
Съдържание
Използваме регресионен анализ когато имаме данни за две променливи от два различни източника и искаме да изградим връзка между тях. Регресионен анализ ни предоставя линеен модел, който ни позволява да прогнозираме възможните резултати. По очевидни причини ще има известни разлики между прогнозираните и действителните стойности. В резултат на това ние изчисляване на стандартната грешка с помощта на регресионния модел, която е средната грешка между прогнозираните и действителните стойности. В този урок ще ви покажем как да изчислите стандартната грешка на регресионния анализ в Excel .
Изтегляне на работна тетрадка за практика
Изтеглете тази учебна тетрадка, за да се упражнявате, докато четете тази статия.
Стандартна грешка на регресията.xlsx4 прости стъпки за изчисляване на стандартната грешка на регресията в Excel
Предполагаме, че имате набор от данни с независима променлива ( X ) и зависима променлива ( Y ) Както виждате, те нямат значима връзка. Но ние искаме да изградим такава. В резултат на това ще използваме Регресионен анализ за да се създаде линейна зависимост между двете променливи. Ще изчислим стандартната грешка между двете променливи, като използваме регресионния анализ. Във втората половина на статията ще разгледаме някои от параметрите на регресионния модел, за да ви помогнем да го интерпретирате.

Стъпка 1: Прилагане на команда за анализ на данни за създаване на регресионен модел
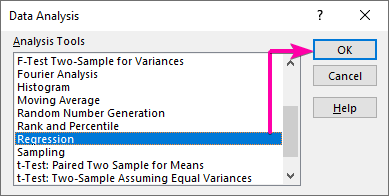
- Първо, отидете в Данни и щракнете върху Анализ на данните команда.

- От Анализ на данните изберете Регресия опция.
- След това щракнете върху OK .
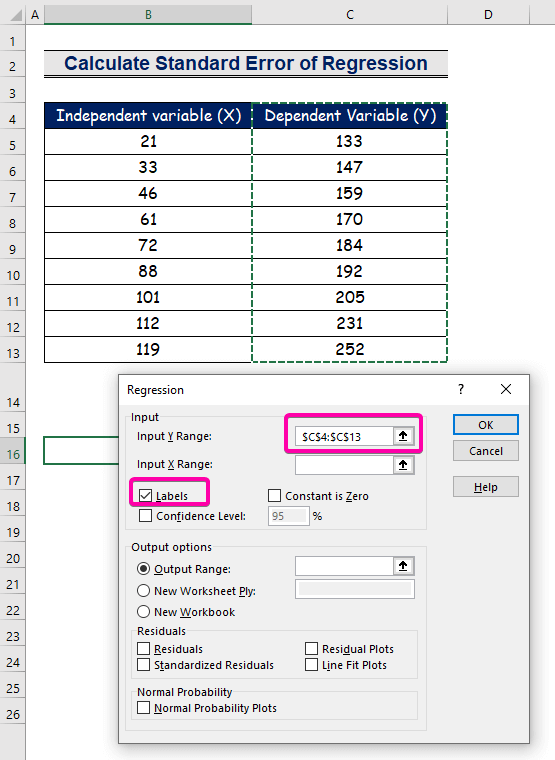
Стъпка 2: Вмъкване на входния и изходния диапазон в полето за регресия
- За Диапазон на входа Y , изберете обхвата C4:C13 със заглавието.
- Кликнете върху Етикети квадратчето за отметка.
- Изберете обхвата B4:B13 за Диапазон на входа X .
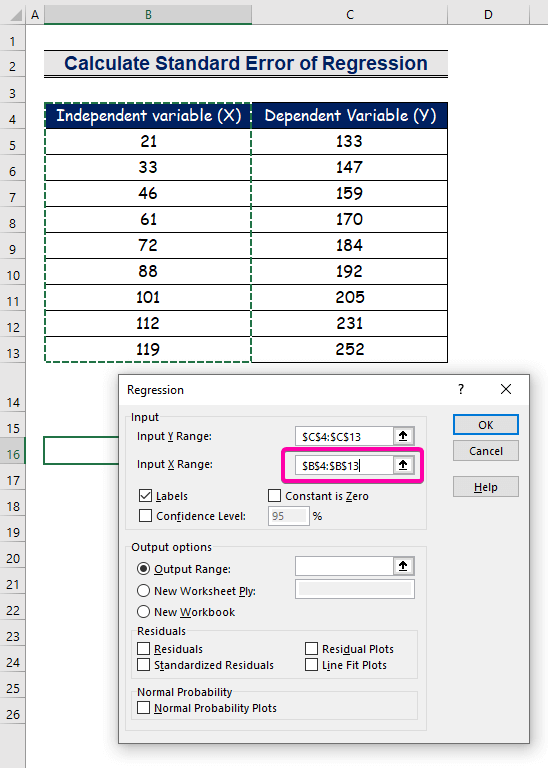
- За да получите резултата в предпочитаното място, изберете някоя клетка ( B16 ) за Изходен обхват .
- Накрая щракнете върху OK .

Прочетете още: Как да изчислим стандартната грешка на пропорцията в Excel (с лесни стъпки)
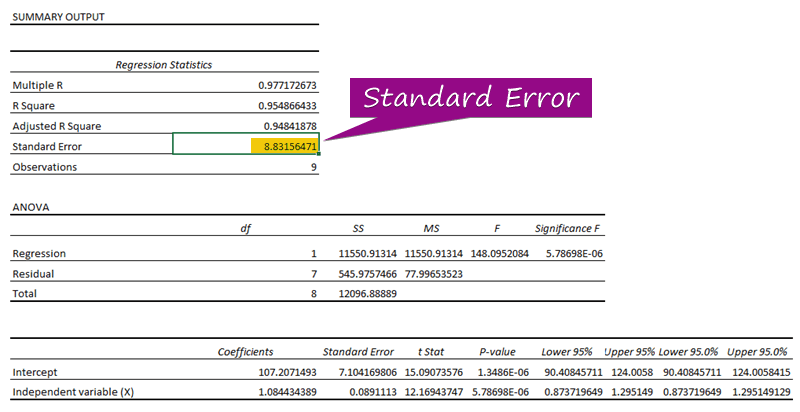
Стъпка 3: Открийте стандартната грешка
- От регресионния анализ можете да получите стойността на стандартната грешка ( 3156471 ).
Прочетете още: Как да намерите остатъчната стандартна грешка в Excel (2 лесни метода)
Стъпка 4: Построяване на графика на регресионния модел
- Първо, щракнете върху Вмъкване на таб.
- От Графики група, изберете Разпръскване диаграма.
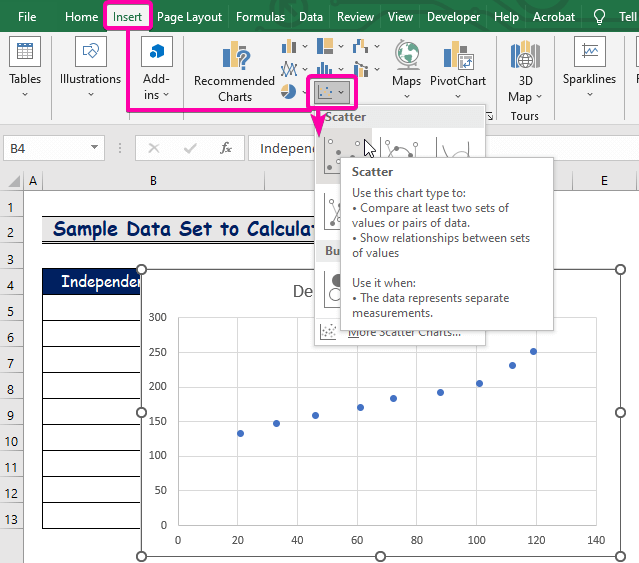
- Кликнете с десния бутон на мишката върху над една от точките.
- От опциите изберете Добавяне на линия на тенденцията опция.
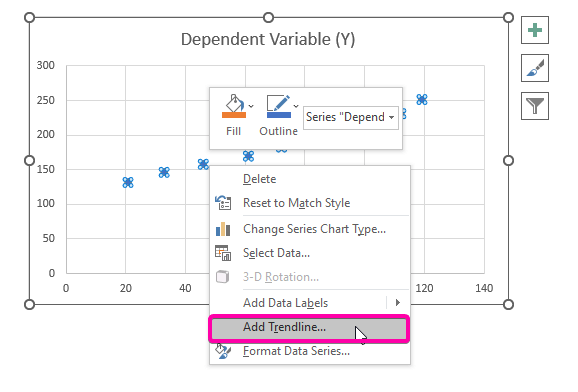
- Затова вашият регресионен анализ диаграмата ще бъде изобразена като на изображението по-долу.

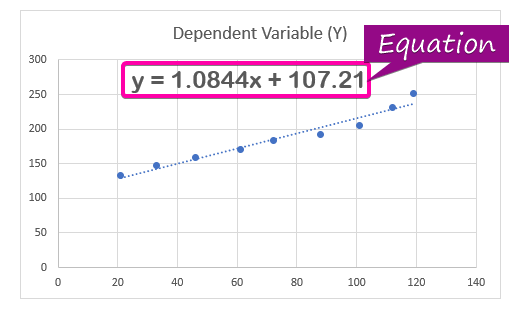
- За показване на регресионен анализ кликнете върху уравнението Показване на уравнението на диаграмата опция от Формат Трендлиния.

- В резултат на това уравнението ( y = 1,0844x + 107,21 ) на регресионния анализ ще се появи в графиката.
Бележки:
Можете да изчислите разликата между прогнозираните стойности и действителните стойности от уравнението на регресионния анализ.
Стъпки:
- Въведете формулата за представяне на уравнението на регресионния анализ.
=1.0844*B5 + 107.21 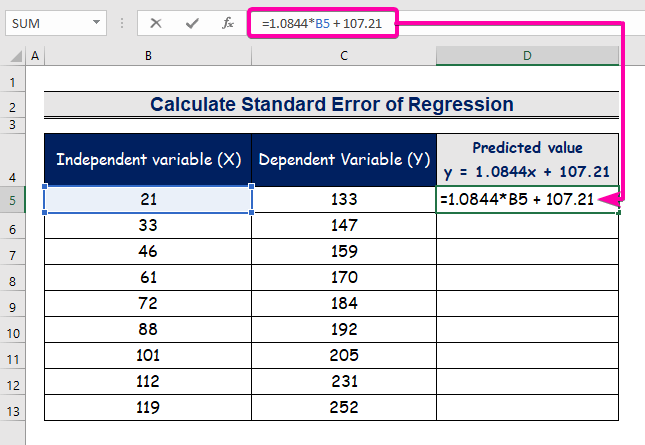
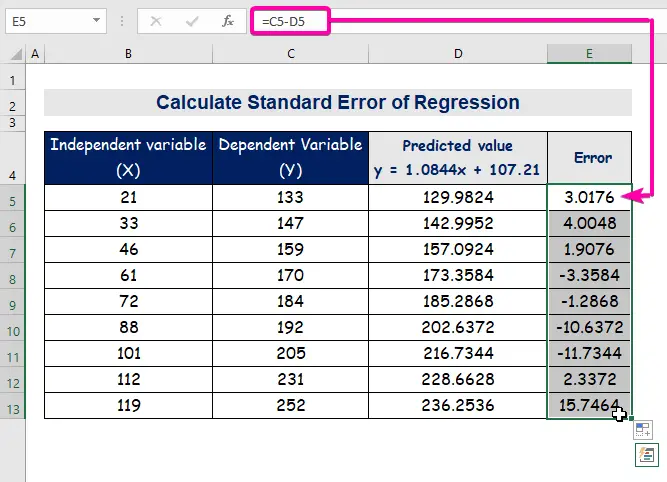
- Следователно ще получите първата прогнозна стойност ( 129.9824 ), която се различава от действителната стойност ( 133 ).

- Използвайте Инструмент за автоматично попълване за автоматично попълване на колоната D .

- За да изчислите грешката, въведете следната формула за изваждане.
=C5-D5 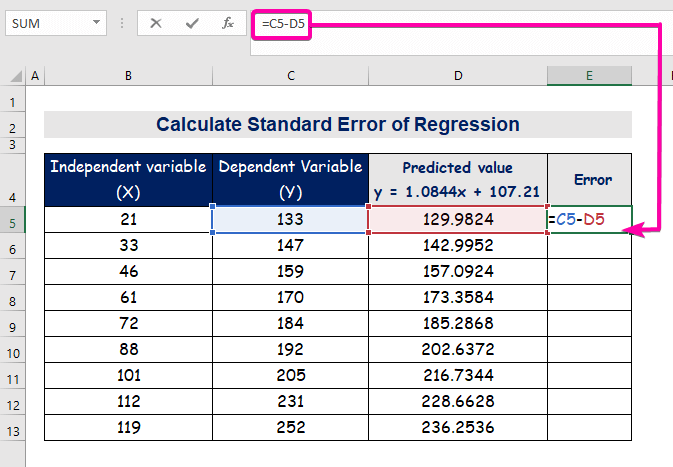
- И накрая, автоматично попълване на колоната E за намиране на стойностите на грешките.
Прочетете още: Как да изчислим стандартната грешка на наклона на регресията в Excel
Тълкуване на регресионния анализ в Excel
1. Стандартна грешка
От уравнението на регресионния анализ виждаме, че винаги има разлика или грешка между прогнозираните и действителните стойности. В резултат на това трябва да изчислим средното отклонение на разликите.
A стандартна грешка представлява средната грешка между предсказаната и действителната стойност. 8.3156471 като стандартна грешка в нашия примерен регресионен модел. Това показва, че има разлика между прогнозираните и действителните стойности, която може да е по-голяма от стандартна грешка ( 15.7464 ) или по-малко от стандартна грешка ( 4.0048 ). средна грешка ще бъде 8.3156471 , което е стандартна грешка .
В резултат на това целта на модела е да се намали стандартната грешка. по-нисък стандартната грешка, толкова повече точен модела.
2. Коефициенти
Коефициентът на регресия оценява отговорите на неизвестни стойности. В уравнението на регресия ( y = 1,0844x + 107,21 ), 1.0844 е коефициент , x е предсказващата независима променлива, 107.21 е константата, а y е стойността на отговора за x .
- A положителен коефициент предвижда, че колкото по-висок е коефициентът, толкова по-висока е променливата на отговора. пропорционален връзка.
- A отрицателен коефициент предвижда, че колкото по-висок е коефициентът, толкова по-ниски са стойностите на отговора. Той показва диспропорционален връзка.
3. P-стойности
В регресионния анализ, p-стойности и коефициентите си сътрудничат, за да ви информират дали корелациите във вашия модел са статистически значими и какви са тези връзки. нулева хипотеза че независимата променлива няма връзка със зависимата променлива, се проверява с помощта на p-стойност Няма връзка между промените в независимата променлива и промените в зависимата променлива, ако няма корелация.
- Данните от извадката ви дават достатъчно основание да фалшифицирате нулевата хипотеза за цялата популация, ако p-стойност за дадена променлива е по-малко от Вашия праг на значимост. Вашите доказателства подкрепят идеята за ненулева корелация На популационно ниво промените в независимата променлива са свързани с промени в зависимата променлива.
- A p-стойност по-голям от нивото на значимост, от двете страни, предполага, че вашата извадка има недостатъчно доказателство да се установи, че ненулева корелация съществува.
Защото техните p-стойности ( 5.787E-06 , 1.3E-06 ) са по-малко от значима стойност ( 5.787E-06 ), на Независима променлива (X) и Прихващане са статистически значими , както се вижда от примера с резултатите от регресията.
4. Стойности на R-Squared
За модели на линейна регресия, R-квадрат е измерване на пълнотата Това съотношение показва процент на отклонението в зависимата променлива, която независимите фактори обясняват, когато са взети заедно. 0-100 процентна скала, R-квадрат определя количествено сила на връзката между вашия модел и зависимата променлива.
Сайтът R2 е мярка за това колко добре регресионният модел съответства на вашите данни. по-високо ниво на номер . по-добър осъществим модел.
Заключение
Надявам се, че тази статия ви е дала урок за това как да изчислите стандартната грешка на регресията в Excel . Всички тези процедури трябва да бъдат научени и приложени към вашата съвкупност от данни. Разгледайте работната тетрадка за упражнения и изпробвайте тези умения. Мотивирани сме да продължаваме да правим подобни уроци благодарение на вашата ценна подкрепа.
Моля, свържете се с нас, ако имате някакви въпроси. Също така, не се колебайте да оставите коментари в раздела по-долу.
Ние, Exceldemy Екипът винаги реагира на вашите запитвания.
Останете с нас и продължавайте да се учите.
