
Змест
Мы выкарыстоўваем рэгрэсійны аналіз , калі маем даныя дзвюх зменных з дзвюх розных крыніц і хочам пабудаваць сувязь паміж імі. Рэгрэсійны аналіз дае нам лінейную мадэль, якая дазваляе прадказаць магчымыя вынікі. Па зразумелых прычынах паміж прагназаванымі і фактычнымі значэннямі будуць некаторыя адрозненні. У выніку мы разлічваем стандартную памылку з дапамогай рэгрэсійнай мадэлі, якая ўяўляе сабой сярэднюю памылку паміж прадказанымі і фактычнымі значэннямі. У гэтым уроку мы пакажам вам, як разлічыць стандартную памылку рэгрэсійнага аналізу ў Excel .
Спампуйце сшытак для практыкаванняў
Спампуйце гэты сшытак для практыкаванняў, пакуль вы чытаючы гэты артыкул.
Стандартная памылка рэгрэсіі.xlsx
4 простыя крокі для разліку стандартнай памылкі рэгрэсіі ў Excel
Выкажам здагадку, што ў вас ёсць набор даных з незалежнай зменнай ( X ) і залежнай зменнай ( Y ) . Як бачыце, істотных адносін у іх няма. Але мы хочам пабудаваць адзін. У выніку мы будзем выкарыстоўваць рэгрэсійны аналіз для стварэння лінейнай залежнасці паміж імі. Мы вылічым стандартную памылку паміж дзвюма зменнымі з дапамогай рэгрэсійнага аналізу. Мы разгледзім некаторыя параметры рэгрэсійнай мадэлі ў другой палове артыкула, каб дапамагчы вам яе інтэрпрэтаваць.

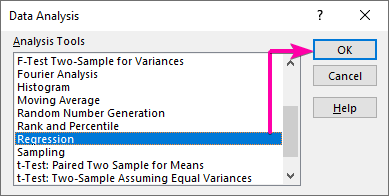
Крок 1: Ужыце каманду аналізу даных даСтварыце мадэль рэгрэсіі
- Спачатку перайдзіце на ўкладку Даныя і націсніце Аналіз даных каманда.

- У спісе Аналіз даных выберыце Параметр рэгрэсіі .
- Затым націсніце ОК .
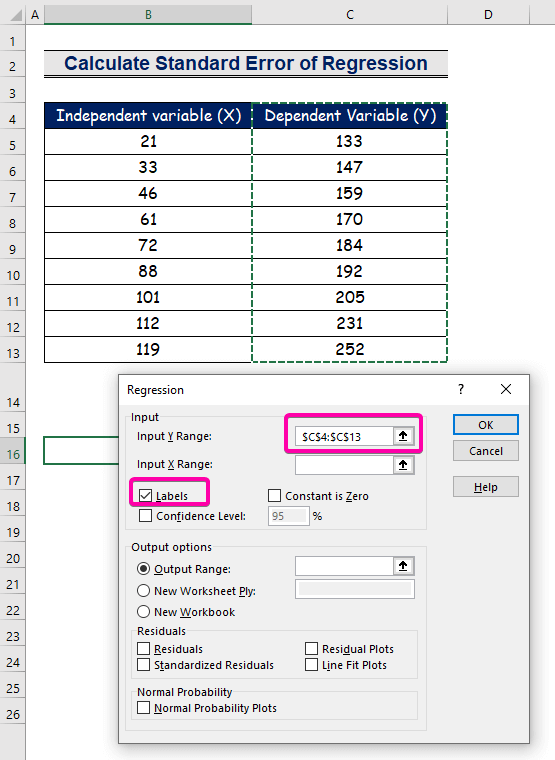
Крок 2: Устаўце ўваходны і выхадны дыяпазон у поле рэгрэсіі
- Для Уваходны дыяпазон Y выберыце дыяпазон C4:C13 з загалоўкам.
- Націсніце на поле Цэтлікі .
- Выберыце дыяпазон B4:B13 для Дыяпазон уводу X .
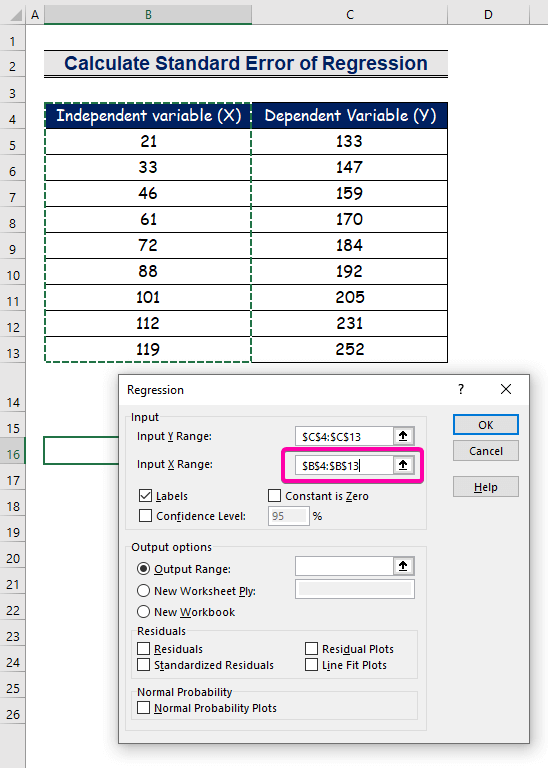
- Каб атрымаць вынік у патрэбным месцы, абярыце любую ячэйку ( B16 ) для Дыяпазон вываду .
- Нарэшце націсніце ОК .

Чытаць далей: Як разлічыць стандартную памылку прапорцыі ў Excel (з дапамогай простых крокаў)
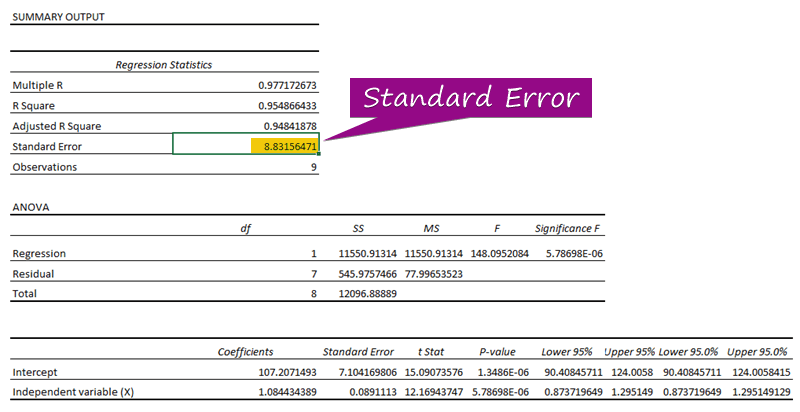
Крок 3: Даведайцеся стандартную памылку
- З Рэгрэсійная аналіз, вы можаце атрымаць значэнне стандартная памылка ( 3156471 ).
Дадатковая інфармацыя: Як каб знайсці рэшткавую стандартную памылку ў Excel (2 простыя метады)
Крок 4: Пабудуйце дыяграму рэгрэсійнай мадэлі
- Спачатку націсніце Уставіць укладка.
- З групы Дыяграмы выберыце Тэб-дыяграму .
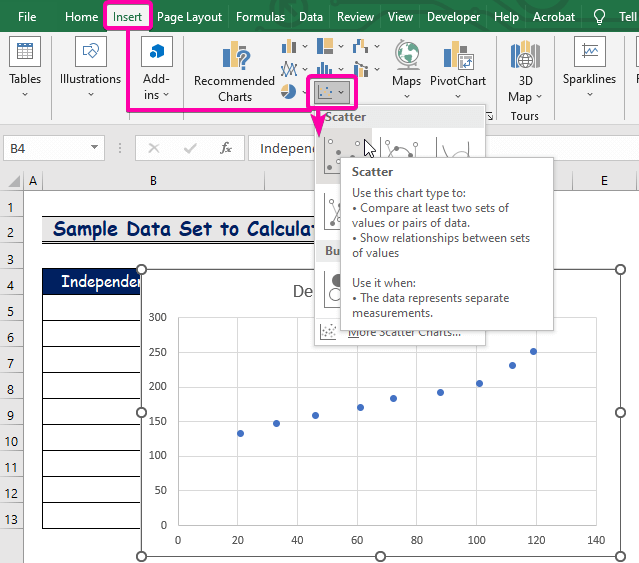
- Пстрыкніце правай кнопкай мышы па адным зпунктаў.
- З параметраў выберыце опцыю Дадаць лінію трэнду .
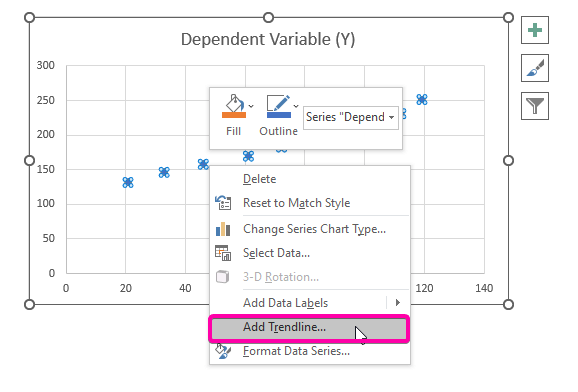
- Такім чынам, ваш Дыяграма рэгрэсійнага аналізу будзе пабудавана, як паказана ніжэй.

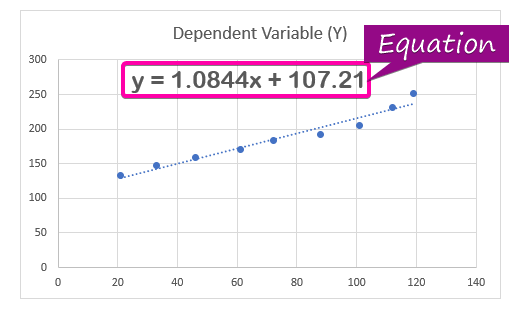
- Для адлюстравання раўнанне рэгрэсійнага аналізу , націсніце опцыю Паказаць ураўненне на дыяграме з Фарматаваць лінію трэнду.

- У выніку ўраўненне ( y = 1,0844x + 107,21 ) рэгрэсійнага аналізу з'явіцца ў дыяграме.
Заўвагі:
Вы можаце разлічыць розніцу паміж прагназуемымі і фактычнымі значэннямі значэнні з ураўнення рэгрэсійнага аналізу.
Этапы:
- Увядзіце формулу для прадстаўлення ўраўнення рэгрэсійнага аналізу.
=1.0844*B5 + 107.21 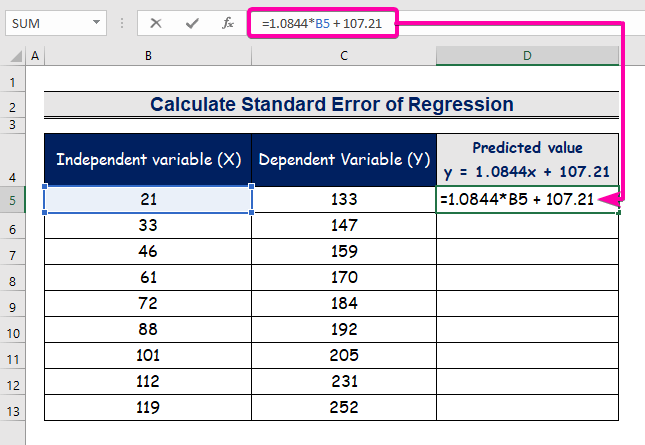
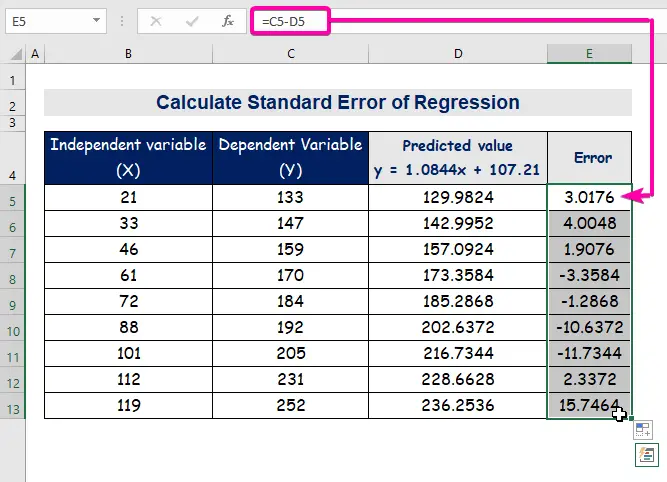
- Такім чынам, вы атрымаеце першае прадказанае значэнне ( 129,9824 ), якое адрозніваецца ад фактычнага значэння ( 133 ).

- Выкарыстоўвайце Інструмент аўтазапаўнення да аўтаматычнага запаўнення слупка D .

- Каб вылічыць памылку, увядзіце наступную формулу адняць.
=C5-D5 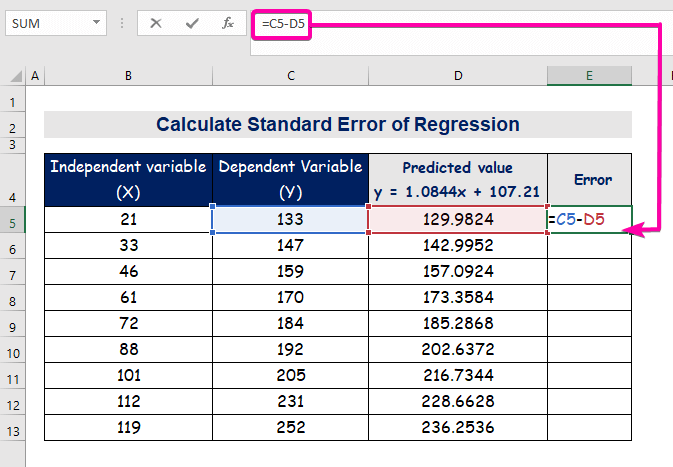
- Нарэшце, слупок аўтазапаўнення E каб знайсці значэнні памылак.
Дадатковая інфармацыя: Як разлічыць стандартную памылку нахілу рэгрэсіі ў Excel
Інтэрпрэтацыя рэгрэсійнага аналізу ў Excel
1. Стандартная памылка
З ураўнення рэгрэсійнага аналізу мы бачым, што паміж прадказанымі і фактычнымі значэннямі заўсёды ёсць розніца або памылка. У выніку мы павінны вылічыць сярэдняе адхіленне розніц.
Стандартная памылка ўяўляе сабой сярэднюю памылку паміж прадказаным значэннем і фактычным значэннем. Мы выявілі 8,3156471 як стандартную памылку ў нашым прыкладзе рэгрэсійнай мадэлі. Гэта паказвае на тое, што існуе розніца паміж прадказанымі і фактычнымі значэннямі, якая можа быць большай за стандартную памылку ( 15,7464 ) або меншай за стандартная памылка ( 4,0048 ). Аднак наша сярэдняя памылка будзе 8,3156471 , што з'яўляецца стандартнай памылкай .
У выніку мэта мадэлі - паменшыць стандартную памылку. Чым менш стандартная памылка, тым больш дакладная мадэль.
2. Каэфіцыенты
Каэфіцыент рэгрэсіі ацэньвае адказы невядомых значэнняў. У раўнанні рэгрэсіі ( y = 1,0844x + 107,21 ), 1,0844 з'яўляецца каэфіцыентам , x з'яўляецца незалежнай зменнай прадказальніка, 107.21 з'яўляецца канстантай і y гэта значэнне адказу для x .
- станоўчы каэфіцыент прадказвае, што чым вышэй каэфіцыент, тым вышэй адказзменная. Гэта паказвае на прапарцыйную сувязь.
- Адмоўны каэфіцыент прадказвае, што чым вышэйшы каэфіцыент, тым меншыя значэнні адказу. Гэта паказвае на непрапарцыйную сувязь.
3. P-значэнні
У рэгрэсійным аналізе p- значэнні і каэфіцыенты ўзаемадзейнічаюць, каб інфармаваць вас, ці з'яўляюцца карэляцыі ў вашай мадэлі статыстычна актуальнымі і якія гэтыя адносіны. Нулявая гіпотэза пра тое, што незалежная зменная не мае сувязі з залежнай зменнай, правяраецца з дапамогай p-значэння для кожнай незалежнай зменнай. Няма ніякай сувязі паміж зменамі ў незалежнай зменнай і варыяцыямі ў залежнай зменнай, калі няма карэляцыі.
- Вашы ўзорныя дадзеныя даюць дастатковую падтрымку для фальсіфікацыі нулявой гіпотэзы для поўная сукупнасць, калі p-значэнне для зменнай менш за ваш парог значнасці. Вашы доказы пацвярджаюць паняцце ненулявой карэляцыі . На ўзроўні сукупнасці змены незалежнай зменнай звязаны са зменамі залежнай зменнай.
- p-значэнне больш , чым узровень значнасці, з абодвух бакоў , сведчыць аб тым, што ваш узор мае недастатковыя доказы , каб пацвердзіць, што існуе ненулявая карэляцыя .
Таму што іх p-значэнні ( 5,787E-06 , 1,3E-06 ) менш , чым значнае значэнне ( 5.787E-06 ), Незалежная зменная (X) і Intercept з'яўляюцца статыстычна значнымі , як відаць у прыкладзе вываду рэгрэсіі.
4. Значэнні R-квадрата
Для мадэляў лінейнай рэгрэсіі R-квадрат з'яўляецца мераннем паўнаты . Гэты каэфіцыент паказвае працэнт дысперсіі ў залежнай зменнай, якую ўлічваюць незалежныя фактары, узятыя разам. На зручнай 0–100 працэнтнай шкале R-квадрат колькасна вызначае сілу сувязі паміж вашай мадэллю і залежнай зменнай.
Значэнне R2 з'яўляецца мерай таго, наколькі добра мадэль рэгрэсіі адпавядае вашым дадзеным. Чым вышэй лічба , тым лепш выканальная мадэль.
Выснова
Я спадзяюся, што гэты артыкул даў вам падручнік аб тым, як вылічыць стандартную памылку рэгрэсіі ў Excel . Усе гэтыя працэдуры трэба вывучыць і прымяніць да свайго набору даных. Зірніце на практычны сшытак і праверце гэтыя навыкі. Дзякуючы вашай каштоўнай падтрымцы мы матываваныя працягваць ствараць такія падручнікі.
Калі ў вас ёсць якія-небудзь пытанні, звяжыцеся з намі. Таксама не саромейцеся пакідаць каментарыі ў раздзеле ніжэй.
Мы, каманда Exceldemy , заўсёды адказваем на вашы запыты.
Заставайцеся з намі і працягвайце вучыцца.
