
Оглавление
Мы используем регрессионный анализ когда у нас есть данные о двух переменных из двух разных источников и мы хотим построить взаимосвязь между ними. Регрессионный анализ дает нам линейную модель, позволяющую предсказать возможные результаты. По очевидным причинам между предсказанными и фактическими значениями будут некоторые различия. В результате, мы рассчитать стандартную ошибку с помощью регрессионной модели, которая представляет собой среднюю ошибку между предсказанными и фактическими значениями. В этом учебном пособии мы покажем вам, как рассчитать стандартную ошибку регрессионного анализа в Excel .
Скачать Практическое пособие
Скачайте эту рабочую тетрадь для тренировок, чтобы заниматься во время чтения этой статьи.
Стандартная ошибка регрессии.xlsx4 простых шага для вычисления стандартной ошибки регрессии в Excel
Предположим, что у вас есть набор данных с независимая переменная ( X ) и зависимая переменная ( Y ) Как видите, между ними нет существенной связи. Но мы хотим построить такую связь. В результате мы будем использовать Регрессионный анализ Мы рассчитаем стандартную ошибку между двумя переменными с помощью регрессионного анализа. Во второй половине статьи мы рассмотрим некоторые параметры регрессионной модели, чтобы помочь вам интерпретировать ее.

Шаг 1: Применение команды анализа данных для создания регрессионной модели
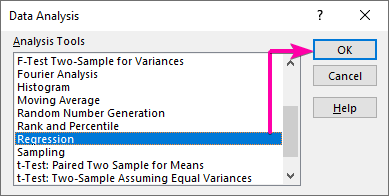
- Во-первых, зайдите в Данные вкладку и нажмите на Анализ данных командование.

- Из Анализ данных в поле списка выберите Регрессия вариант.
- Затем нажмите OK .
Шаг 2: Вставьте входной и выходной диапазон в блок регрессии
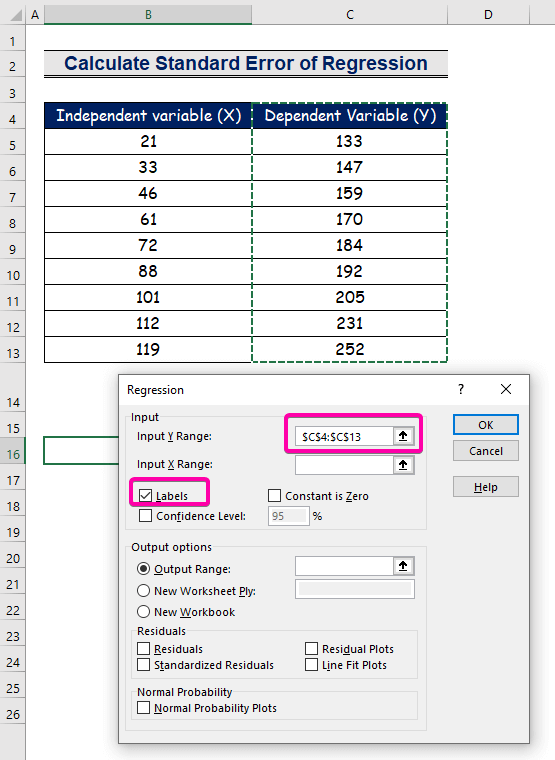
- Для Входной диапазон Y , выберите диапазон C4:C13 с заголовком.
- Нажмите на Ярлыки флажок.
- Выберите диапазон B4:B13 для Вход X Диапазон .
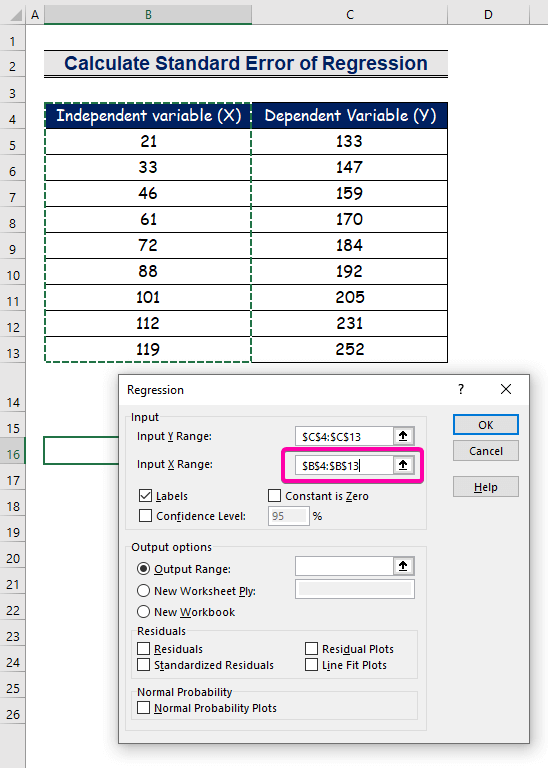
- Чтобы получить результат в предпочтительном месте, выберите любую ячейку ( B16 ) для Выходной диапазон .
- Наконец, нажмите OK .

Читать далее: Как рассчитать стандартную ошибку пропорции в Excel (с помощью простых шагов)
Шаг 3: Определите стандартную ошибку
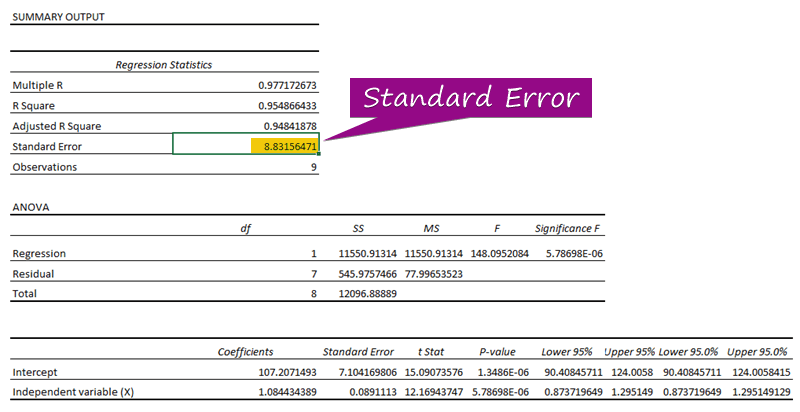
- Из регрессионного анализа можно получить значение стандартной ошибки ( 3156471 ).
Читать далее: Как найти остаточную стандартную ошибку в Excel (2 простых метода)
Шаг 4: Построить график регрессионной модели
- Во-первых, нажмите на Вставка вкладка.
- Из Графики группу, выберите Разброс диаграмма.
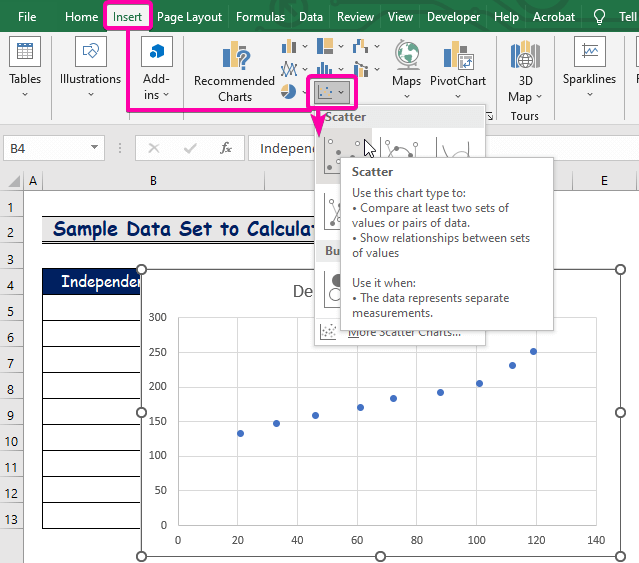
- Щелкните правой кнопкой мыши над одной из точек.
- Из предложенных вариантов выберите Добавить линию тренда вариант.
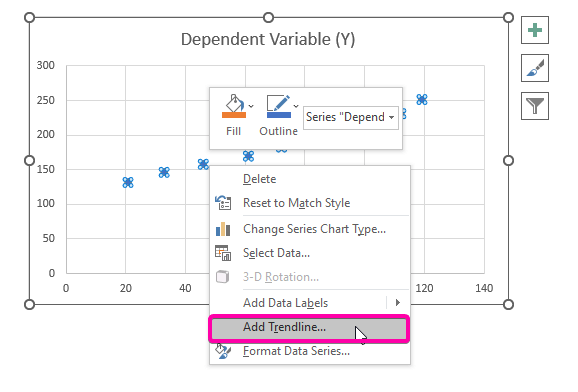
- Поэтому ваш регрессионный анализ график будет построен так, как показано на рисунке ниже.

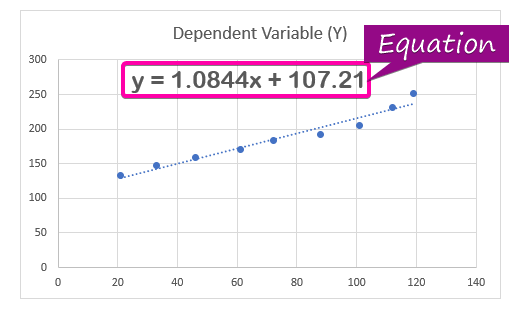
- Чтобы отобразить регрессионный анализ уравнение, нажмите на Отображение уравнения на графике опция из Формат Trendline.

- В результате уравнение ( y = 1.0844x + 107.21 ) регрессионного анализа появится на графике.
Примечания:
Вы можете вычислить разницу между прогнозируемыми и фактическими значениями из уравнения регрессионного анализа.
Шаги:
- Введите формулу для представления уравнения регрессионного анализа.
=1.0844*B5 + 107.21 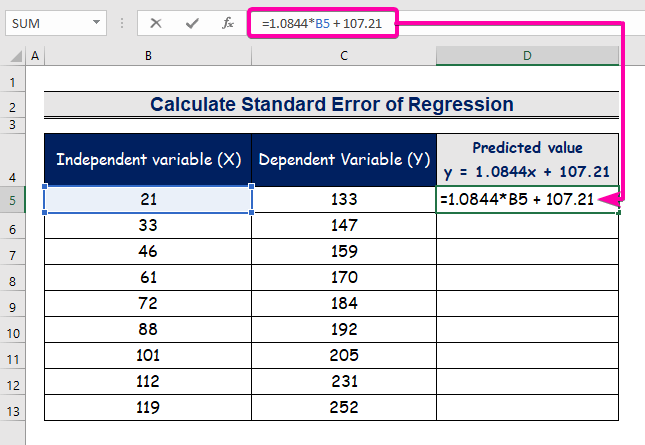
- Таким образом, вы получите первое прогнозируемое значение ( 129.9824 ), которое отличается от фактического значения ( 133 ).

- Используйте Инструмент автозаполнения для автоматического заполнения колонки D .

- Чтобы вычислить ошибку, введите следующую формулу для вычитания.
=C5-D5 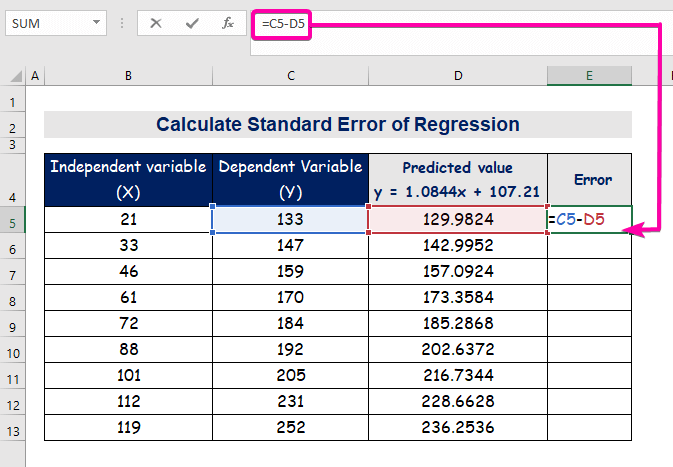
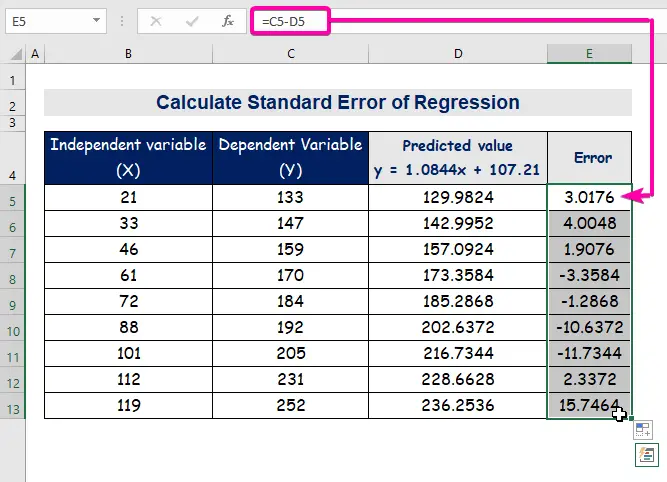
- Наконец, автозаполнение колонки E чтобы найти значения ошибок.
Читать далее: Как рассчитать стандартную ошибку наклона регрессии в Excel
Интерпретация регрессионного анализа в Excel
1. Стандартная ошибка
Из уравнения регрессионного анализа видно, что между прогнозируемыми и фактическими значениями всегда есть разница или ошибка. В результате мы должны вычислить среднее отклонение разницы.
A стандартная ошибка представляет собой среднюю ошибку между предсказанным значением и фактическим значением. Мы обнаружили, что 8.3156471 как стандартная ошибка в нашем примере регрессионной модели. Это указывает на то, что существует разница между прогнозируемым и фактическим значениями, которая может быть больше, чем стандартная ошибка ( 15.7464 ) или меньше, чем стандартная ошибка ( 4.0048 ). Однако наш средняя ошибка будет 8.3156471 , который является стандартная ошибка .
В результате целью модели является уменьшение стандартной ошибки. ниже стандартная ошибка, тем больше точный модель.
2. Коэффициенты
Коэффициент регрессии оценивает ответы неизвестных величин. В уравнении регрессии ( y = 1.0844x + 107.21 ), 1.0844 это коэффициент , x является предиктором независимой переменной, 107.21 постоянная, и y значение ответа для x .
- A положительный коэффициент предсказывает, что чем выше коэффициент, тем выше переменная отклика. Это указывает на пропорциональный отношения.
- A отрицательный коэффициент предсказывает, что чем выше коэффициент, тем ниже значения ответа. Это указывает на непропорционально отношения.
3. P-значения
В регрессионном анализе, p-values и коэффициенты взаимодействуют, чтобы сообщить вам, являются ли корреляции в вашей модели статистически значимыми и каковы эти связи. нулевая гипотеза что независимая переменная не имеет связи с зависимой переменной, проверяется с помощью теста p-value для каждой независимой переменной. При отсутствии корреляции между изменениями независимой переменной и изменениями зависимой переменной нет связи.
- Данные вашей выборки дают достаточную поддержку для фальсифицировать нулевую гипотезу для всей популяции, если p-value для переменной является меньше чем ваш порог значимости. Ваши доказательства поддерживают понятие ненулевая корреляция На популяционном уровне изменения независимой переменной связаны с изменениями зависимой переменной.
- A p-value больше чем уровень значимости, по обе стороны, говорит о том, что ваша выборка имеет недостаточное доказательство чтобы установить, что ненулевая корреляция существует.
Потому что их p-values ( 5.787E-06 , 1.3E-06 ) являются меньше чем существенное значение ( 5.787E-06 ), the Независимая переменная (X) и Перехват являются статистически значимый как видно из примера вывода регрессии.
4. Значения R-квадрат
Для моделей линейной регрессии, R-квадрат это измерение полноты Это соотношение показывает процент дисперсии в зависимой переменной, на которую независимые факторы влияют в совокупности. На удобном 0-100 процентная шкала, R-квадрат количественно оценивает прочность связи между вашей моделью и зависимой переменной.
Сайт R2 это показатель того, насколько хорошо регрессионная модель соответствует вашим данным. выше сайт номер , the лучше выполнимость модели.
Заключение
Надеюсь, эта статья помогла вам разобраться в том, как рассчитать стандартную ошибку регрессии в Excel Все эти процедуры должны быть изучены и применены к вашему набору данных. Посмотрите на рабочую тетрадь и проверьте эти навыки на практике. Мы мотивированы продолжать создавать подобные учебники благодаря вашей ценной поддержке.
Пожалуйста, свяжитесь с нами, если у вас возникли вопросы. Также не стесняйтесь оставлять комментарии в разделе ниже.
Мы Exceldemy Команда всегда быстро реагирует на ваши запросы.
Оставайтесь с нами и продолжайте учиться.
