
Содржина
Ние користиме регресивна анализа кога имаме податоци од две променливи од два различни извори и сакаме да изградиме врска меѓу нив. Регресивната анализа ни дава линеарен модел кој ни овозможува да ги предвидиме можните исходи. Ќе има некои разлики помеѓу предвидените и вистинските вредности од очигледни причини. Како резултат на тоа, ние ја пресметуваме стандардната грешка користејќи го регресиониот модел, што е просечна грешка помеѓу предвидените и вистинските вредности. Во ова упатство, ќе ви покажеме како да ја пресметате стандардната грешка на регресиската анализа во Excel .
Преземете ја работната книга за вежбање
Преземете ја оваа работна книга за вежбање за да вежбате додека сте читајќи ја оваа статија.
Стандардна грешка во регресијата.xlsx
4 едноставни чекори за пресметување стандардна грешка на регресија во Excel
Претпоставете дека имате збир на податоци со независна променлива ( X ) и зависна променлива ( Y ) . Како што можете да видите, тие немаат значајна врска. Но, ние сакаме да изградиме еден. Како резултат на тоа, ќе користиме Регресивна анализа за да создадеме линеарна врска помеѓу двете. Ќе ја пресметаме стандардната грешка помеѓу двете променливи користејќи регресивна анализа. Ќе разгледаме некои од параметрите на моделот за регресија во втората половина од статијата за да ви помогнеме да го протолкувате.

Чекор 1: Применете ја командата за анализа на податоци наНаправете регресивен модел
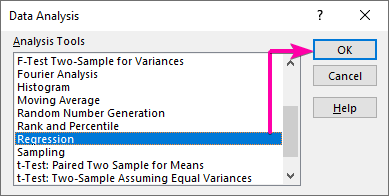
- Прво, одете во табулаторот Податоци и кликнете на Анализа на податоци команда.

- Од полето за листа Анализа на податоци , изберете го Регресија опција.
- Потоа, кликнете OK .
Чекор 2: Вметнете го опсегот на влез и излез во полето за регресија
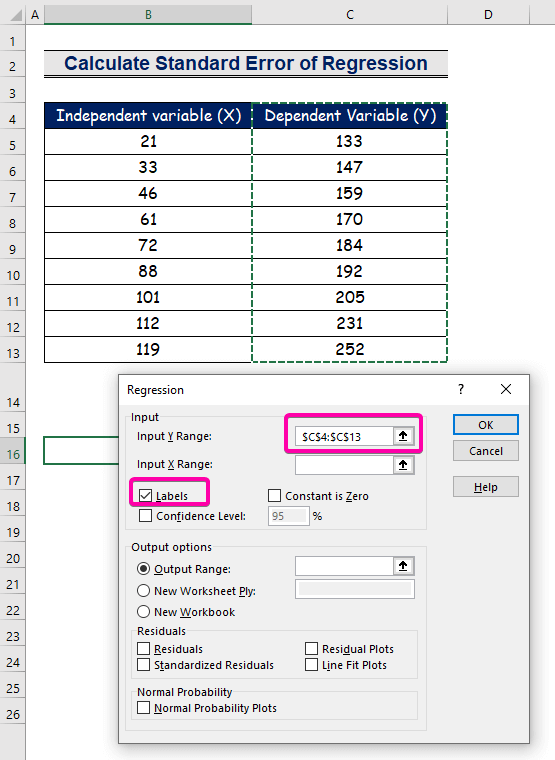
- За Влезен опсег Y , изберете го опсегот C4:C13 со заглавието.
- Кликнете на полето за избор Етикети .
- Изберете го опсегот B4:B13 за Влезен опсег X .
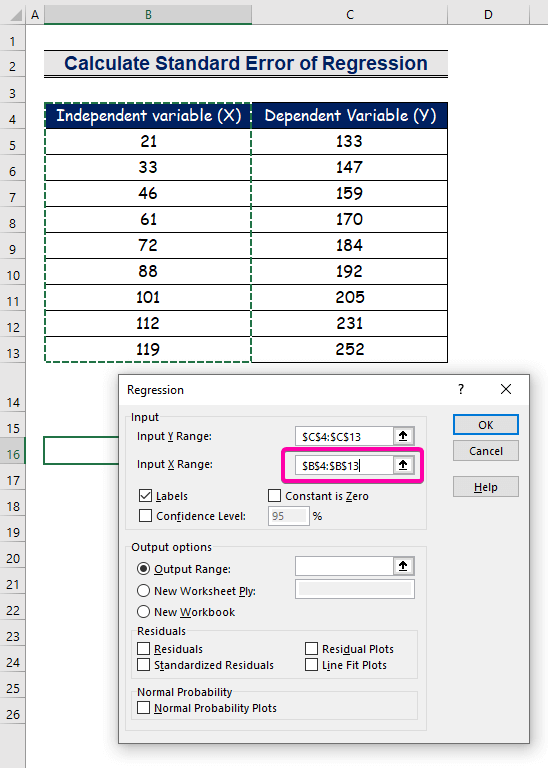
- За да го добиете резултатот на претпочитаната локација, изберете која било ќелија ( B16 ) за Излезен опсег .
- Конечно, кликнете OK .

Прочитајте повеќе: Како да се пресмета стандардната грешка на пропорцијата во Excel (со лесни чекори)
Чекор 3: дознајте стандардна грешка
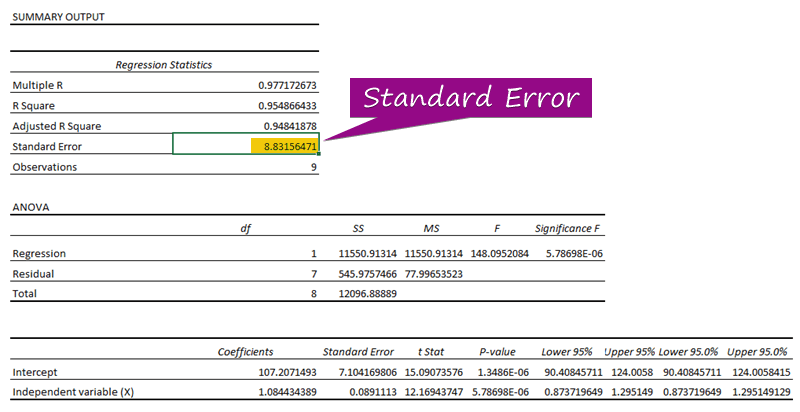
- од на регресивна анализа, можете да ја добиете вредноста на стандардната грешка ( 3156471 ).
Прочитај повеќе: Како за да пронајдете преостаната стандардна грешка во Excel (2 лесни методи)
Чекор 4: Графикон на моделот за регресија
- Прво, кликнете на Вметни таб.
- Од групата Табели , изберете ја Scatter табела.
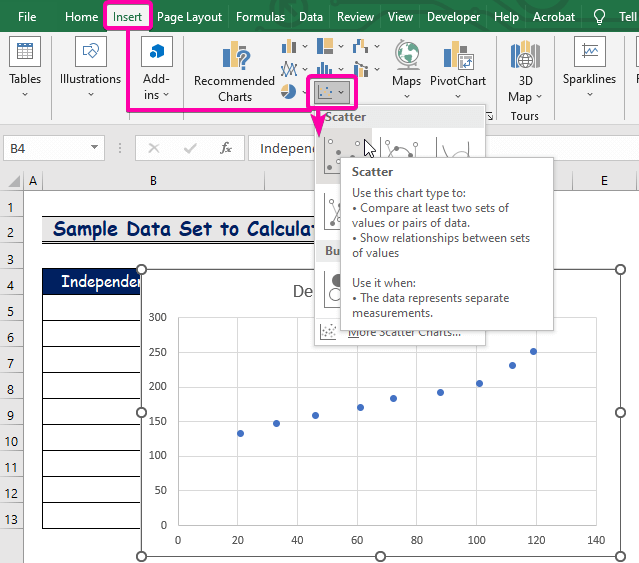
- Десен-клик над еден одпоени.
- Од опциите, изберете ја опцијата Додај тренд линија .
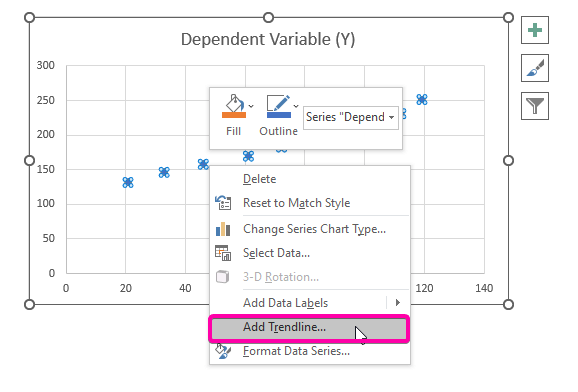
- Затоа, вашата анализа на регресија графиконот ќе биде нацртан како сликата прикажана подолу.

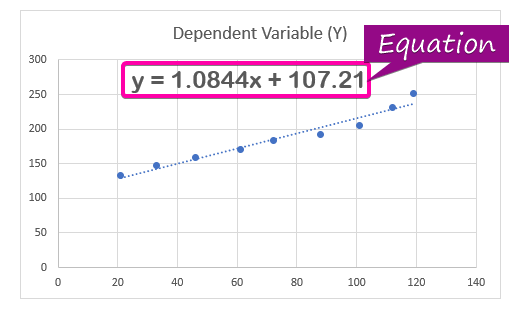
- За прикажување на регресивна анализа равенката, кликнете на опцијата Прикажи ја равенката на графикон од Форматирај тренд линија.

- Како резултат на тоа, равенката ( y = 1,0844x + 107,21 ) на регресивната анализа ќе се појави на графиконот.
Забелешки:
Можете да ја пресметате разликата помеѓу предвидените вредности и вистинските вредности од равенката на регресивна анализа.
Чекори:
- Впишете ја формулата за да ја претставите равенката за регресивна анализа.
=1.0844*B5 + 107.21 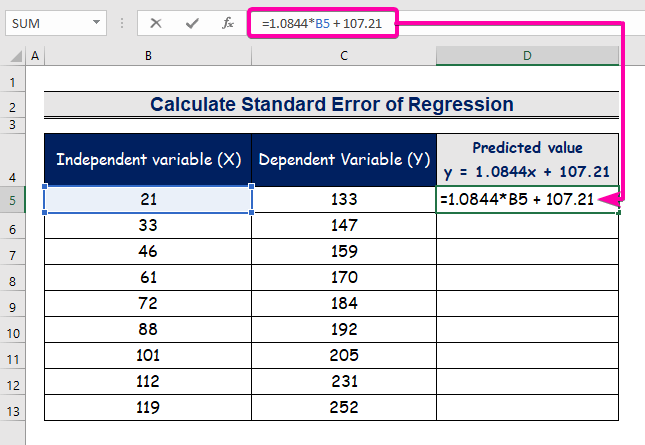
- Затоа, ќе ја добиете првата предвидена вредност ( 129,9824 ), што се разликува од вистинската вредност ( 133 ).

- Користете го Алатка за автоматско пополнување за автоматско пополнување колона D .

- За да ја пресметате грешката, напишете ја следнава формула за одзема.
=C5-D5 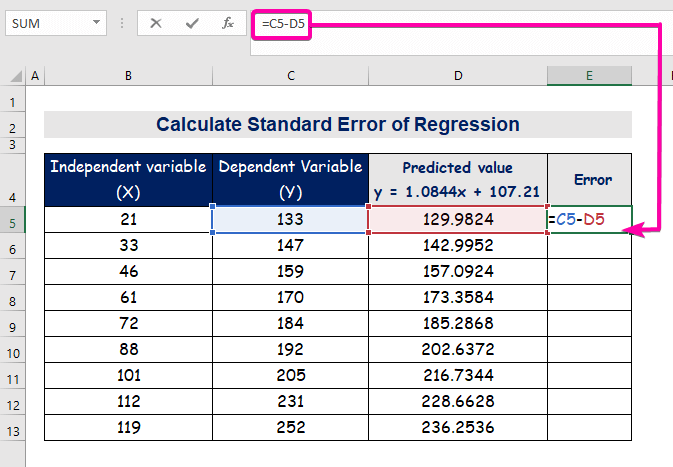
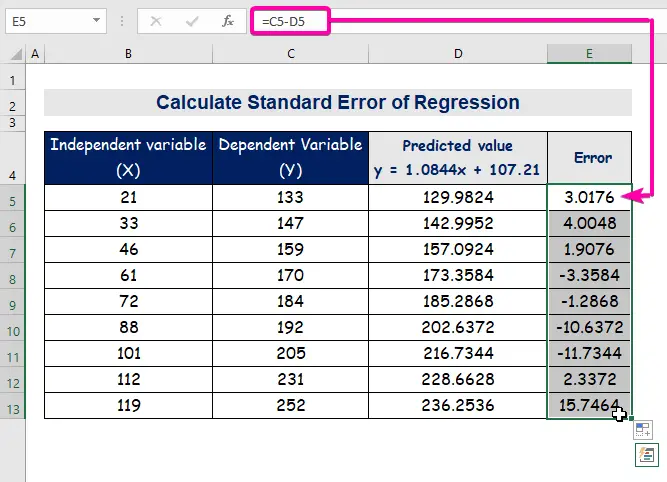
- Конечно, автоматско пополнување колона E да ги пронајдете вредностите на грешката.
Прочитајте повеќе: Како да се пресмета стандардната грешка на наклонот на регресија во Excel
Интерпретацијата на регресивната анализа во Excel
1. Стандардна грешка
Можеме да видиме од равенката за регресивна анализа дека секогаш постои разлика или грешка помеѓу предвидените и вистинските вредности. Како резултат на тоа, мораме да го пресметаме просечното отстапување на разликите.
А стандардна грешка ја претставува просечната грешка помеѓу предвидената вредност и вистинската вредност. Откривме 8.3156471 како стандардна грешка во нашиот примерен регресивен модел. Тоа покажува дека постои разлика помеѓу предвидените и вистинските вредности, што може да биде поголема од стандардната грешка ( 15,7464 ) или помала од стандардна грешка ( 4.0048 ). Сепак, нашата просечна грешка ќе биде 8.3156471 , што е стандардна грешка .
Како резултат на тоа, целта на моделот е да ја намали стандардната грешка. Колку помал стандардната грешка, толку поточен моделот.
2. Коефициенти
Коефициентот на регресија го оценува одговори на непознати вредности. Во регресивната равенка ( y = 1,0844x + 107,21 ), 1,0844 е коефициентот , x е независна променлива на предвидување, 107.21 е константата и y е вредноста на одговорот за x .
- А позитивниот коефициент предвидува дека колку е поголем коефициентот, толку е поголем одговоротпроменлива. Тоа укажува на пропорционална врска.
- А негативен коефициент предвидува дека колку е поголем коефициентот, толку се помали вредностите на одговорот. Тоа укажува на несразмерна врска.
3. P-вредности
Во регресивна анализа, p- вредностите и коефициентите соработуваат за да ве информираат дали корелациите во вашиот модел се статистички релевантни и какви се тие односи. нултата хипотеза дека независната променлива нема врска со зависната променлива се тестира со помош на p-вредноста за секоја независна променлива. Не постои врска помеѓу промените во независната променлива и варијациите во зависната променлива ако нема корелација.
- Вашите податоци од примерокот даваат доволно поддршка за фалсификување нултата хипотеза за целосна популација ако p-вредноста за променлива е помалку од вашиот праг на значајност. Вашиот доказ ја поддржува идејата за ненулта корелација . На ниво на население, промените во независната променлива се поврзани со промените во зависната променлива.
- A p-вредност поголема од нивото на значајност, од двете страни , сугерира дека вашиот примерок има недоволен доказ за да се утврди дека постои ненулта корелација .
Бидејќи нивните p-вредности ( 5.787E-06 , 1.3E-06 ) се помалку од значајната вредност ( 5.787E-06 ), Независната променлива (X) и Пресекот се статистички значајни , како што се гледа во примерот за излез со регресија.
4. R-квадратни вредности
За моделите на линеарна регресија, R-квадрат е мерење на комплетноста . Овој сооднос го покажува процентот на варијанса во зависната променлива што независните фактори го земаат предвид кога се земаат заедно. На практична скала 0–100 проценти, R-квадрат ја квантифицира јачината на врската помеѓу вашиот модел и зависната променлива.
Вредноста R2 е мерка за тоа колку добро регресиониот модел одговара на вашите податоци. Колку е поголем бројот , толку е подобар изводлив моделот.
Заклучок
Се надевам дека оваа статија ви даде упатство за тоа како да се пресмета стандардната грешка на регресија во Excel . Сите овие постапки треба да се научат и да се применат во вашата база на податоци. Погледнете ја работната книга за вежбање и тестирајте ги овие вештини. Мотивирани сме да продолжиме да правиме вакви упатства поради вашата вредна поддршка.
Ве молиме контактирајте со нас ако имате какви било прашања. Исто така, слободно оставете коментари во делот подолу.
Ние, тимот на Exceldemy , секогаш одговараме на вашите прашања.
Останете со нас и продолжете да учите.
