz opcija odaberite opciju Dodaj liniju trenda .
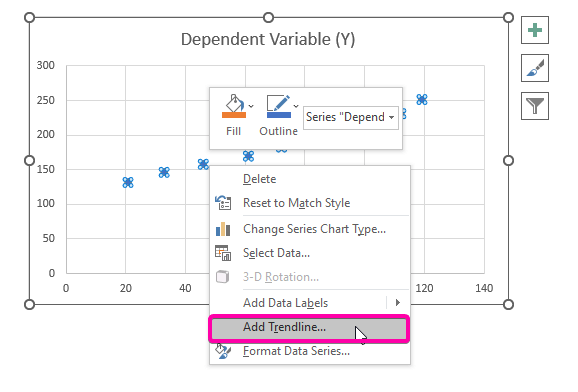
- Stoga, vaš grafikon regresijske analize će biti iscrtan kao na slici prikazanoj ispod.

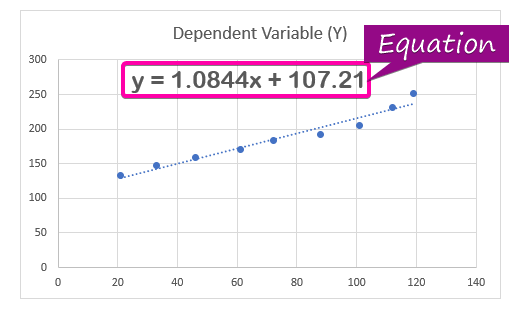
- Za prikaz jednadžbe regresije , kliknite na Prikaži jednadžbu na grafikonu opciju iz Formatiraj liniju trenda.

- Kao rezultat, jednadžba ( y = 1,0844x + 107,21 ) regresione analize će se pojaviti na grafikonu.
Napomene:
Možete izračunati razliku između predviđenih vrijednosti i stvarnih vrijednosti iz jednadžbe regresione analize.
Koraci:
- Upišite formulu koja će predstavljati jednadžbu regresione analize.
=1.0844*B5 + 107.21 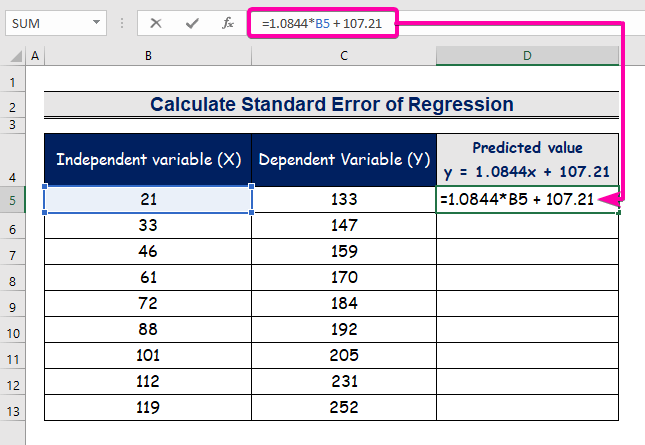
- Dakle, dobit ćete prvu predviđenu vrijednost ( 129,9824 ), koja se razlikuje od stvarne vrijednosti ( 133 ).

- Koristite Alat za automatsko popunjavanje za automatsko popunjavanje kolone D .

- Da biste izračunali grešku, unesite sljedeću formulu oduzmi.
=C5-D5 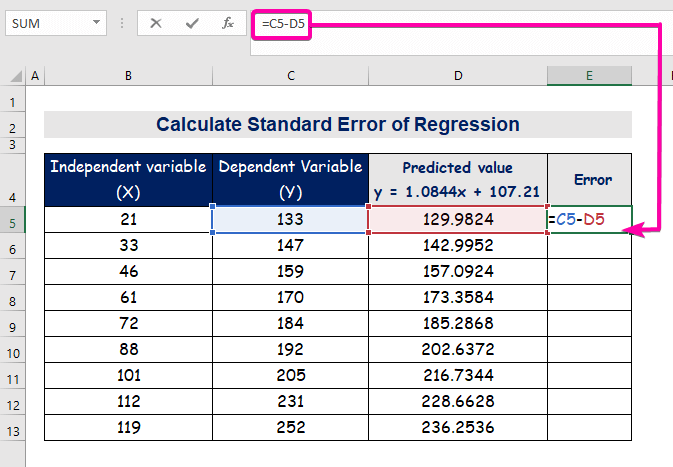
- Konačno, automatski popuni kolonu E da biste pronašli vrijednosti greške.
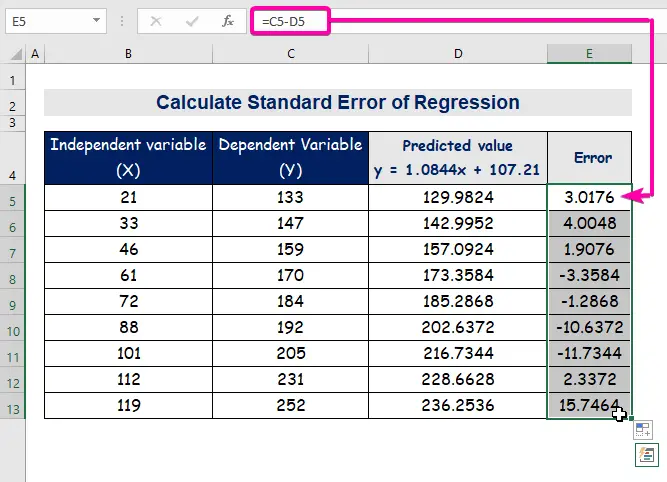
Pročitajte više: Kako izračunati standardnu grešku nagiba regresije u Excel
Interpretacija regresijske analize u Excelu
1. Standardna greška
Iz jednačine regresione analize možemo vidjeti da uvijek postoji razlika ili greška između predviđenih i stvarnih vrijednosti. Kao rezultat, moramo izračunati prosječnu devijaciju razlika.
A standardna greška predstavlja prosječnu grešku između predviđene vrijednosti i stvarne vrijednosti. Otkrili smo 8.3156471 kao standardnu grešku u našem primjeru regresijskog modela. To ukazuje da postoji razlika između predviđenih i stvarnih vrijednosti, koja može biti veća od standardne greške ( 15,7464 ) ili manja od standardna greška ( 4.0048 ). Međutim, naša prosječna greška će biti 8,3156471 , što je standardna greška .
Kao rezultat, cilj modela je smanjiti standardnu grešku. Što je manja standardna greška, to je točniji model.
2. Koeficijenti
Koeficijent regresije procjenjuje odgovori nepoznatih vrijednosti. U jednadžbi regresije ( y = 1,0844x + 107,21 ), 1,0844 je koeficijent , x je nezavisna varijabla prediktora, 107.21 je konstanta, a y je vrijednost odgovora za x .
- A pozitivni koeficijent predviđa da što je veći koeficijent, to je veći odzivvarijabla. Ukazuje na proporcionalni odnos.
- negativni koeficijent predviđa da što je koeficijent veći, to su niže vrijednosti odgovora. To ukazuje na disproporcionalni odnos.
3. P-vrijednosti
U regresijskoj analizi, p- vrijednosti i koeficijenti sarađuju kako bi vas obavijestili da li su korelacije u vašem modelu statistički relevantne i kakve su te veze. nulta hipoteza da nezavisna varijabla nema vezu sa zavisnom varijablom testira se korištenjem p-vrijednosti za svaku nezavisnu varijablu. Ne postoji veza između promjena nezavisne varijable i varijacija zavisne varijable ako ne postoji korelacija.
- Vaš uzorak podataka daje dovoljnu podršku da se pogreši nulta hipoteza za punu populaciju ako je p-vrijednost za varijablu manja od vašeg praga značajnosti. Vaši dokazi podržavaju ideju korelacije koja nije nula . Na nivou populacije, promjene nezavisne varijable povezane su s promjenama zavisne varijable.
- A p-vrijednost veća od nivoa značajnosti, s obje strane , sugerira da vaš uzorak nema nedovoljan dokaz da utvrdi da postoji korelacija koja nije nula .
Zato što njihove p-vrijednosti ( 5.787E-06 , 1.3E-06 ) su manje od značajne vrijednosti ( 5.787E-06 ), nezavisne varijable (X) i Presjek su statistički značajni , kao što se vidi u primjeru izlaza regresije.
4. Vrijednosti R-kvadrata
Za modele linearne regresije, R-kvadrat je mjera kompletnosti . Ovaj omjer pokazuje postotak varijanse u zavisnoj varijabli koju nezavisni faktori uzimaju u obzir kada se uzmu zajedno. Na praktičnoj skali 0–100 posto, R-kvadrat kvantificira jaču veze između vašeg modela i zavisne varijable.
Vrijednost R2 je mjera koliko dobro regresijski model odgovara vašim podacima. Što je veći broj , to je bolji izvediv model.
Zaključak
Nadam se da vam je ovaj članak dao vodič o tome kako izračunati standardnu grešku regresije u Excel . Sve ove procedure treba naučiti i primijeniti na vaš skup podataka. Pogledajte radnu svesku za vježbanje i testirajte ove vještine. Motivirani smo da nastavimo s izradom ovakvih tutorijala zbog vaše vrijedne podrške.
Molimo vas da nas kontaktirate ako imate bilo kakvih pitanja. Također, slobodno ostavite komentare u donjem odjeljku.
Mi, Exceldemy tim, uvijek odgovaramo na vaše upite.
Ostanite s nama i nastavite učiti.
