
Talaan ng nilalaman
Gumagamit kami ng pagsusuri ng regression kapag mayroon kaming data mula sa dalawang variable mula sa dalawang magkaibang pinagmulan at gustong bumuo ng ugnayan sa pagitan ng mga ito. Ang Regression analysis ay nagbibigay sa amin ng isang linear na modelo na nagbibigay-daan sa amin na mahulaan ang mga posibleng resulta. Magkakaroon ng ilang pagkakaiba sa pagitan ng hinulaang at aktwal na mga halaga para sa mga malinaw na dahilan. Bilang resulta, kinakalkula namin ang karaniwang error gamit ang modelo ng regression, na siyang average na error sa pagitan ng hinulaang at aktwal na mga halaga. Sa tutorial na ito, ipapakita namin sa iyo kung paano kalkulahin ang karaniwang error ng regression analysis sa Excel .
I-download ang Practice Workbook
I-download ang practice workbook na ito para mag-ehersisyo habang ikaw ay binabasa ang artikulong ito.
Regression Standard Error.xlsx
4 Simple Steps to Calculate Standard Error of Regression in Excel
Ipagpalagay na mayroon kang isang set ng data na may independent variable ( X ) at isang dependent variable ( Y ) . Tulad ng nakikita mo, wala silang makabuluhang relasyon. Ngunit gusto naming bumuo ng isa. Bilang resulta, gagamitin namin ang Regression Analysis para gumawa ng linear na relasyon sa pagitan ng dalawa. Kakalkulahin namin ang karaniwang error sa pagitan ng dalawang variable gamit ang pagsusuri ng regression. Tatalakayin namin ang ilan sa mga parameter ng modelo ng regression sa ikalawang kalahati ng artikulo upang matulungan kang bigyang-kahulugan ito.

Hakbang 1: Ilapat ang Data Analysis Command saGumawa ng Regression Model
- Una, pumunta sa Data tab at mag-click sa Data Analysis command.

- Mula sa listahan ng Pagsusuri ng Data , piliin ang Regression opsyon.
- Pagkatapos, i-click ang OK .
Hakbang 2: Ilagay ang Input at Output Range sa Regression Box
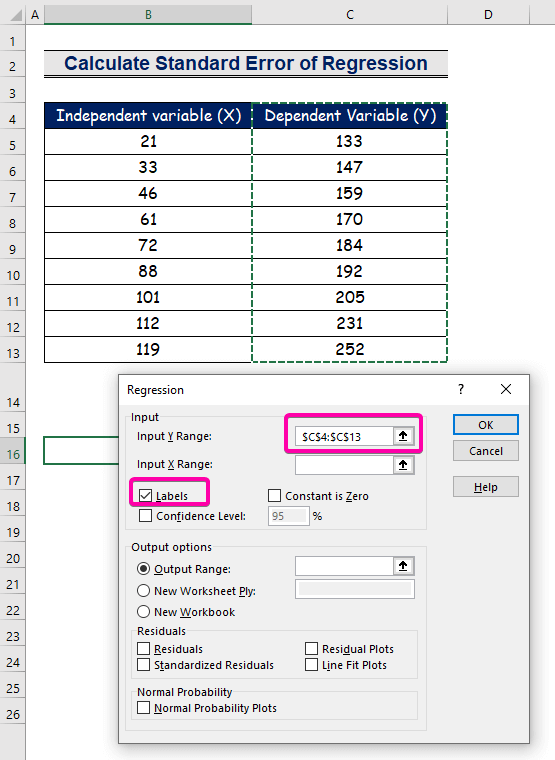
- Para sa Input Y Range , piliin ang range C4:C13 gamit ang header.
- Mag-click sa check box na Mga Label .
- Piliin ang range B4:B13 para sa Input X Range .
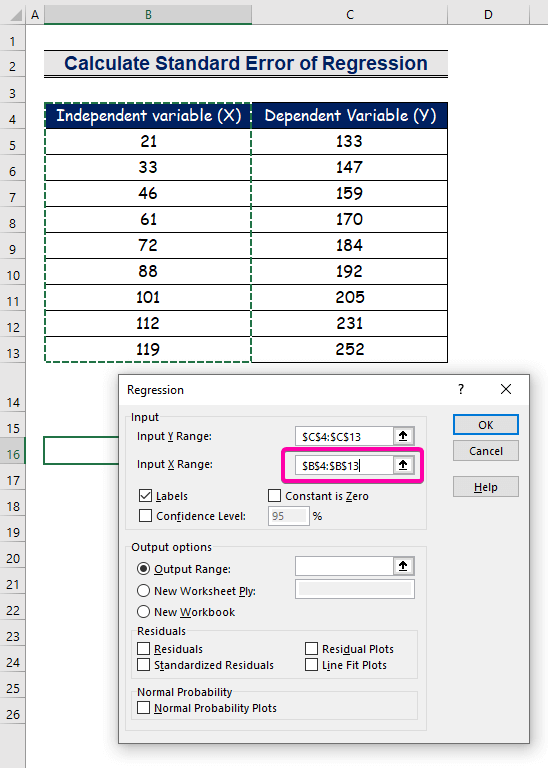
- Upang makuha ang resulta sa gustong lokasyon, pumili ng anumang cell ( B16 ) para sa Saklaw ng Output .
- Sa wakas, i-click ang OK .

Magbasa Pa: Paano Kalkulahin ang Karaniwang Error ng Proporsyon sa Excel (na may Madaling Hakbang)
Hakbang 3: Alamin ang Karaniwang Error
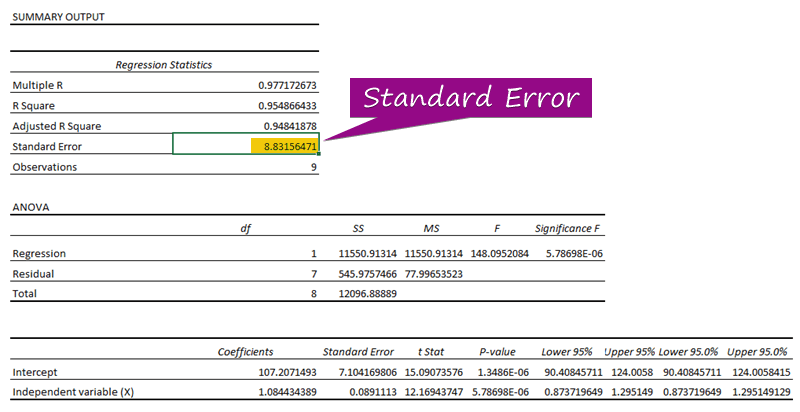
- Mula sa ang pagsusuri ng regression, maaari mong makuha ang halaga ng ang karaniwang error ( 3156471 ).
Magbasa Nang Higit Pa: Paano para Maghanap ng Natitirang Karaniwang Error sa Excel (2 Madaling Paraan)
Hakbang 4: Plot Regression Model Chart
- Una, mag-click sa Insert tab.
- Mula sa Charts grupo, piliin ang Scatter chart.
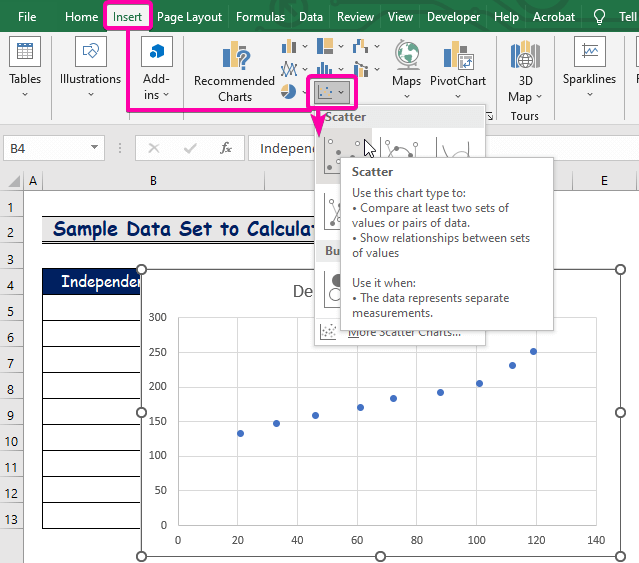
- I-right click sa isa sapuntos.
- Mula sa mga opsyon, piliin ang opsyong Magdagdag ng trendline .
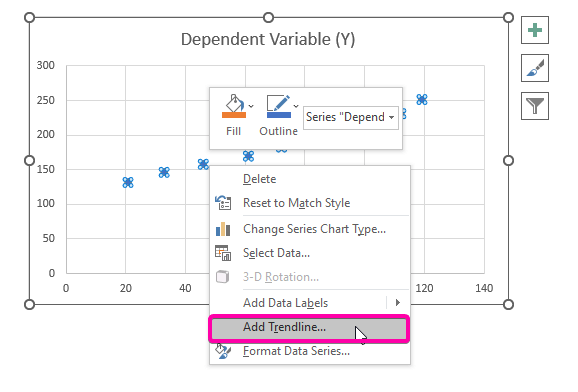
- Samakatuwid, ang iyong<1 Ang> regression analysis chart ay i-plot gaya ng ipinapakitang larawan sa ibaba.

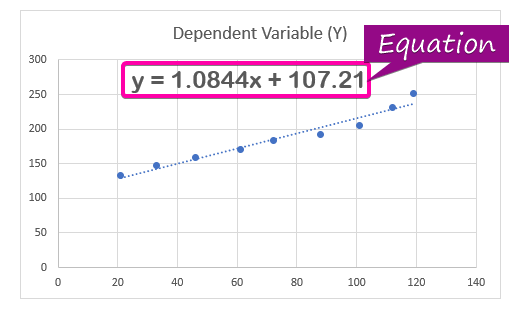
- Upang ipakita ang regression analysis equation, i-click ang Display equation sa Chart na opsyon mula sa Format Trendline.

- Bilang resulta, ang equation ( y = 1.0844x + 107.21 ) ng regression analysis lalabas sa chart.
Mga Tala:
Maaari mong kalkulahin ang pagkakaiba sa pagitan ng mga hinulaang halaga at aktwal na mga value mula sa equation ng regression analysis.
Mga Hakbang:
- I-type ang formula upang kumatawan sa regression analysis equation.
=1.0844*B5 + 107.21 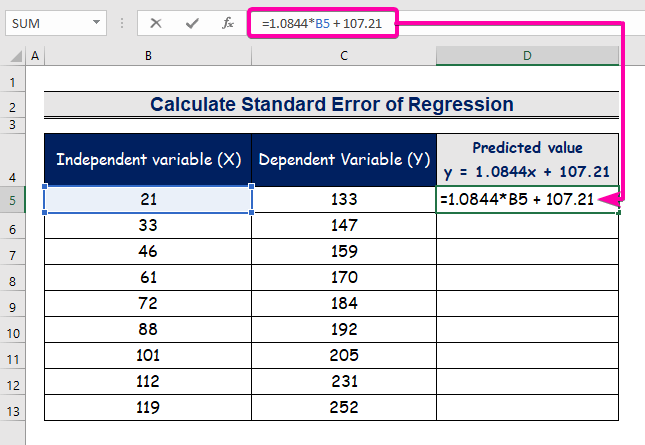
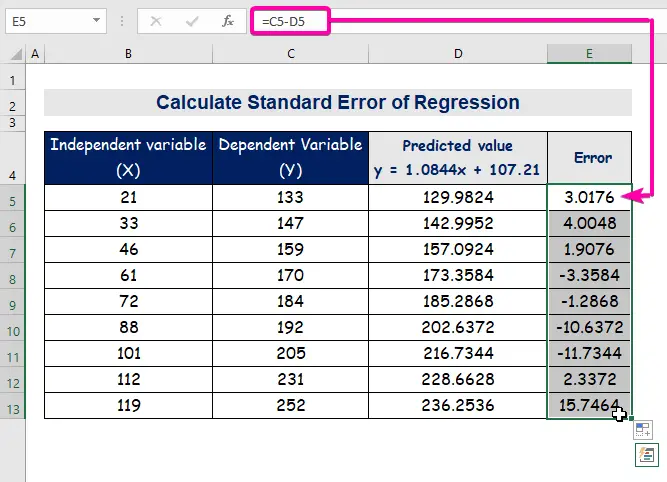
- Samakatuwid, makukuha mo ang unang hinulaang halaga ( 129.9824 ), na naiiba sa aktwal na halaga ( 133 ).

- Gamitin ang AutoFill Tool para i-autofill ang column D .

- Upang kalkulahin ang error, i-type ang sumusunod na formula sa ibawas.
=C5-D5 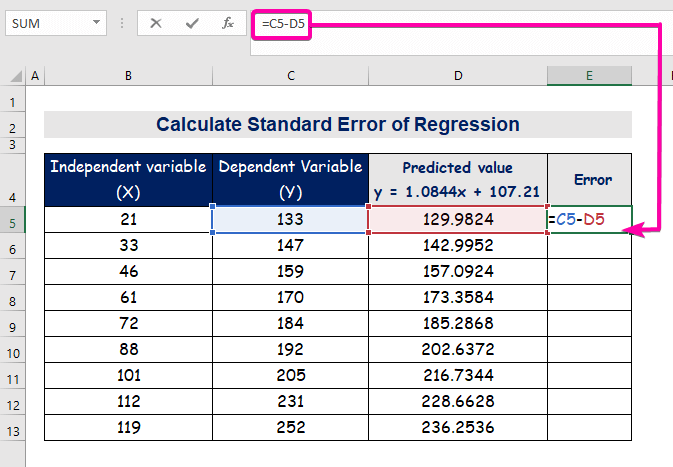
- Sa wakas, auto-fill column E upang mahanap ang mga halaga ng error.
Magbasa Pa: Paano Kalkulahin ang Standard Error ng Regression Slope sa Excel
Ang Interpretasyon ng Pagsusuri ng Regression sa Excel
1. Standard Error
Makikita natin mula sa equation ng regression analysis na palaging may pagkakaiba o error sa pagitan ng hinulaang at aktwal na mga halaga. Bilang resulta, dapat nating kalkulahin ang average na paglihis ng mga pagkakaiba.
Ang isang karaniwang error ay kumakatawan sa average na error sa pagitan ng hinulaang halaga at aktwal na halaga. Natuklasan namin ang 8.3156471 bilang karaniwang error sa aming halimbawang modelo ng regression. Ipinapahiwatig nito na mayroong pagkakaiba sa pagitan ng hinulaang at aktwal na mga halaga, na maaaring mas malaki kaysa sa karaniwang error ( 15.7464 ) o mas mababa kaysa sa karaniwang error ( 4.0048 ). Gayunpaman, ang aming average na error ay magiging 8.3156471 , na siyang karaniwang error .
Bilang resulta, ang layunin ng modelo ay bawasan ang karaniwang error. Ang mas mababa ang karaniwang error, mas tumpak ang modelo.
2. Coefficients
Ang regression coefficient ay sinusuri ang mga tugon ng hindi kilalang halaga. Sa regression equation ( y = 1.0844x + 107.21 ), 1.0844 ay ang coefficient , x ay ang predictor independent variable, 107.21 ang constant, at y <9 Ang> ay ang value ng tugon para sa x .
- Ang isang positive coefficient ay hinuhulaan na mas mataas ang koepisyent, mas mataas ang tugonvariable. Nagsasaad ito ng proporsyonal relasyon.
- Ang negatibong koepisyent ay hinuhulaan na kapag mas mataas ang koepisyent, mas mababa ang mga halaga ng tugon. Ito ay nagsasaad ng disproportional relasyon.
3. P-Values
Sa regression analysis, p- ang mga value at coefficient ay nagtutulungan upang ipaalam sa iyo kung ang mga ugnayan sa iyong modelo ay may kaugnayan sa istatistika at kung ano ang mga ugnayang iyon. Ang null hypothesis na ang independent variable ay walang link sa dependent variable ay sinusubok gamit ang p-value para sa bawat independent variable. Walang link sa pagitan ng mga pagbabago sa independent variable at mga variation sa dependent variable kung walang ugnayan.
- Ang iyong sample na data ay nagbibigay ng sapat na suporta para falsify ang null hypothesis para sa buong populasyon kung ang p-value para sa isang variable ay mas mababa kaysa sa iyong significance threshold. Sinusuportahan ng iyong ebidensya ang ideya ng isang di-zero na ugnayan . Sa antas ng populasyon, ang mga pagbabago sa independent variable ay naka-link sa mga pagbabago sa dependent variable.
- Isang p-value mas malaki kaysa sa antas ng kahalagahan, sa magkabilang panig , ay nagmumungkahi na ang iyong sample ay may hindi sapat na patunay upang matiyak na mayroong hindi zero na ugnayan .
Dahil ang kanilang p-values ( 5.787E-06 , 1.3E-06 ) ay mas mababa kaysa sa significant value ( 5.787E-06 ), ang Independent Variable (X) at Intercept ay istatistikong makabuluhan , tulad ng nakikita sa regression output na halimbawa.
4. R-Squared Values
Para sa mga modelo ng linear regression, ang R-squared ay isang pagsusukat sa pagiging kumpleto . Ipinapakita ng ratio na ito ang porsyento ng pagkakaiba sa dependent variable na isinasaalang-alang ng mga independent factor kapag pinagsama-sama. Sa isang madaling gamiting 0–100 na porsyentong sukat, binibilang ng R-squared ang lakas ng koneksyon sa pagitan ng iyong modelo at ng dependent variable. Ang
Ang halaga ng R2 ay isang sukatan kung gaano kahusay ang pagkakatugma ng modelo ng regression sa iyong data. Ang mas mataas ang number , ang mas mahusay magagawa ang modelo.
Konklusyon
Sana ang artikulong ito ay nagbigay sa iyo ng isang tutorial tungkol sa kung paano kalkulahin ang karaniwang error ng regression sa Excel . Ang lahat ng mga pamamaraang ito ay dapat matutunan at mailapat sa iyong dataset. Tingnan ang workbook ng pagsasanay at subukan ang mga kasanayang ito. Kami ay naudyukan na patuloy na gumawa ng mga tutorial na tulad nito dahil sa iyong mahalagang suporta.
Mangyaring makipag-ugnayan sa amin kung mayroon kang anumang mga tanong. Gayundin, huwag mag-atubiling mag-iwan ng mga komento sa seksyon sa ibaba.
Kami, ang Exceldemy Team, ay palaging tumutugon sa iyong mga query.
Manatili sa amin at patuloy na matuto.
