
Obsah
Používáme regresní analýza když máme data dvou proměnných ze dvou různých zdrojů a chceme mezi nimi vytvořit vztah. Regresní analýza nám poskytuje lineární model, který nám umožňuje předpovídat možné výsledky. Mezi předpovídanými a skutečnými hodnotami budou ze zřejmých důvodů určité rozdíly. V důsledku toho budeme vypočítat standardní chybu pomocí regresního modelu, což je průměrná chyba mezi předpovídanými a skutečnými hodnotami. V tomto tutoriálu vám ukážeme, jak vypočítat standardní chybu regresní analýzy v programu. Excel .
Stáhnout cvičebnici
Stáhněte si tento cvičební sešit a procvičujte si při čtení tohoto článku.
Regresní standardní chyba.xlsx4 jednoduché kroky pro výpočet standardní chyby regrese v aplikaci Excel
Předpokládejme, že máte datovou sadu s nezávislá proměnná ( X ) a závislá proměnná ( Y ) . Jak vidíte, nemají žádný významný vztah. Ale my ho chceme vytvořit. V důsledku toho použijeme. Regresní analýza k vytvoření lineárního vztahu mezi oběma proměnnými. Pomocí regresní analýzy vypočítáme standardní chybu mezi oběma proměnnými. V druhé polovině článku probereme některé parametry regresního modelu, které vám pomohou při jeho interpretaci.

Krok 1: Použití příkazu pro analýzu dat k vytvoření regresního modelu
- Nejprve přejděte na Data a klikněte na kartu Analýza dat příkaz.

- Z Analýza dat v seznamu vyberte Regrese možnost.
- Poté klikněte na tlačítko OK .
Krok 2: Vložení vstupního a výstupního rozsahu do regresního pole
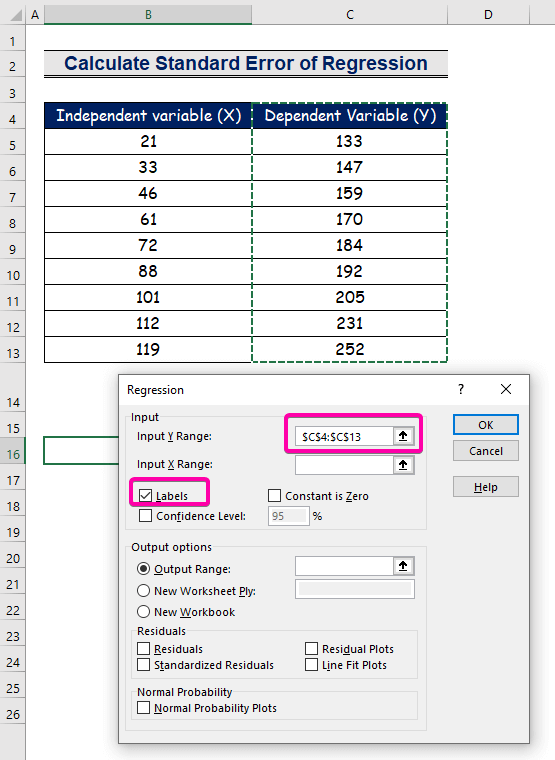
- Pro Vstupní rozsah Y , vyberte rozsah C4:C13 se záhlavím.
- Klikněte na Štítky zaškrtávacího políčka.
- Vyberte rozsah B4:B13 pro Rozsah vstupu X .
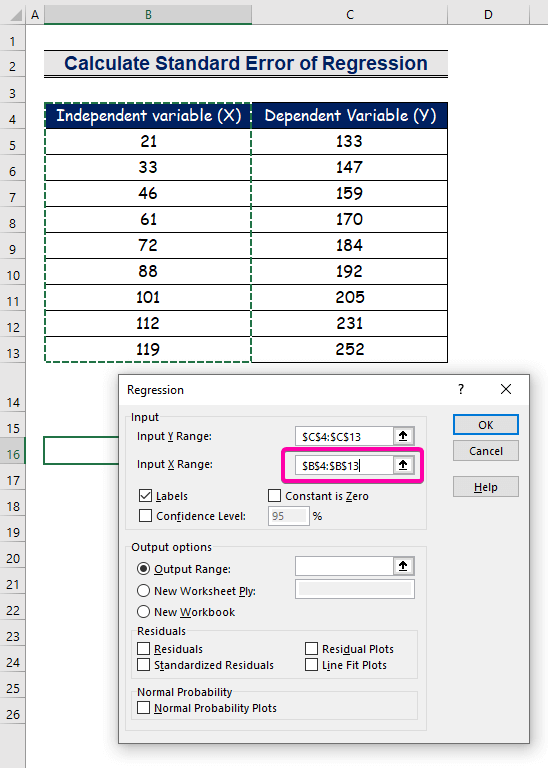
- Chcete-li získat výsledek v preferovaném umístění, vyberte libovolnou buňku ( B16 ) pro Výstupní rozsah .
- Nakonec klikněte na OK .

Přečtěte si více: Jak vypočítat standardní chybu poměru v aplikaci Excel (ve snadných krocích)
Krok 3: Zjištění standardní chyby
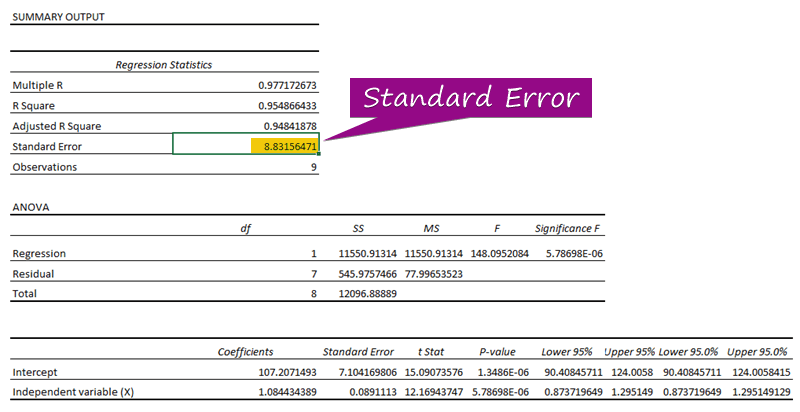
- Z regresní analýzy lze získat hodnotu standardní chyby ( 3156471 ).
Přečtěte si více: Jak zjistit zbytkovou standardní chybu v aplikaci Excel (2 snadné metody)
Krok 4: Sestavte graf regresního modelu
- Nejprve klikněte na Vložte tab.
- Z Grafy vyberte skupinu Rozptyl graf.
- Klikněte pravým tlačítkem myši na nad jedním z bodů.
- Z možností vyberte Přidat trendovou čáru možnost.
- Proto vaše regresní analýza graf se vykreslí jako na obrázku níže.

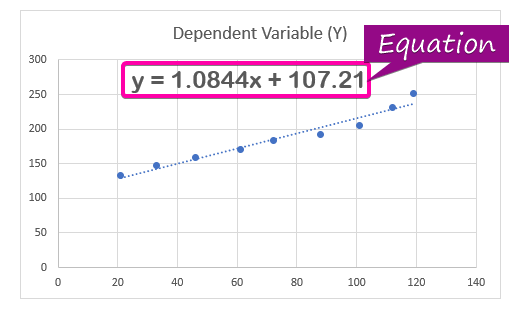
- Zobrazení regresní analýza rovnice, klikněte na Zobrazení rovnice na grafu možnost z Formát Trendline.

- Výsledkem je rovnice ( y = 1,0844x + 107,21 ) regresní analýzy se zobrazí v grafu.
Poznámky:
Z rovnice regresní analýzy můžete vypočítat rozdíl mezi předpokládanými a skutečnými hodnotami.
Kroky:
- Zadejte vzorec, který představuje rovnici regresní analýzy.
=1.0844*B5 + 107.21 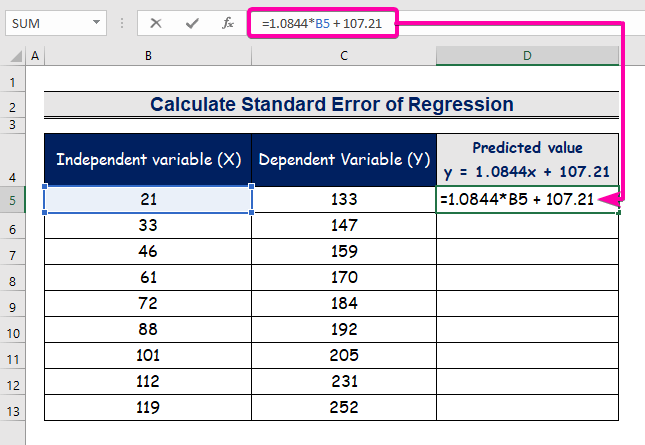
- Proto získáte první předpokládanou hodnotu ( 129.9824 ), která se liší od skutečné hodnoty ( 133 ).

- Použijte Nástroj pro automatické vyplňování pro automatické vyplnění sloupce D .

- Chcete-li chybu vypočítat, zadejte následující vzorec pro odečtení.
=C5-D5 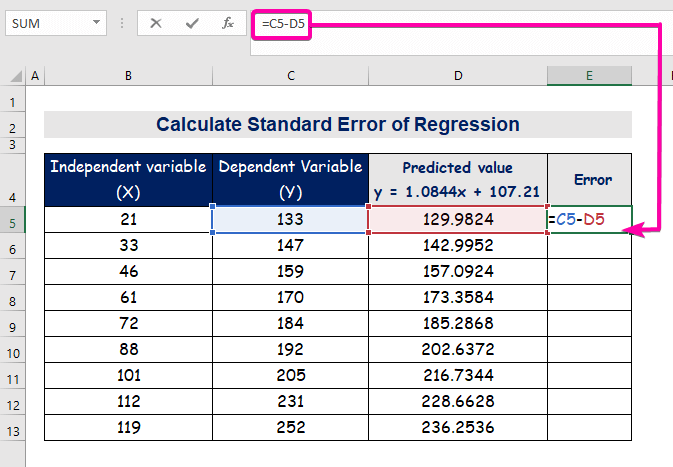
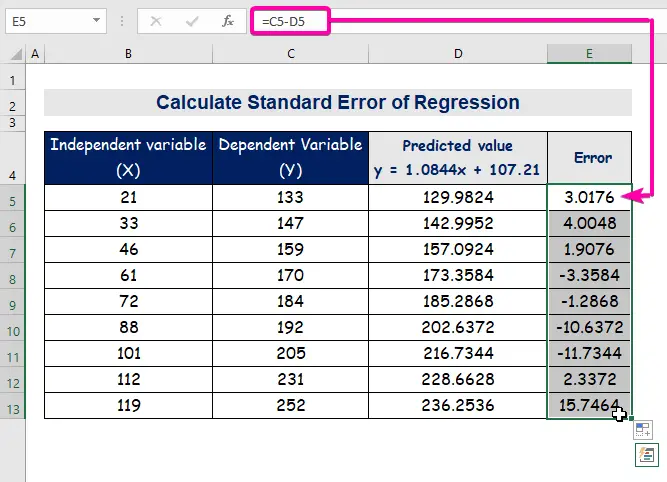
- Nakonec sloupec automatického vyplňování E k nalezení chybových hodnot.
Přečtěte si více: Jak vypočítat standardní chybu regresního sklonu v aplikaci Excel
Interpretace regresní analýzy v aplikaci Excel
1. Standardní chyba
Z rovnice regresní analýzy vidíme, že mezi předpovídanými a skutečnými hodnotami je vždy rozdíl nebo chyba. V důsledku toho musíme vypočítat průměrnou odchylku rozdílů.
A standardní chyba představuje průměrnou chybu mezi předpovídanou a skutečnou hodnotou. Zjistili jsme, že 8.3156471 jako standardní chyba v našem příkladě regresního modelu. To znamená, že existuje rozdíl mezi předpovídanými a skutečnými hodnotami, který může být větší než standardní chyba ( 15.7464 ) nebo méně než standardní chyba ( 4.0048 ). průměrná chyba bude 8.3156471 , což je standardní chyba .
V důsledku toho je cílem modelu snížit standardní chybu. nižší standardní chyba, tím více přesné model.
2. Koeficienty
Regresní koeficient vyhodnocuje odpovědi neznámých hodnot. V regresní rovnici ( y = 1,0844x + 107,21 ), 1.0844 je koeficient , x je prediktivní nezávislá proměnná, 107.21 je konstanta a y je hodnota odezvy pro x .
- A kladný koeficient předpovídá, že čím vyšší je koeficient, tím vyšší je proměnná, na kterou se reaguje. proporcionální vztah.
- A záporný koeficient předpovídá, že čím vyšší je koeficient, tím nižší jsou hodnoty odpovědí. To naznačuje, že disproporční vztah.
3. Hodnoty P
V regresní analýze, p-hodnoty a koeficienty spolupracují a informují vás o tom, zda jsou korelace ve vašem modelu statisticky relevantní a jaké jsou tyto vztahy. nulová hypotéza že nezávislá proměnná nemá žádnou souvislost se závislou proměnnou, se testuje pomocí metody p-hodnota Pro každou nezávislou proměnnou neexistuje souvislost mezi změnami nezávislé proměnné a změnami závislé proměnné, pokud neexistuje korelace.
- Vaše vzorové údaje poskytují dostatečnou podporu pro zfalšovat nulovou hypotézu pro celou populaci, pokud je p-hodnota pro proměnnou je méně než je váš práh významnosti. Vaše důkazy podporují představu, že se jedná o nenulová korelace Na úrovni populace jsou změny nezávislé proměnné spojeny se změnami závislé proměnné.
- A p-hodnota větší než je hladina významnosti, na obou stranách, naznačuje, že váš vzorek má nedostatečný důkaz prokázat, že nenulová korelace existuje.
Protože jejich p-hodnoty ( 5.787E-06 , 1.3E-06 ) jsou méně než významná hodnota ( 5.787E-06 ),. Nezávislá proměnná (X) a Intercept jsou statisticky významné , jak je vidět na příkladu regresního výstupu.
4. Hodnoty R-kvadrátu
Pro lineární regresní modely, R-kvadrát je měření úplnosti Tento poměr ukazuje procento odchylky v závislé proměnné, kterou dohromady tvoří nezávislé faktory. Na příručce 0-100 procentní stupnice, R-kvadrát kvantifikuje síla spojení mezi vaším modelem a závislou proměnnou.
Na stránkách R2 je měřítkem toho, jak dobře regresní model odpovídá vašim datům. vyšší na číslo ... lepší proveditelný model.
Závěr
Doufám, že vám tento článek poskytl návod, jak vypočítat standardní chybu regrese v programu Excel . Všechny tyto postupy byste se měli naučit a aplikovat je na svůj soubor dat. Podívejte se na cvičný sešit a vyzkoušejte si tyto dovednosti. K další tvorbě podobných výukových programů nás motivuje vaše cenná podpora.
V případě jakýchkoli dotazů nás prosím kontaktujte. V níže uvedené části můžete také zanechat komentáře.
My, Exceldemy Tým vždy reaguje na vaše dotazy.
Zůstaňte s námi a učte se dál.
