
Ynhâldsopjefte
Wy brûke regression-analyze as wy gegevens hawwe fan twa fariabelen út twa ferskillende boarnen en in relaasje dêrtusken bouwe wolle. Regression-analyze jout ús in lineêr model dat ús mooglik makket om mooglike útkomsten te foarsizzen. D'r sille om foar de hân lizzende redenen wat ferskillen wêze tusken de foarseine en werklike wearden. As gefolch, wy berekkenje de standert flater mei help fan it regression model, dat is de gemiddelde flater tusken foarsein en werklike wearden. Yn dizze tutorial sille wy jo sjen litte hoe't jo de standertflater fan regression-analyse berekkenje kinne yn Excel .
Oefenwurkboek downloade
Download dit praktykwurkboek om te oefenjen wylst jo binne it lêzen fan dit artikel.
Regression Standert Error.xlsx
4 ienfâldige stappen foar it berekkenjen fan standertflater fan regression yn Excel
Stel dat jo hawwe in gegevensset mei in ûnôfhinklike fariabele ( X ) en in ôfhinklike fariabele ( Y ) . Sa't jo sjen kinne, se hawwe gjin wichtige relaasje. Mar wy wolle ien bouwe. As resultaat sille wy Regression Analysis brûke om in lineêre relaasje tusken de twa te meitsjen. Wy sille de standertflater tusken de twa fariabelen berekkenje mei de regression-analyse. Wy geane oer guon fan 'e parameters fan it regressionmodel yn' e twadde helte fan it artikel om jo te helpen it ynterpretearje.

Stap 1: Tapasse Data Analysis CommandMeitsje in regressionmodel
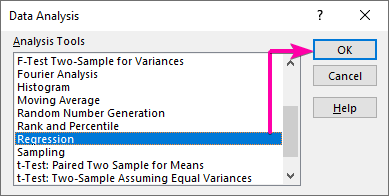
- Gean earst nei de Data ljepper en klikje op de Data-analyze kommando.

- Selektearje út de Gegevensanalyse listfak it Regression opsje.
- Dan, klikje op OK .
Stap 2: Ynfier- en útfierberik ynfoegje yn regressionfak
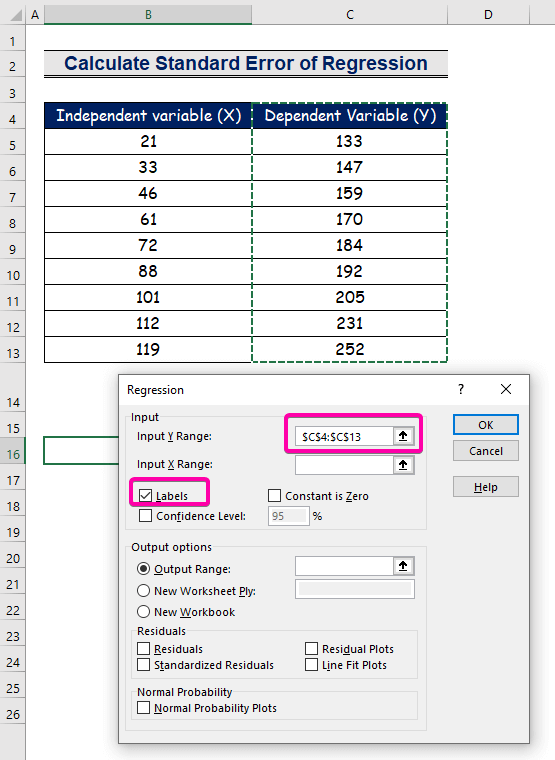
- Foar it Y-ynfierberik , selektearje it berik C4:C13 mei de koptekst.
- Klik op it karfakje Labels .
- Selektearje it berik B4:B13 foar it Ynput X-berik .
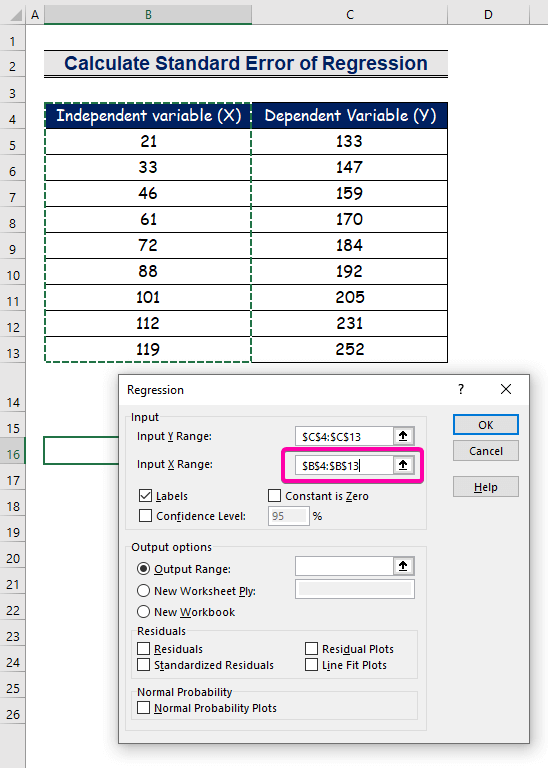
- Om it resultaat op 'e foarkarslokaasje te krijen, selektearje elke sel ( B16 ) foar it útfierberik .
- Klik as lêste op OK .

Lês mear: Hoe kinne jo standertflater fan proporsje berekkenje yn Excel (mei maklike stappen)
Stap 3: Standertflater fine
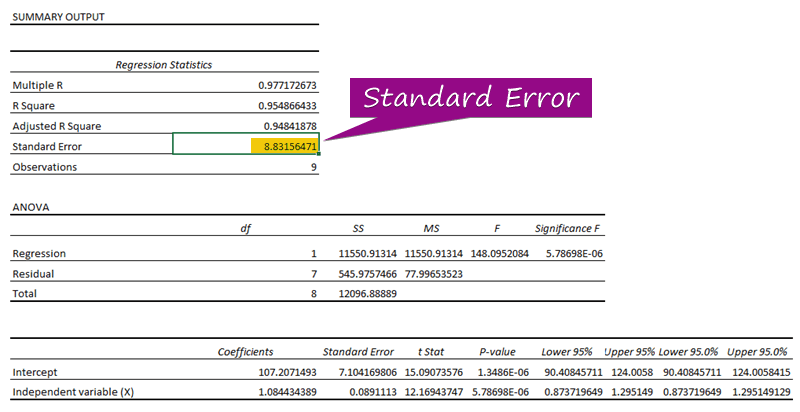
- Fan de regression analyze, kinne jo krije de wearde fan de standert flater ( 3156471 ).
Lês mear: Hoe om residuele standertflater te finen yn Excel (2 maklike metoaden)
Stap 4: Plot Regression Model Chart
- Klikje earst op de Ynfoegje ljepper.
- Fan de Charts groep, selektearje it Scatter diagram.
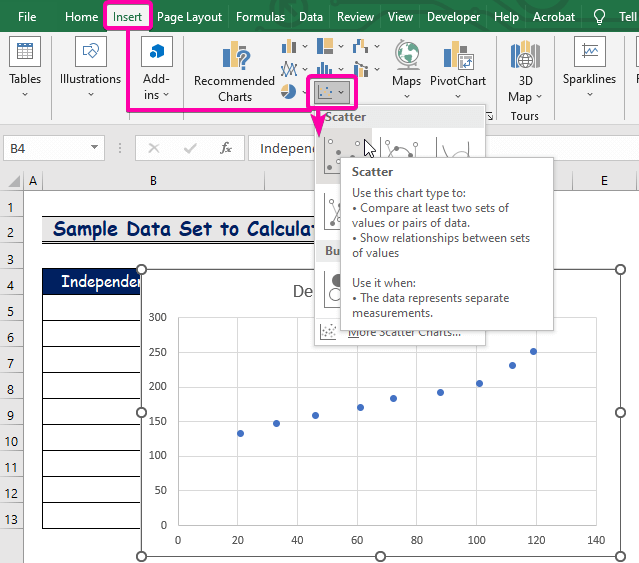
- Rjochts-klikke oer ien fan depunten.
- Selektearje út de opsjes de opsje Trendline taheakje .
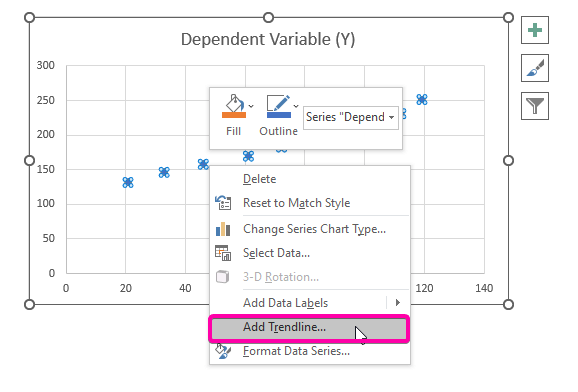
- Dêrom, jo regression-analyze -diagram sil wurde útset as de ôfbylding hjirûnder werjûn.

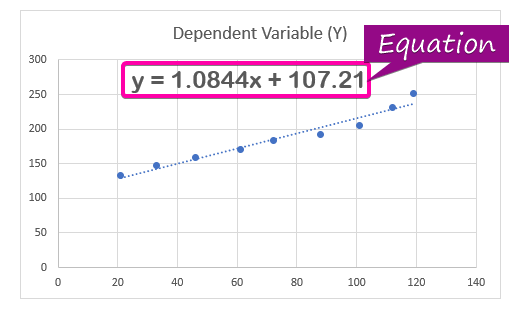
- Om de
regression analyze fergeliking, klikje op de Display fergeliking op Chart opsje út de Format Trendline.

- As resultaat is de fergeliking ( y = 1.0844x + 107.21 ) fan 'e regressionanalyse sil ferskine yn it diagram.
Notysjes:
Jo kinne it ferskil berekkenje tusken de foarseine wearden en de werklike wearden wearden út de fergeliking fan regressy-analyze.
Stappen:
- Typ de formule om de regression-analyzefergeliking foar te stellen.
=1.0844*B5 + 107.21 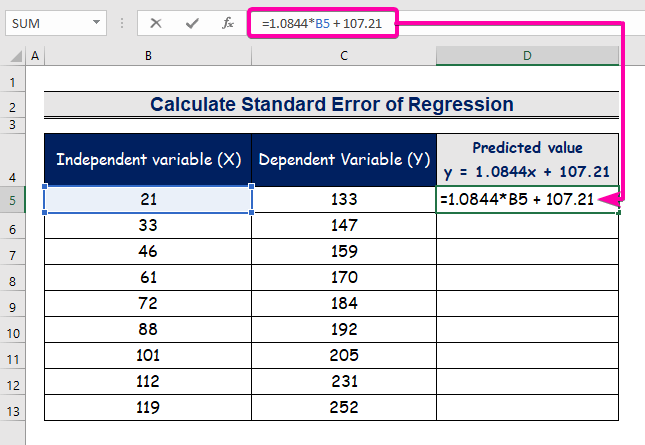
- Dêrom krije jo de earste foarseine wearde ( 129.9824 ), dat ferskilt fan de werklike wearde ( 133 ).

- Brûk de AutoFill Tool om de kolom automatysk yn te foljen D .

- Om de flater te berekkenjen, typ de folgjende formule om subtract.
=C5-D5 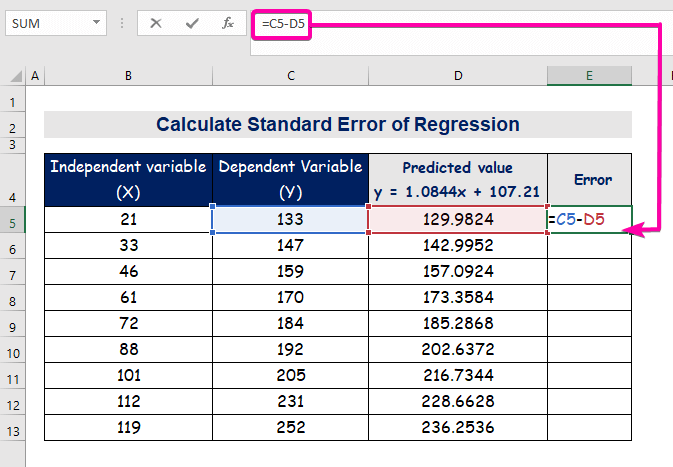
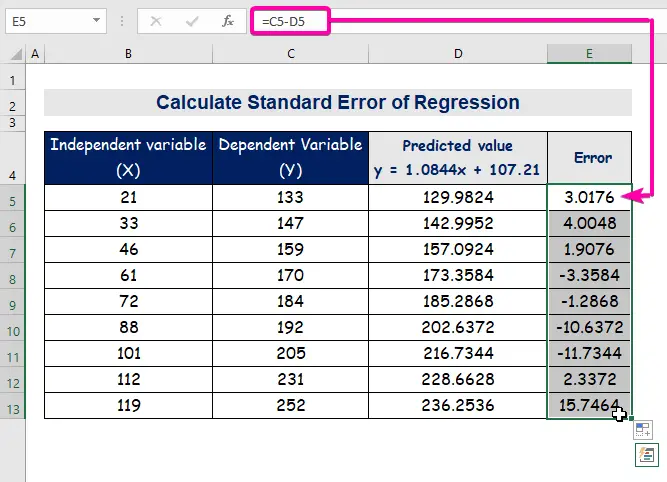
- Uteinlik, automatysk ynfolje kolom E om de flaterwearden te finen.
Lês mear: Hoe kinne jo standertflater fan regressionhelling yn berekkenje Excel
De ynterpretaasje fan regression-analyze yn Excel
1. Standertflater
Wy kinne sjen út 'e regression-analyze-fergeliking dat der altyd in ferskil of flater is tusken de foarseine en werklike wearden. Dêrtroch moatte wy de gemiddelde ôfwiking fan de ferskillen berekkenje.
In standertflater stiet foar de gemiddelde flater tusken de foarseine wearde en de werklike wearde. Wy ûntdutsen 8.3156471 as de standert flater yn ús foarbyld regressionmodel. It jout oan dat der in ferskil is tusken de foarseine en werklike wearden, dy't grutter wêze kinne as de standertflater ( 15.7464 ) of minder as de standert flater ( 4.0048 ). Us gemiddelde flater sil lykwols 8.3156471 wêze, dat is de standertflater .
As resultaat is it doel fan it model om de standertflater te ferminderjen. Hoe leger de standert flater, hoe mear krekter it model. antwurden fan ûnbekende wearden. Yn de regressionfergeliking ( y = 1.0844x + 107.21 ), is 1.0844 de koëffisjint , x is de foarsizzer ûnôfhinklike fariabele, 107.21 is de konstante, en y is de antwurdwearde foar de x .
- A positive koeffizient foarsizze dat hoe heger de koeffizient, hoe heger de reaksjefariabele. It jout in proporsjonele relaasje oan.
- In negative koeffisient foarseit dat hoe heger de koeffizient, hoe leger de antwurdwearden. It jout in disproporsjonele relaasje oan.
3. P-Wearden
Yn regression-analyze, p- wearden en koeffizienten wurkje gear om jo te ynformearjen oft korrelaasjes yn jo model statistysk relevant binne en hoe't dy relaasjes binne. De nulhypoteze dat de ûnôfhinklike fariabele gjin keppeling hat mei de ôfhinklike fariabele wurdt hifke mei de p-wearde foar elke ûnôfhinklike fariabele. D'r is gjin keppeling tusken feroarings yn 'e ûnôfhinklike fariabele en fariaasjes yn' e ôfhinklike fariabele as der gjin korrelaasje is.
- Jo stekproefgegevens jouwe genôch stipe om de nulhypoteze foar de falsifisearje te litten. folsleine populaasje as de p-wearde foar in fariabele minder is as jo betsjuttingsdrompel. Jo bewiis stipet it idee fan in non-nul korrelaasje . Op populaasjenivo binne feroarings yn 'e ûnôfhinklike fariabele keppele oan feroaringen yn 'e ôfhinklike fariabele.
- A p-wearde grutter as it betsjuttingsnivo, oan beide kanten , suggerearret dat jo stekproef net genôch bewiis hat om fêst te stellen dat in korrelaasje net-nul bestiet.
Om't harren p-wearden ( 5.787E-06 , 1.3E-06 ) binne minder dan de signifikante wearde ( 5.787E-06 ), de Unôfhinklike fariabele (X) en Intercept binne statistysk signifikant , lykas sjoen yn it foarbyld fan regression-útfier.
4. R-Squared Values
Foar lineêre regressionmodellen is R-kwadraat in folsleinheidsmeting . Dizze ferhâlding lit it persintaazje fan fariânsje sjen yn 'e ôfhinklike fariabele wêrmei't de ûnôfhinklike faktoaren rekken hâlde as se tegearre nommen wurde. Op in handige 0–100 persintaazje skaal kwantifisearret R-kwadraat de sterkte fan de ferbining tusken jo model en de ôfhinklike fariabele.
De R2 wearde is in mjitte fan hoe goed it regressionmodel past by jo gegevens. Hoe heger it nûmer , hoe better it model is.
Konklúzje
Ik hoopje dat dit artikel jo in tutorial oer hoe't jo de standertflater fan regression berekkenje kinne yn Excel . Al dizze prosedueres moatte wurde leard en tapast op jo dataset. Besjoch it oefenwurkboek en test dizze feardichheden. Wy binne motivearre om troch jo weardefolle stipe troch te gean mei it meitsjen fan tutorials.
Nim asjebleaft kontakt mei ús op as jo fragen hawwe. Fiel jo ek frij om opmerkingen te litten yn 'e seksje hjirûnder.
Wy, it Exceldemy Team, binne altyd reagearje op jo fragen.
Bliuw by ús en bliuw leare.
