
Indholdsfortegnelse
Vi bruger regressionsanalyse når vi har data fra to variabler fra to forskellige kilder og ønsker at skabe en sammenhæng mellem dem. Regressionsanalyse giver os en lineær model, som gør det muligt at forudsige mulige resultater. Der vil af indlysende årsager være nogle forskelle mellem de forudsagte og de faktiske værdier. Som følge heraf skal vi beregne standardfejlen ved hjælp af regressionsmodellen, som er den gennemsnitlige fejl mellem forudsagte og faktiske værdier. I denne vejledning vil vi vise dig, hvordan du beregner standardfejlen for regressionsanalyser i Excel .
Download arbejdsbog til øvelser
Download denne arbejdsbog til træning, så du kan øve dig, mens du læser denne artikel.
Regressionsstandardfejl.xlsx4 enkle trin til at beregne standardfejl i regression i Excel
Antag, at du har et datasæt med en uafhængige variabel ( X ) og en afhængige variabel ( Y ) Som du kan se, har de ikke nogen væsentlig sammenhæng. Men vi ønsker at opbygge en. Derfor vil vi bruge Regressionsanalyse for at skabe en lineær sammenhæng mellem de to. Vi beregner standardfejlen mellem de to variabler ved hjælp af regressionsanalysen. Vi gennemgår nogle af regressionsmodellens parametre i anden halvdel af artiklen for at hjælpe dig med at fortolke den.

Trin 1: Anvend kommandoen Dataanalyse til at oprette en regressionsmodel
- Først skal du gå til Data og klik på fanen Analyse af data kommando.

- Fra den Analyse af data skal du vælge den Regression mulighed.
- Klik derefter på OK .
Trin 2: Indsæt input- og outputområde i regressionsboksen
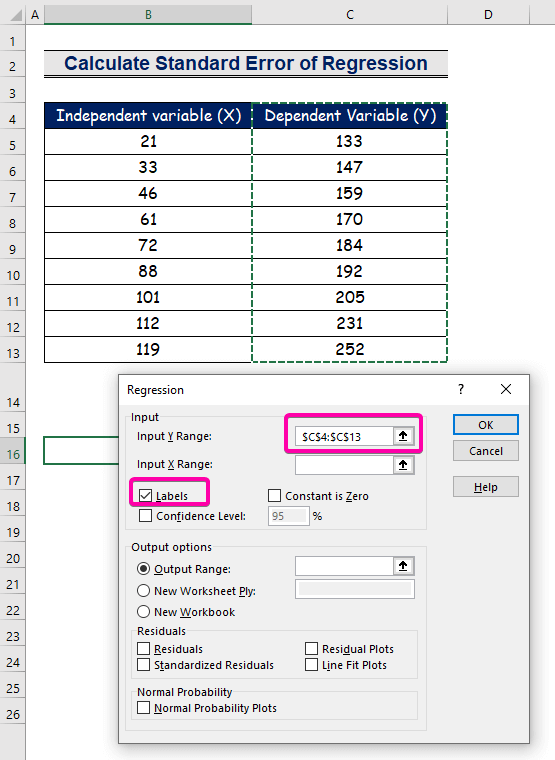
- For den Input Y-område , vælg området C4:C13 med overskriften.
- Klik på den Etiketter afkrydsningsfeltet.
- Vælg området B4:B13 for den Indgang X Område .
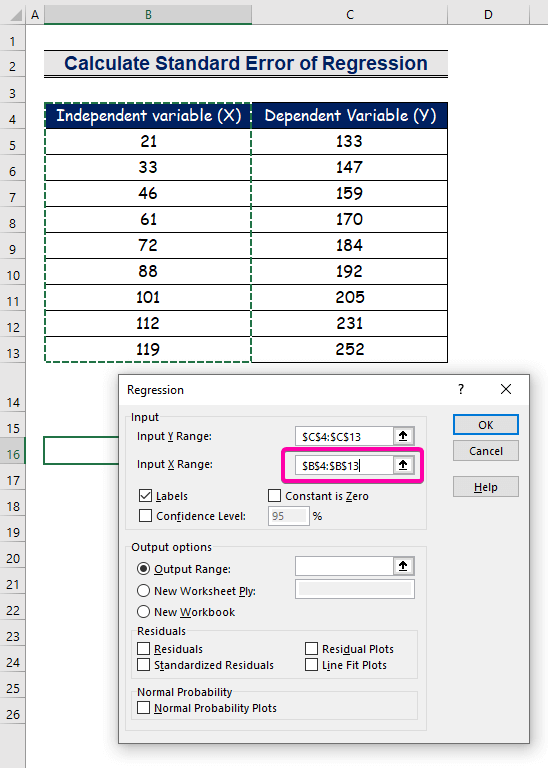
- Hvis du vil have resultatet på den foretrukne placering, skal du vælge en vilkårlig celle ( B16 ) for den Udgangsområde .
- Til sidst skal du klikke på OK .

Læs mere: Sådan beregnes standardfejl af andel i Excel (med nemme trin)
Trin 3: Find ud af standardfejl
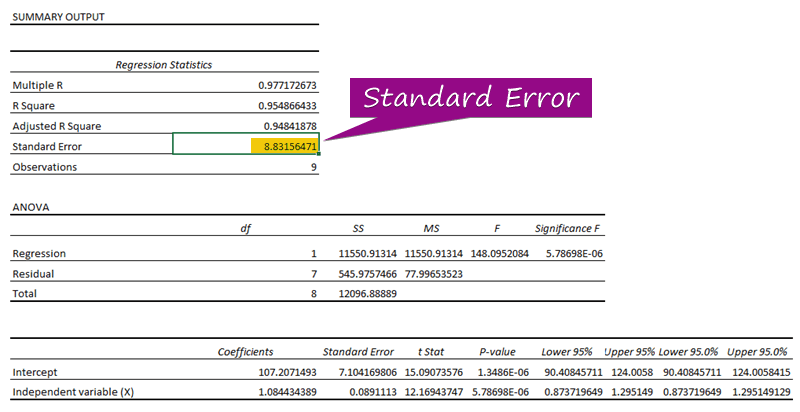
- Fra regressionsanalysen kan du få værdien af standardfejlen ( 3156471 ).
Læs mere: Sådan finder du residuale standardfejl i Excel (2 nemme metoder)
Trin 4: Plot regressionsmodeldiagram
- Først skal du klikke på Indsæt fanebladet.
- Fra den Diagrammer gruppe, skal du vælge den Spredning diagram.
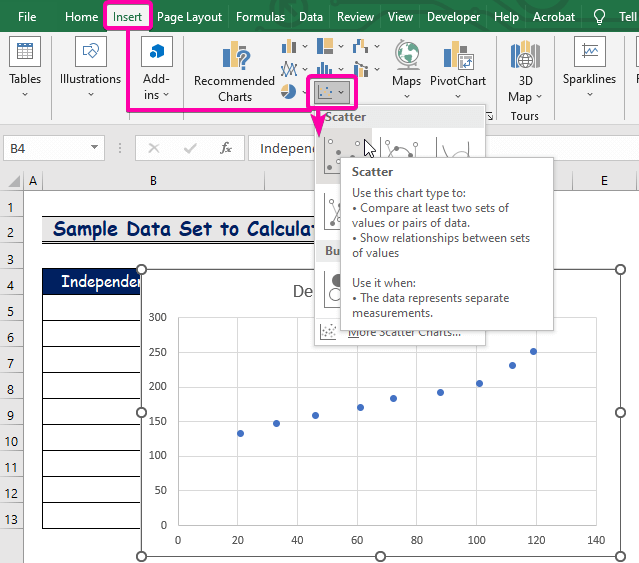
- Højreklik på over et af punkterne.
- Vælg den ønskede indstilling blandt indstillingerne Tilføj trendlinje mulighed.
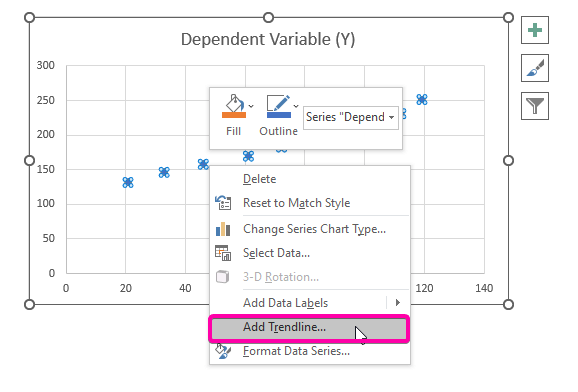
- Derfor skal din regressionsanalyse diagrammet vil blive vist som i nedenstående billede.

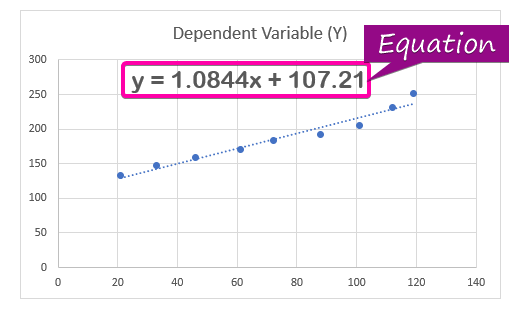
- Sådan vises regressionsanalyse ligning, skal du klikke på Visning af ligning på diagram fra Format Trendline.

- Som følge heraf er ligningen ( y = 1,0844x + 107,21 ) af regressionsanalysen vil fremgå af diagrammet.
Bemærkninger:
Du kan beregne forskellen mellem de forudsagte værdier og de faktiske værdier ud fra regressionsanalysens ligning.
Trin:
- Indtast formlen til at repræsentere regressionsanalysens ligning.
=1.0844*B5 + 107.21 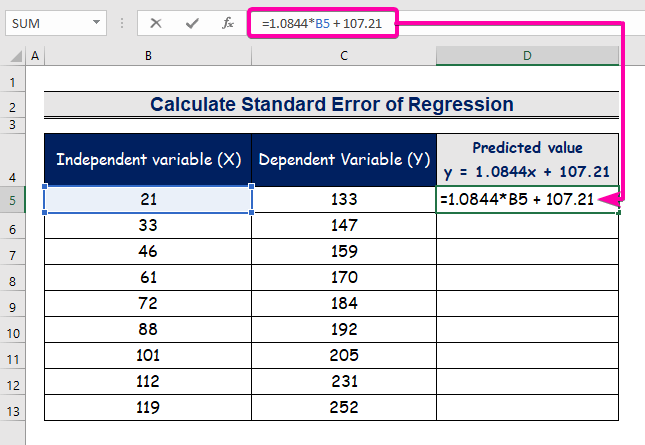
- Derfor vil du få den første forudsagte værdi ( 129.9824 ), som afviger fra den faktiske værdi ( 133 ).

- Brug den AutoFill værktøj til automatisk udfyldning af kolonne D .

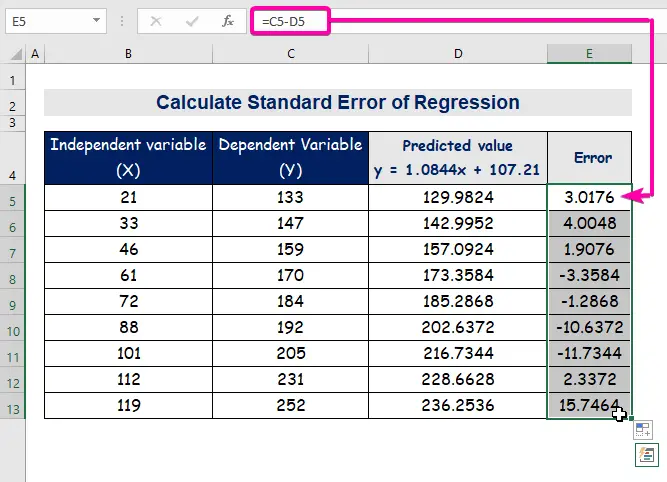
- For at beregne fejlen skal du indtaste følgende formel for at trække den fra.
=C5-D5 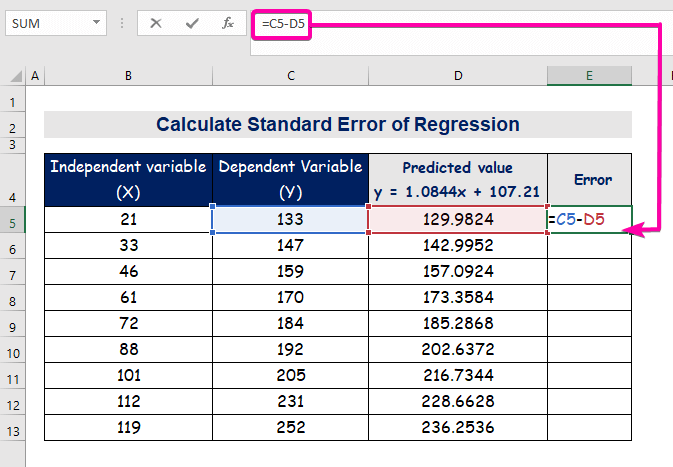
- Endelig kan kolonnen automatisk udfyldes E for at finde fejlværdierne.
Læs mere: Sådan beregnes Standard Error of Regression Slope i Excel
Fortolkning af regressionsanalyse i Excel
1. Standardfejl
Vi kan se af regressionsanalysens ligning, at der altid er en forskel eller fejl mellem de forudsagte og de faktiske værdier, og derfor skal vi beregne den gennemsnitlige afvigelse af forskellene.
A standardfejl repræsenterer den gennemsnitlige fejl mellem den forudsagte værdi og den faktiske værdi. Vi fandt 8.3156471 som den standardfejl Det indikerer, at der er en forskel mellem de forudsagte og de faktiske værdier, som kan være større end den standardfejl ( 15.7464 ) eller mindre end den standardfejl ( 4.0048 ). Men vores gennemsnitlig fejl vil være 8.3156471 , som er den standardfejl .
Som følge heraf er modellens mål at reducere standardfejlen. lavere standardfejlen, jo mere nøjagtig modellen.
2. Koefficienter
Regressionskoefficienten evaluerer svarene på ukendte værdier. I regressionsligningen ( y = 1,0844x + 107,21 ), 1.0844 er den koefficient , x er den uafhængige forudsigelsesvariabel, 107.21 er konstanten, og y er svarværdien for den x .
- A positiv koefficient forudsiger, at jo højere koefficienten er, jo højere er responsvariablen. Det indikerer en proportional forhold.
- A negativ koefficient forudsiger, at jo højere koefficienten er, jo lavere er svarværdierne. Det indikerer en uforholdsmæssigt stor forhold.
3. P-værdier
I regressionsanalyse, p-værdier og koefficienter samarbejder for at fortælle dig, om sammenhænge i din model er statistisk relevante, og hvordan disse sammenhænge er. nulhypotese at den uafhængige variabel ikke har nogen sammenhæng med den afhængige variabel testes ved hjælp af den p-værdi Der er ingen sammenhæng mellem ændringer i den uafhængige variabel og variationer i den afhængige variabel, hvis der ikke er nogen korrelation.
- Dine stikprøvedata giver tilstrækkelig støtte til at forfalske nulhypotesen for hele populationen, hvis den p-værdi for en variabel er mindre end din signifikanstærskel. Dit bevismateriale understøtter forestillingen om en korrelation ikke-nul På befolkningsniveau er ændringer i den uafhængige variabel forbundet med ændringer i den afhængige variabel.
- A p-værdi større end signifikansniveauet, på begge sider, tyder på, at din stikprøve har utilstrækkeligt bevis til at fastslå, at en korrelation ikke-nul eksisterer.
Fordi deres p-værdier ( 5.787E-06 , 1.3E-06 ) er mindre end den betydelig værdi ( 5.787E-06 ), den Uafhængig variabel (X) og Aflytning er statistisk signifikant , som det ses i regressionsoutputeksemplet.
4. R-kvadratværdier
For lineære regressionsmodeller, R-kvadrat er en måling af fuldstændighed Dette forhold viser den procentdel af variansen i den afhængige variabel, som de uafhængige faktorer tilsammen udgør. På en praktisk 0-100 procentskala, R-kvadrat kvantificerer den styrke af sammenhængen mellem din model og den afhængige variabel.
R2 værdien er et mål for, hvor godt regressionsmodellen passer til dine data. højere nummer , den bedre gennemførlig modellen.
Konklusion
Jeg håber, at denne artikel har givet dig en vejledning i, hvordan du beregner regressionens standardfejl i Excel Alle disse procedurer skal læres og anvendes på dit datasæt. Tag et kig på øvelsesarbejdsbogen og afprøv disse færdigheder. Vi er motiveret til at fortsætte med at lave vejledninger som denne på grund af din værdifulde støtte.
Du er velkommen til at kontakte os, hvis du har spørgsmål, og du er også velkommen til at skrive kommentarer i afsnittet nedenfor.
Vi, den Exceldemy Team, er altid lydhøre over for dine forespørgsler.
Bliv hos os og bliv ved med at lære.
