
INHOUDSOPGAWE
Ons gebruik regressie-analise wanneer ons data van twee veranderlikes uit twee verskillende bronne het en 'n verhouding tussen hulle wil bou. Regressie-analise voorsien ons van 'n lineêre model wat ons in staat stel om moontlike uitkomste te voorspel. Daar sal om ooglopende redes 'n paar verskille tussen die voorspelde en werklike waardes wees. As gevolg hiervan, bereken ons die standaardfout deur die regressiemodel te gebruik, wat die gemiddelde fout tussen voorspelde en werklike waardes is. In hierdie tutoriaal sal ons jou wys hoe om die standaardfout van regressie-analise in Excel te bereken.
Laai Oefenwerkboek af
Laai hierdie oefenwerkboek af om te oefen terwyl jy is lees hierdie artikel.
Regressiestandaardfout.xlsx
4 eenvoudige stappe om standaardfout van regressie in Excel te bereken
Veronderstel jy het 'n datastel met 'n onafhanklike veranderlike ( X ) en 'n afhanklike veranderlike ( Y ) . Soos jy kan sien, het hulle geen noemenswaardige verhouding nie. Maar ons wil een bou. As gevolg hiervan sal ons Regressie-analise gebruik om 'n lineêre verhouding tussen die twee te skep. Ons sal die standaardfout tussen die twee veranderlikes bereken deur die regressie-analise te gebruik. Ons gaan oor sommige van die regressiemodel se parameters in die tweede helfte van die artikel om jou te help om dit te interpreteer.

Stap 1: Pas Data-analise-opdrag toe opSkep 'n regressiemodel
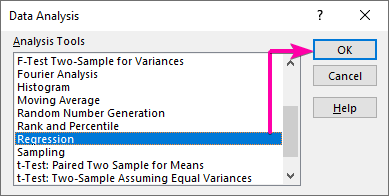
- Gaan eerstens na die Data -oortjie en klik op die Data-analise opdrag.

- Van die Data-analise -lysblokkie, kies die Regressie opsie.
- Klik dan OK .
Stap 2: Voeg toevoer- en afvoerreeks in regressiekassie in
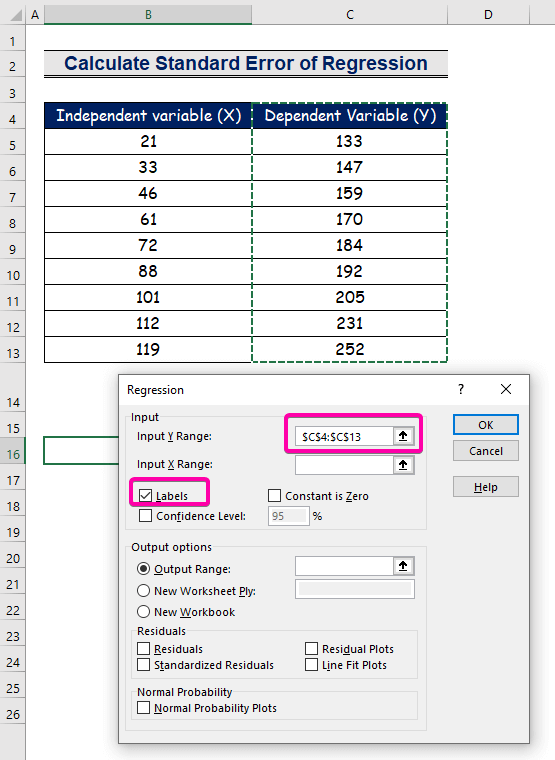
- Vir die invoer Y-reeks , kies die reeks C4:C13 met die kopskrif.
- Klik op die Etikette -merkblokkie.
- Kies die reeks B4:B13 vir die Invoer X-reeks .
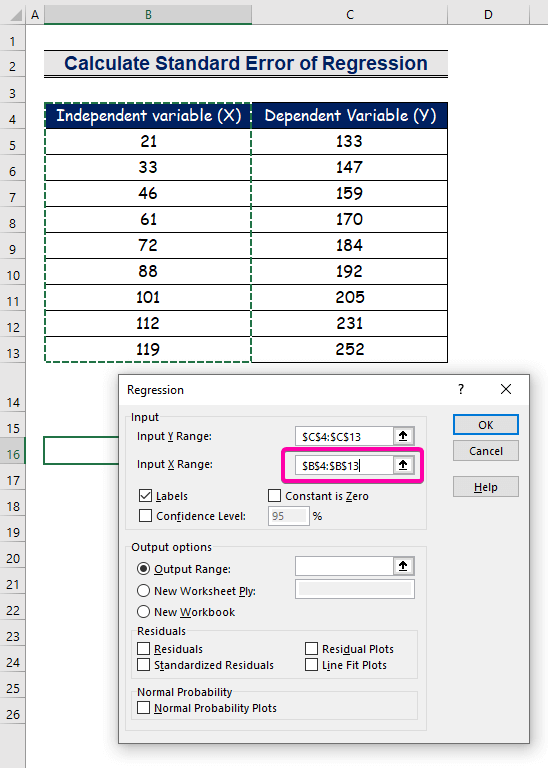
- Om die resultaat in die voorkeurligging te kry, kies enige sel ( B16 ) vir die Uitvoerreeks .
- Ten slotte, klik OK .

Lees meer: Hoe om standaardfout van proporsie in Excel te bereken (met maklike stappe)
Stap 3: Vind uit standaardfout
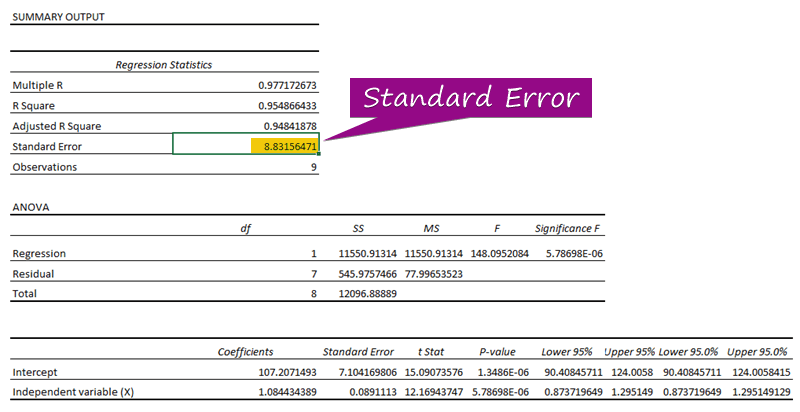
- Vanaf die regressie-analise, kan jy die waarde van verkry die standaardfout ( 3156471 ).
Lees meer: Hoe om oorblywende standaardfout in Excel te vind (2 maklike metodes)
Stap 4: Teken regressiemodelgrafiek
- Klik eerstens op die Voeg in oortjie.
- Van die Charts groep, kies die Scatter grafiek.
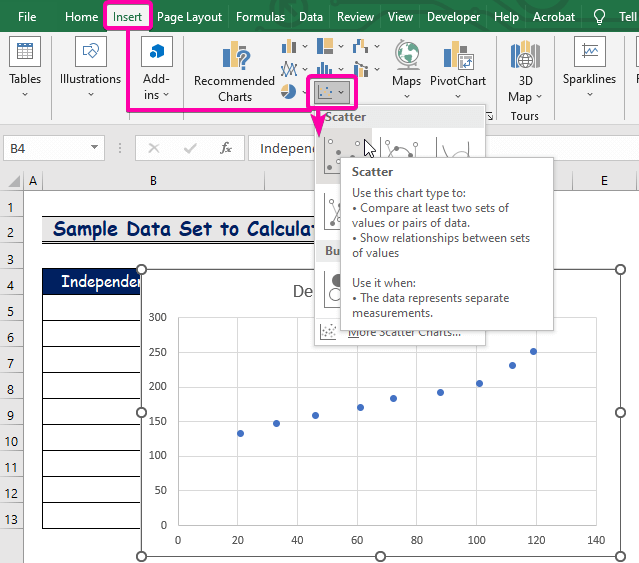
- Regsklik oor een van diepunte.
- Van die opsies, kies die Voeg neiginglyn by -opsie.
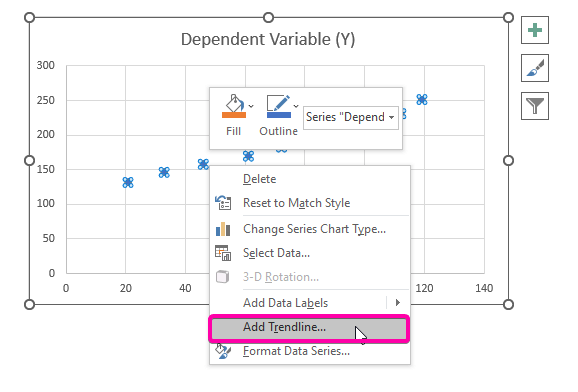
- Daarom, jou regressie-analise -grafiek sal geplot word soos die prent hieronder getoon.

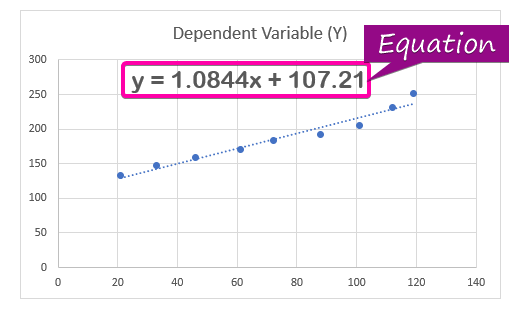
- Om die
regressie-analise -vergelyking, klik op die Vertoon vergelyking op grafiek -opsie van die Formaat-tendenslyn.

- Gevolglik is die vergelyking ( y = 1.0844x + 107.21 ) van die regressie-analise sal in die grafiek verskyn.
Notas:
Jy kan die verskil tussen die voorspelde waardes en die werklike bereken waardes uit die vergelyking van regressie-analise.
Stappe:
- Tik die formule om die regressie-analise-vergelyking voor te stel.
=1.0844*B5 + 107.21 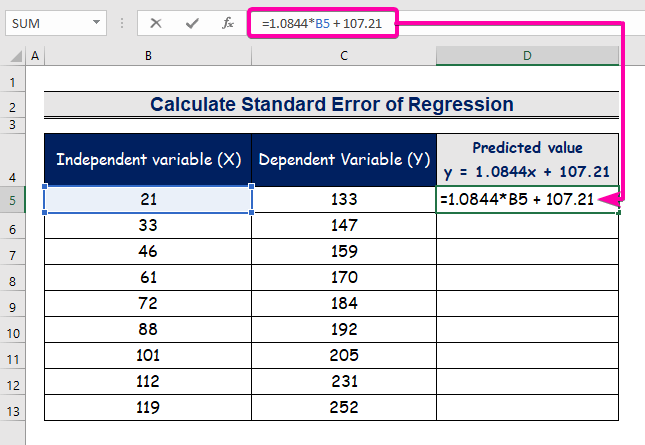
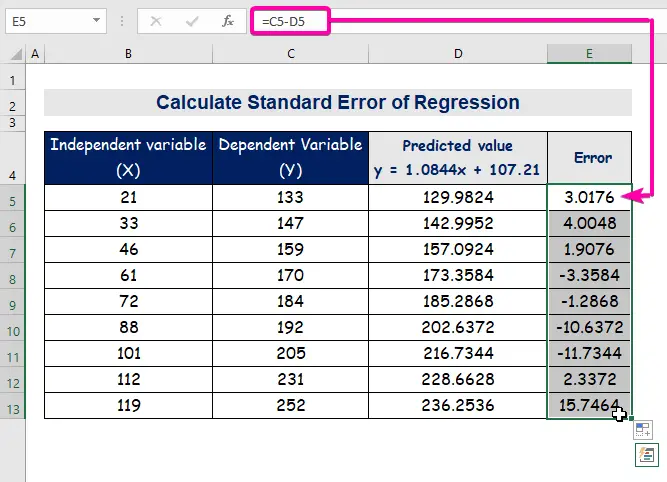
- Daarom sal jy die eerste voorspelde waarde kry ( 129.9824 ), wat verskil van die werklike waarde ( 133 ).

- Gebruik die Outovul-nutsding om kolom D outomaties in te vul.

- Om die fout te bereken, tik die volgende formule om trek af.
=C5-D5 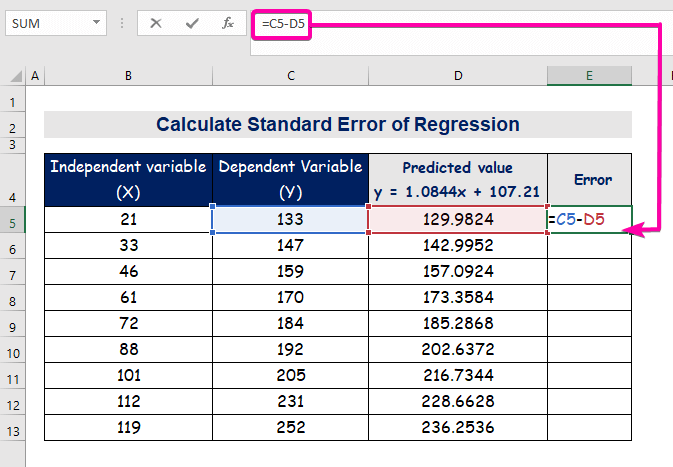
- Laastens, outovul kolom E om die foutwaardes te vind.
Lees meer: Hoe om standaardfout van regressiehelling in te bereken Excel
Die interpretasie van regressie-analise in Excel
1. Standaardfout
Ons kan uit die regressie-analisevergelyking sien dat daar altyd 'n verskil of fout tussen die voorspelde en werklike waardes is. As gevolg hiervan moet ons die gemiddelde afwyking van die verskille bereken.
'n standaardfout verteenwoordig die gemiddelde fout tussen die voorspelde waarde en die werklike waarde. Ons het 8.3156471 as die standaardfout in ons voorbeeldregressiemodel ontdek. Dit dui aan dat daar 'n verskil is tussen die voorspelde en werklike waardes, wat groter kan wees as die standaardfout ( 15.7464 ) of minder as die standaardfout ( 4.0048 ). Ons gemiddelde fout sal egter 8.3156471 wees, wat die standaardfout is.
Gevolglik is die model se doel om die standaardfout te verminder. Hoe laer die standaardfout is, hoe meer akkuraat is die model.
2. Koëffisiënte
Die regressiekoëffisiënt evalueer die reaksies van onbekende waardes. In die regressievergelyking ( y = 1,0844x + 107,21 ), is 1,0844 die koëffisiënt , x is die voorspeller onafhanklike veranderlike, 107.21 is die konstante, en y is die responswaarde vir die x .
- 'n positiewe koëffisiënt voorspel dat hoe hoër die koëffisiënt, hoe hoër die responsveranderlike. Dit dui op 'n proporsionele verhouding.
- 'n negatiewe koëffisiënt voorspel dat hoe hoër die koëffisiënt, hoe laer die responswaardes. Dit dui op 'n disproporsionele verhouding.
3. P-waardes
In regressie-analise, p- waardes en koëffisiënte werk saam om jou in te lig of korrelasies in jou model statisties relevant is en hoe daardie verhoudings is. Die nulhipotese dat die onafhanklike veranderlike geen verband met die afhanklike veranderlike het nie, word getoets deur die p-waarde vir elke onafhanklike veranderlike te gebruik. Daar is geen verband tussen veranderinge in die onafhanklike veranderlike en variasies in die afhanklike veranderlike as daar geen korrelasie is nie.
- Jou steekproefdata gee genoeg ondersteuning om die nulhipotese vir die vervalsing te vervals. volle populasie as die p-waarde vir 'n veranderlike minder as jou betekenisdrempel is. Jou bewyse ondersteun die idee van 'n nie-nul korrelasie . Op die bevolkingsvlak word veranderinge in die onafhanklike veranderlike gekoppel aan veranderinge in die afhanklike veranderlike.
- 'n p-waarde groter as die betekenisvlak, aan weerskante , stel voor dat jou steekproef onvoldoende bewys het om vas te stel dat 'n nie-nul korrelasie bestaan.
Omdat hulle p-waardes ( 5.787E-06 , 1.3E-06 ) is minder as die beduidende waarde ( 5.787E-06 ), die Onafhanklike Veranderlike (X) en Afsnit is statisties betekenisvol , soos gesien in die regressie-uitsetvoorbeeld.
4. R-kwadraatwaardes
Vir lineêre regressiemodelle is R-kwadraat 'n volledigheidsmeting . Hierdie verhouding toon die persentasie van variansie in die afhanklike veranderlike wat die onafhanklike faktore in ag neem wanneer dit saam geneem word. Op 'n handige 0–100 persent skaal, kwantifiseer R-kwadraat die sterkte van die verband tussen jou model en die afhanklike veranderlike.
Die R2 waarde is 'n maatstaf van hoe goed die regressiemodel by jou data pas. Hoe hoër die getal , hoe beter uitvoerbaar is die model.
Gevolgtrekking
Ek hoop hierdie artikel het jou 'n handleiding oor hoe om die standaardfout van regressie in Excel te bereken. Al hierdie prosedures moet aangeleer word en op jou datastel toegepas word. Kyk na die oefenwerkboek en stel hierdie vaardighede op die proef. Ons is gemotiveerd om aan te hou om tutoriale soos hierdie te maak vanweë jou waardevolle ondersteuning.
Kontak ons asseblief as jy enige vrae het. Laat ook gerus opmerkings in die afdeling hieronder.
Ons, die Exceldemy -span, reageer altyd op jou navrae.
Bly by ons en hou aan om te leer.
