
Բովանդակություն
Մենք օգտագործում ենք ռեգեսիոն վերլուծություն , երբ ունենք տվյալներ երկու տարբեր աղբյուրներից երկու փոփոխականներից և ցանկանում ենք հարաբերություններ հաստատել դրանց միջև: Ռեգրեսիոն վերլուծությունը մեզ տալիս է գծային մոդել, որը թույլ է տալիս կանխատեսել հնարավոր արդյունքները: Ակնհայտ պատճառներով որոշակի տարբերություններ կլինեն կանխատեսված և իրական արժեքների միջև: Արդյունքում մենք հաշվում ենք ստանդարտ սխալը օգտագործելով ռեգրեսիոն մոդելը, որը միջին սխալն է կանխատեսված և իրական արժեքների միջև: Այս ձեռնարկում մենք ձեզ ցույց կտանք, թե ինչպես կարելի է հաշվարկել ռեգրեսիոն վերլուծության ստանդարտ սխալը Excel -ում:
Ներբեռնեք Practice Workbook
Ներբեռնեք այս պրակտիկայի աշխատանքային գրքույկը, որպեսզի մարզվեք մինչ դուք կարդալով այս հոդվածը:
Regression Standard Error.xlsx
4 պարզ քայլ Excel-ում ռեգրեսիայի ստանդարտ սխալը հաշվարկելու համար
Ենթադրենք, որ ունեք տվյալների հավաքածու անկախ փոփոխականով ( X ) և կախյալ փոփոխականով ( Y ) : Ինչպես տեսնում եք, նրանք էական հարաբերություններ չունեն։ Բայց մենք ուզում ենք կառուցել: Արդյունքում, մենք կօգտագործենք Ռեգրեսիոն վերլուծություն ՝ երկուսի միջև գծային հարաբերություն ստեղծելու համար: Մենք կհաշվարկենք ստանդարտ սխալը երկու փոփոխականների միջև՝ օգտագործելով ռեգրեսիոն վերլուծությունը: Մենք կանդրադառնանք ռեգրեսիայի մոդելի որոշ պարամետրերին հոդվածի երկրորդ կեսում, որպեսզի օգնենք ձեզ մեկնաբանել այն:

Քայլ 1. Կիրառել տվյալների վերլուծության հրամանըՍտեղծեք ռեգրեսիոն մոդել
- Սկզբում գնացեք Տվյալներ ներդիրը և սեղմեք Տվյալների վերլուծություն հրաման:

- Տվյալների վերլուծություն ցանկի վանդակից ընտրեք Regression տարբերակ:
- Այնուհետև սեղմեք OK :
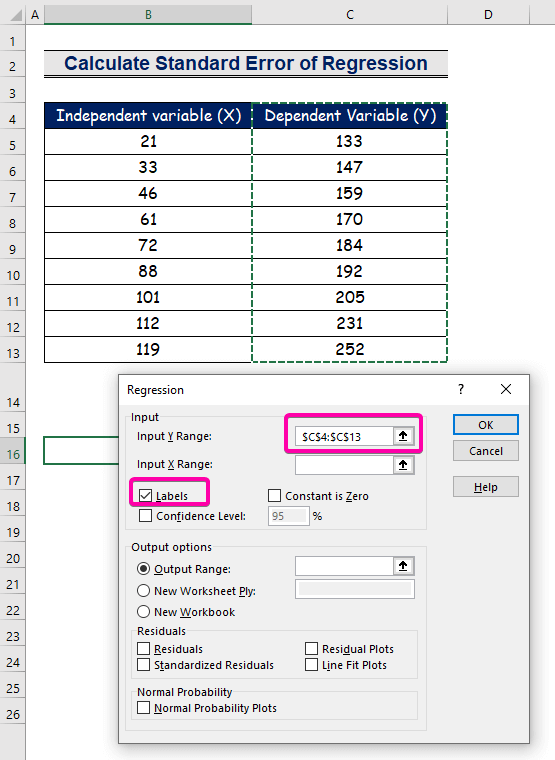
Քայլ 2. Տեղադրեք մուտքային և ելքային միջակայքը ռեգրեսիայի վանդակում
- Մուտքային Y միջակայքի ընտրեք միջակայքը C4:C13 վերնագրի հետ:
- Սեղմեք Պիտակներ վանդակի վրա:
- Ընտրեք միջակայքը B4:B13 Input X տիրույթի :
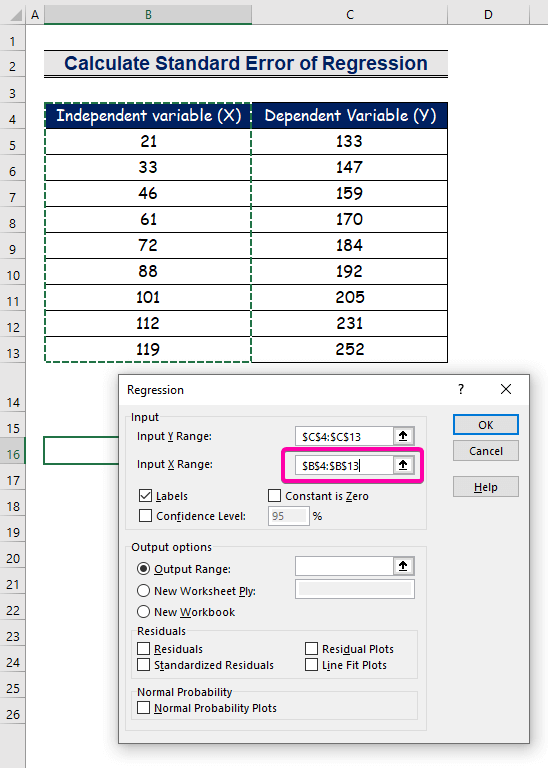
- Արդյունքը նախընտրելի վայրում ստանալու համար ընտրեք ցանկացած բջիջ ( B16 ) Ելքի տիրույթի համար։ .
- Վերջապես սեղմեք OK ։

Կարդալ ավելին. Ինչպես հաշվարկել համաչափության ստանդարտ սխալը Excel-ում (հեշտ քայլերով)
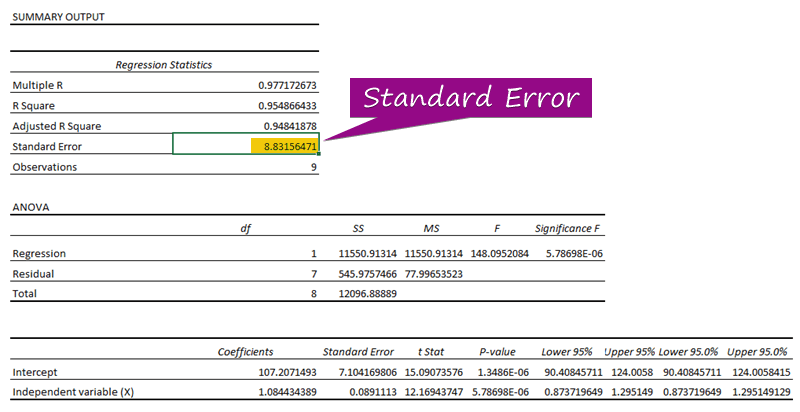
Քայլ 3. Պարզեք ստանդարտ սխալը
- ռեգրեսիոն վերլուծության արդյունքում կարող եք ստանալ արժեքը ստանդարտ սխալը ( 3156471 ).
Կարդալ ավելին. Ինչպես Excel-ում մնացորդային ստանդարտ սխալ գտնելու համար (2 հեշտ մեթոդ)
Քայլ 4. Հողամասի ռեգրեսիայի մոդելի գծապատկեր
- Նախ, սեղմեք Տեղադրեք ներդիր:
- Գծապատկերներ խմբից ընտրեք Scatter գծապատկերը:
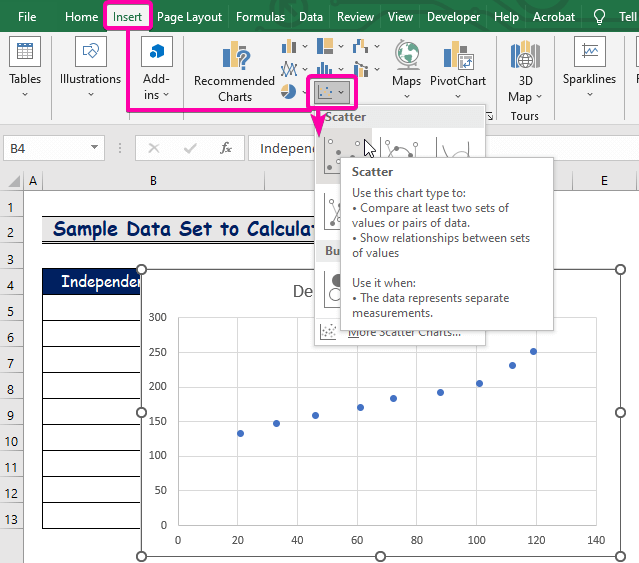
- Աջ սեղմեք մեկի վրամիավորներ:
- Ընտրանքներից ընտրեք Ավելացնել միտումների գիծ տարբերակը:
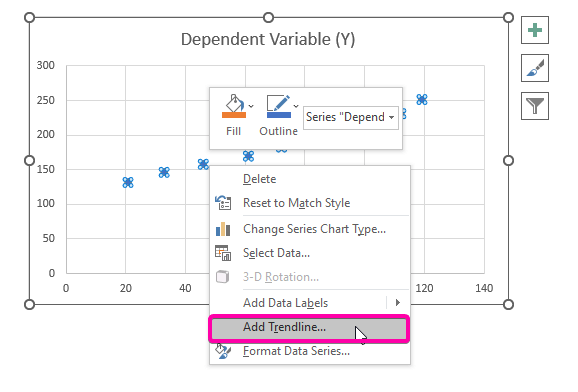
- Ուստի ձեր ռեգրեսիոն վերլուծություն գծապատկերը կներկայացվի ստորև ներկայացված պատկերի պես:

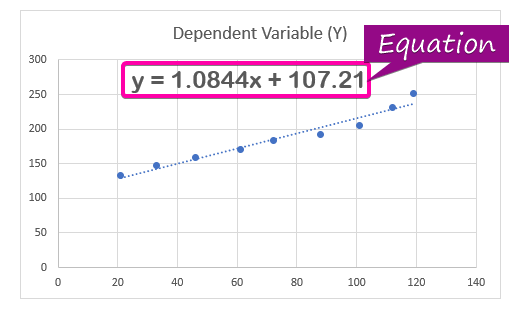
- Ցուցադրելու համար ռեգրեսիոն վերլուծություն հավասարումը, սեղմեք Ցուցադրել հավասարումը գծապատկերում տարբերակը Ձևաչափել միտումը:

- Արդյունքում, ռեգրեսիոն վերլուծության հավասարումը ( y = 1,0844x + 107,21 ). կհայտնվի գծապատկերում:
Նշումներ.
Դուք կարող եք հաշվարկել կանխատեսված արժեքների և իրական արժեքների տարբերությունը արժեքներ ռեգրեսիոն վերլուծության հավասարումից:
Քայլեր.
- Մուտքագրեք ռեգրեսիոն վերլուծության հավասարումը ներկայացնելու բանաձեւը:
=1.0844*B5 + 107.21 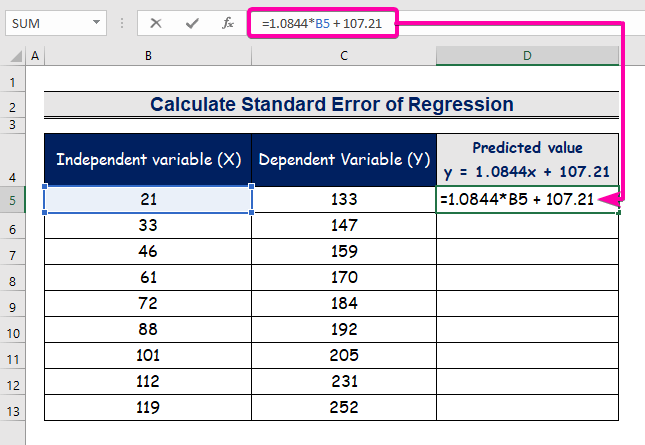
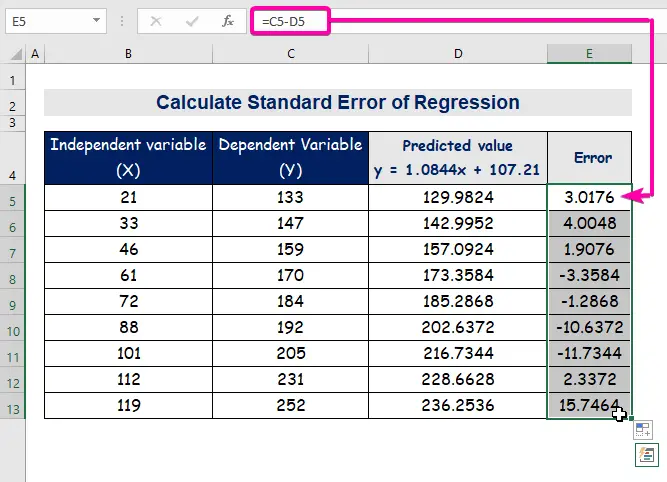
- Հետևաբար, դուք կստանաք առաջին կանխատեսված արժեքը ( 129.9824 ), որը տարբերվում է իրական արժեքից ( 133 ):

- Օգտագործեք Ավտոլրացման գործիք D սյունակի ավտոմատ լրացման համար:

- Սխալը հաշվարկելու համար մուտքագրեք հետևյալ բանաձևը. հանել:
=C5-D5 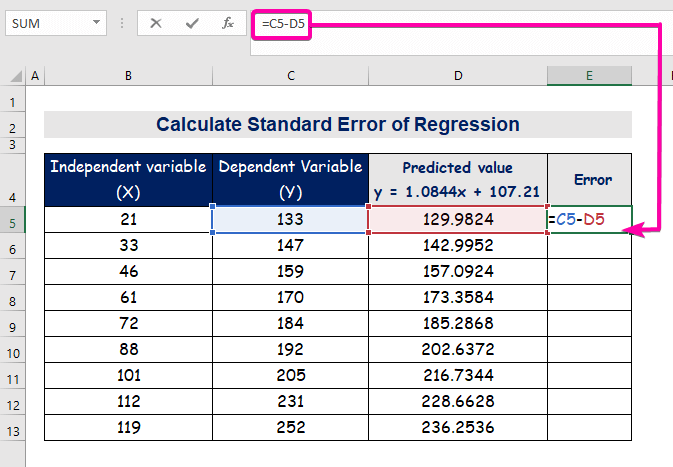
- Վերջապես, ավտոմատ լրացնել սյունակը E սխալի արժեքները գտնելու համար:
Կարդալ ավելին. Ինչպես հաշվարկել ռեգրեսիայի թեքության ստանդարտ սխալը Excel
Regression Analysis-ի մեկնաբանումը Excel-ում
1. Ստանդարտ սխալ
Մենք կարող ենք տեսնել ռեգրեսիոն վերլուծության հավասարումից, որ կանխատեսված և իրական արժեքների միջև միշտ կա տարբերություն կամ սխալ: Արդյունքում, մենք պետք է հաշվարկենք տարբերությունների միջին շեղումը:
A ստանդարտ սխալը ներկայացնում է միջին սխալը կանխատեսված արժեքի և իրական արժեքի միջև: Մենք հայտնաբերեցինք 8.3156471 որպես ստանդարտ սխալ մեր օրինակի ռեգրեսիայի մոդելում: Այն ցույց է տալիս, որ կա տարբերություն կանխատեսված և իրական արժեքների միջև, որը կարող է ավելի մեծ լինել, քան ստանդարտ սխալը ( 15.7464 ) կամ ավելի փոքր, քան ստանդարտ սխալ ( 4.0048 ): Այնուամենայնիվ, մեր միջին սխալը կլինի 8.3156471 , որը ստանդարտ սխալն է ։
Արդյունքում մոդելի նպատակն է նվազեցնել ստանդարտ սխալը: Որքան պակաս ստանդարտ սխալը, այնքան ճիշտ մոդելը:
2. Գործակիցներ
Ռեգեսիայի գործակիցը գնահատում է անհայտ արժեքների պատասխաններ: Ռեգրեսիայի հավասարման մեջ ( y = 1,0844x + 107,21 ), 1,0844 գործակիցն է , x կանխատեսող անկախ փոփոխականն է, 107.21 հաստատունը, իսկ y պատասխանի արժեքն է x -ի համար:
- A դրական գործակիցը կանխատեսում է, որ որքան բարձր է գործակիցը, այնքան բարձր է արձագանքըփոփոխական. Այն ցույց է տալիս համամասնական հարաբերություն:
- A բացասական գործակիցը կանխատեսում է, որ որքան բարձր է գործակիցը, այնքան ցածր են պատասխանի արժեքները: Այն ցույց է տալիս անհամաչափ հարաբերություն:
3. P-արժեքներ
Ռեգեսիոն վերլուծության մեջ p- արժեքները և գործակիցները համագործակցում են ձեզ տեղեկացնելու համար, թե արդյոք ձեր մոդելի հարաբերակցությունները վիճակագրորեն տեղին են և ինչպիսին են այդ հարաբերությունները: զրոյական վարկածը այն մասին, որ անկախ փոփոխականը կապ չունի կախված փոփոխականի հետ, փորձարկվում է p-արժեքը յուրաքանչյուր անկախ փոփոխականի համար: Անկախ փոփոխականի փոփոխությունների և կախված փոփոխականի տատանումների միջև կապ չկա, եթե չկա հարաբերակցություն:
- Ձեր ընտրանքի տվյալները բավականաչափ աջակցություն են տալիս կեղծելու զրոյական վարկածը: լրիվ բնակչություն, եթե փոփոխականի համար p-արժեքը պակաս քան ձեր նշանակության շեմը: Ձեր ապացույցները հաստատում են ոչ զրոյական հարաբերակցության հասկացությունը: Բնակչության մակարդակում անկախ փոփոխականի փոփոխությունները կապված են կախված փոփոխականի փոփոխությունների հետ:
- A p-արժեքը ավելի մեծ , քան նշանակալիության մակարդակը, երկու կողմից: , ենթադրում է, որ ձեր ընտրանքն ունի անբավարար ապացույց հաստատելու համար, որ կա ոչ զրոյական հարաբերակցություն :
Քանի որ նրանց p-արժեքները ( 5.787E-06 , 1.3E-06 ) պակաս են քան զգալի արժեքը ( 5.787E-06 ), Անկախ փոփոխականը (X) և Ընդհատումը վիճակագրորեն նշանակալի են , ինչպես երևում է ռեգրեսիայի արդյունքի օրինակում:
4. R-քառակուսի արժեքներ
Գծային ռեգրեսիայի մոդելների համար R-քառակուսի -ը ամբողջության չափում է : Այս հարաբերակցությունը ցույց է տալիս կախված փոփոխականի տարբերման տոկոսը , որը հաշվի են առնում անկախ գործոնները միասին վերցրած: Հարմար 0–100 տոկոս սանդղակով R-քառակուսի քանակականացնում է ձեր մոդելի և կախյալ փոփոխականի միջև կապի ուժեղությունը :
R2 արժեքը չափում է, թե որքանով է ռեգրեսիայի մոդելը համապատասխանում ձեր տվյալներին: Որքան բարձր թիվը , այնքան ավելի լավ իրագործելի է մոդելը:
Եզրակացություն
Հուսով եմ, որ այս հոդվածը ձեզ տվել է ձեռնարկ, թե ինչպես կարելի է հաշվարկել ռեգրեսիայի ստանդարտ սխալը Excel -ում: Այս բոլոր ընթացակարգերը պետք է սովորել և կիրառել ձեր տվյալների բազայում: Նայեք գործնական աշխատանքային գրքույկին և փորձարկեք այս հմտությունները: Մենք մոտիվացված ենք շարունակելու նման ձեռնարկներ պատրաստել ձեր արժեքավոր աջակցության շնորհիվ:
Խնդրում ենք կապվել մեզ հետ, եթե ունեք հարցեր: Նաև ազատ զգացեք մեկնաբանություններ թողնել ստորև բերված բաժնում:
Մենք՝ Exceldemy Թիմը, միշտ արձագանքում ենք ձեր հարցումներին:
Մնացեք մեզ հետ և շարունակեք սովորել:
