
Inhoudsopgave
We gebruiken regressieanalyse wanneer we gegevens hebben van twee variabelen uit twee verschillende bronnen en daartussen een verband willen leggen. Regressieanalyse levert ons een lineair model op waarmee we mogelijke uitkomsten kunnen voorspellen. Er zullen om voor de hand liggende redenen enkele verschillen zijn tussen de voorspelde en de werkelijke waarden. Als gevolg daarvan hebben we bereken de standaardfout met het regressiemodel, dat is de gemiddelde fout tussen voorspelde en werkelijke waarden. In deze tutorial laten we u zien hoe u de standaardfout van regressieanalyse in Excel .
Download Praktijk werkboek
Download dit oefenwerkboek om te oefenen terwijl u dit artikel leest.
Regressie standaardfout.xlsx4 eenvoudige stappen om de standaardfout van een regressie in Excel te berekenen
Stel dat u een gegevensverzameling hebt met een onafhankelijke variabele ( X ) en een afhankelijke variabele ( Y ) Zoals je kunt zien, hebben ze geen significante relatie. Maar we willen er een opbouwen. Daarom gebruiken we Regressieanalyse We berekenen de standaardfout tussen de twee variabelen met behulp van de regressieanalyse. In de tweede helft van het artikel bespreken we enkele parameters van het regressiemodel om u te helpen bij de interpretatie ervan.

Stap 1: Gegevensanalysecommando toepassen om een regressiemodel te maken
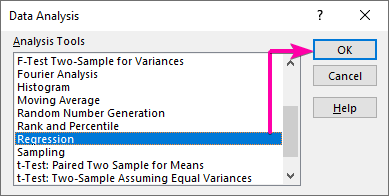
- Ga eerst naar de Gegevens tabblad en klik op de Gegevensanalyse commando.

- Van de Gegevensanalyse lijst box, selecteer de Regressie optie.
- Klik dan op OK .
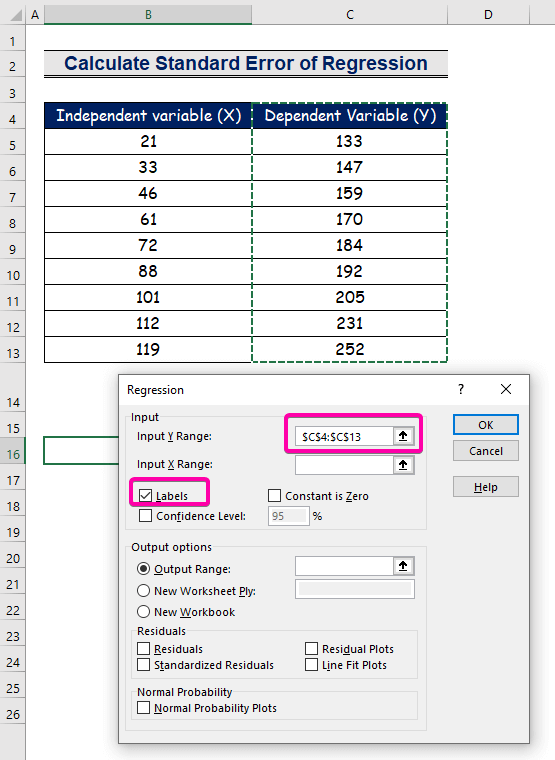
Stap 2: Invoer- en uitvoerbereik in regressievak invoegen
- Voor de Ingangsbereik Y selecteer het bereik C4:C13 met de kop.
- Klik op de Labels check box.
- Selecteer het bereik B4:B13 voor de Ingang X Bereik .
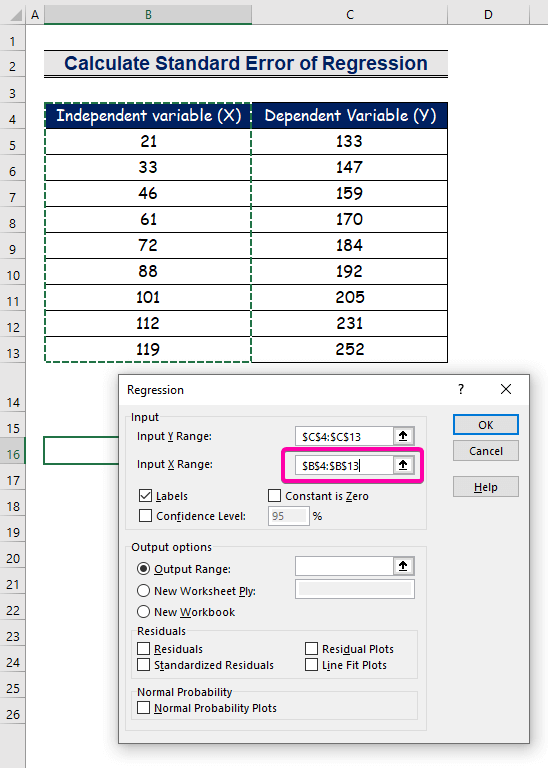
- Om het resultaat op de gewenste plaats te krijgen, selecteert u een willekeurige cel ( B16 ) voor de Uitvoerbereik .
- Klik tenslotte op OK .

Lees meer: Hoe Standaard Fout van Verhouding berekenen in Excel (met eenvoudige stappen)
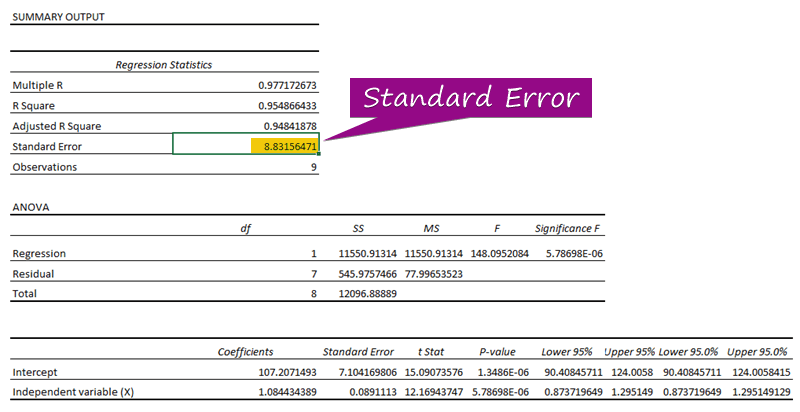
Stap 3: Bepaal de standaardfout
- Uit de regressieanalyse kunt u de waarde van de standaardafwijking ( 3156471 ).
Lees meer: Hoe de residuele standaardfout te vinden in Excel (2 eenvoudige methoden)
Stap 4: Diagram van het regressiemodel uitzetten
- Klik eerst op de Plaats tab.
- Van de Grafieken groep, selecteer de Strooi grafiek.
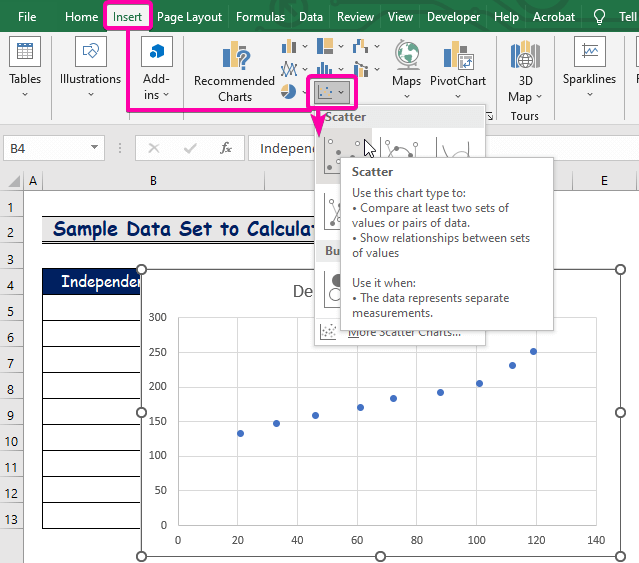
- Klik met de rechtermuisknop op over een van de punten.
- Selecteer uit de opties de Trendlijn toevoegen optie.
- Daarom is uw regressieanalyse grafiek wordt uitgezet als de afbeelding hieronder.

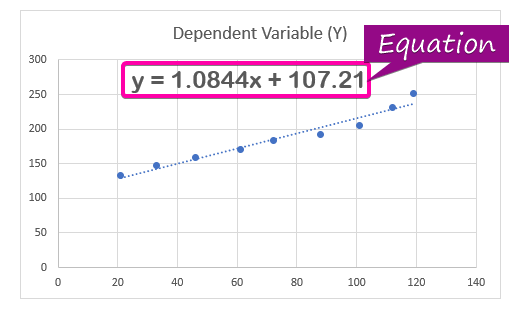
- Om de regressieanalyse vergelijking, klik op de Vergelijking op grafiek weergeven optie van de Formaat Trendline.

- Bijgevolg is de vergelijking ( y = 1,0844x + 107,21 ) van de regressieanalyse verschijnt in de grafiek.
Opmerkingen:
U kunt het verschil tussen de voorspelde waarden en de werkelijke waarden uit de vergelijking van de regressieanalyse berekenen.
Stappen:
- Typ de formule voor de regressievergelijking.
=1.0844*B5 + 107.21 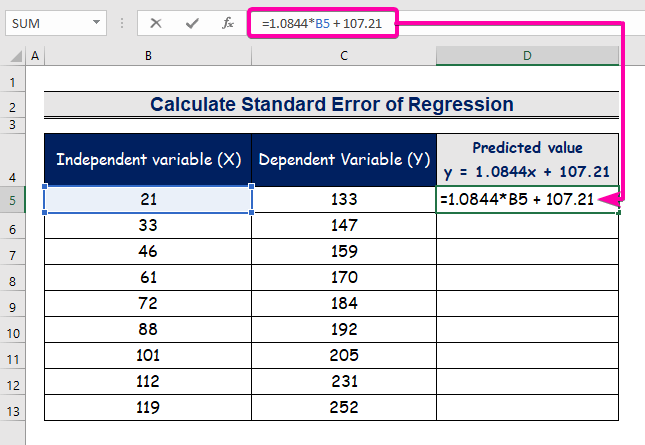
- Daarom krijgt u de eerste voorspelde waarde ( 129.9824 ), die afwijkt van de werkelijke waarde ( 133 ).

- Gebruik de AutoFill Tool om de kolom automatisch te vullen D .

- Om de fout te berekenen, typt u de volgende formule om af te trekken.
=C5-D5 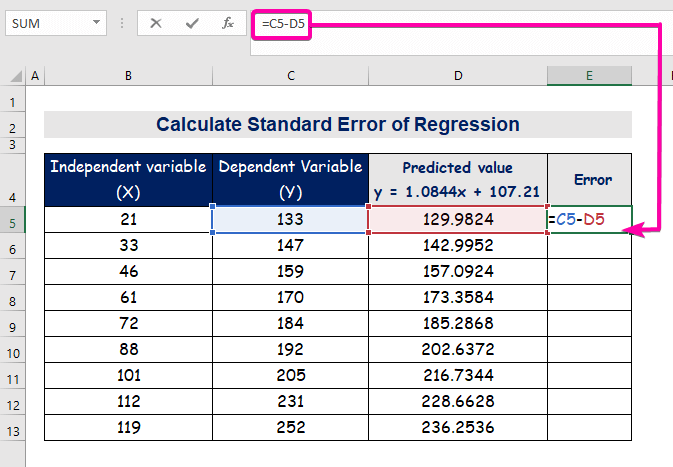
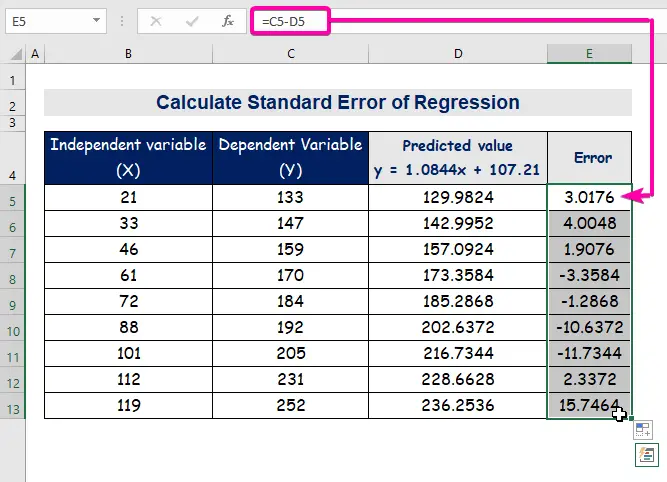
- Tenslotte, automatisch vullen van de kolom E om de foutwaarden te vinden.
Lees meer: De standaardfout van de regressiehelling berekenen in Excel
De interpretatie van regressieanalyse in Excel
1. Standaardfout
Uit de vergelijking voor regressieanalyse blijkt dat er altijd een verschil of fout bestaat tussen de voorspelde en de werkelijke waarden. Daarom moeten we de gemiddelde afwijking van de verschillen berekenen.
A standaardfout staat voor de gemiddelde fout tussen de voorspelde waarde en de werkelijke waarde. Wij ontdekten 8.3156471 als de standaardfout in ons voorbeeld regressiemodel. Het geeft aan dat er een verschil is tussen de voorspelde en de werkelijke waarden, dat groter kan zijn dan de standaardfout ( 15.7464 ) of minder dan de standaardfout ( 4.0048 ). Onze gemiddelde fout zal 8.3156471 die de standaardfout .
Het doel van het model is dus om de standaardfout te verkleinen. De lager de standaardfout, hoe meer nauwkeurig het model.
2. Coëfficiënten
De regressiecoëfficiënt evalueert de antwoorden van onbekende waarden. In de regressievergelijking ( y = 1,0844x + 107,21 ), 1.0844 is de coëfficiënt , x is de voorspellende onafhankelijke variabele, 107.21 is de constante, en y is de responswaarde voor de x .
- A positieve coëfficiënt voorspelt dat hoe hoger de coëfficiënt, hoe hoger de responsvariabele. Het wijst op een proportioneel relatie.
- A negatieve coëfficiënt voorspelt dat hoe hoger de coëfficiënt, hoe lager de responswaarden. Het wijst op een onevenredig relatie.
3. P-waarden
In regressie analyse, p-waarden en coëfficiënten werken samen om u te informeren of correlaties in uw model statistisch relevant zijn en hoe die relaties zijn. De nulhypothese dat de onafhankelijke variabele geen verband heeft met de afhankelijke variabele wordt getest met behulp van de p-waarde Er is geen verband tussen veranderingen in de onafhankelijke variabele en variaties in de afhankelijke variabele indien er geen correlatie is.
- Uw steekproefgegevens geven voldoende steun om vervalsen de nulhypothese voor de volledige populatie als de p-waarde voor een variabele is minder dan uw significantiedrempel. Uw bewijs ondersteunt de notie van een niet-nul correlatie Op populatieniveau zijn veranderingen in de onafhankelijke variabele gekoppeld aan veranderingen in de afhankelijke variabele.
- A p-waarde grotere dan het significantieniveau, aan beide zijden, suggereert dat uw steekproef onvoldoende bewijs om vast te stellen dat een niet-nul correlatie bestaat.
Omdat hun p-waarden ( 5.787E-06 , 1.3E-06 ) zijn minder dan de significante waarde ( 5.787E-06 ), de Onafhankelijke variabele (X) en Onderscheppen zijn statistisch significant zoals blijkt uit het voorbeeld van de regressie-uitvoer.
4. R-kwadraatwaarden
Voor lineaire regressiemodellen, R-kwadraat is een meting van de volledigheid Deze verhouding toont de percentage van de variantie in de afhankelijke variabele die de onafhankelijke factoren samen veroorzaken. Op een handige 0-100 procentuele schaal, R-kwadraat kwantificeert de sterkte van het verband tussen uw model en de afhankelijke variabele.
De R2 waarde is een maatstaf voor hoe goed het regressiemodel bij uw gegevens past. De hoger de nummer de beter het model uitvoerbaar.
Conclusie
Ik hoop dat dit artikel u een handleiding heeft gegeven over het berekenen van de standaardfout van regressie in Excel Al deze procedures moeten worden geleerd en toegepast op uw dataset. Bekijk de oefenwerkmap en stel deze vaardigheden op de proef. We zijn gemotiveerd om tutorials als deze te blijven maken dankzij uw waardevolle steun.
Neem contact met ons op als u vragen hebt. Laat ook gerust opmerkingen achter in de rubriek hieronder.
Wij, de Exceldemy Team, reageren altijd op uw vragen.
Blijf bij ons en blijf leren.
