
Innehållsförteckning
Vi använder regressionsanalys. när vi har data från två variabler från två olika källor och vill skapa ett samband mellan dem. Regressionsanalys ger oss en linjär modell som gör det möjligt att förutsäga möjliga resultat. Av uppenbara skäl kommer det att finnas vissa skillnader mellan de förutsedda och de faktiska värdena. Som ett resultat av detta kan vi beräkna standardfelet med hjälp av regressionsmodellen, vilket är det genomsnittliga felet mellan det förutspådda och det faktiska värdet. I den här handledningen kommer vi att visa hur man beräknar standardfelet för regressionsanalys i Excel .
Ladda ner övningsboken
Ladda ner den här arbetsboken för att träna medan du läser den här artikeln.
Regression standardfel.xlsx4 enkla steg för att beräkna standardfelet för regression i Excel
Anta att du har en datamängd med en oberoende variabel ( X ) och en beroende variabel ( Y ) Som du kan se har de inget signifikant samband. Men vi vill bygga upp ett. Därför använder vi Regressionsanalys för att skapa ett linjärt samband mellan de två. Vi beräknar standardfelet mellan de två variablerna med hjälp av regressionsanalysen. Vi går igenom några av regressionsmodellens parametrar i den andra halvan av artikeln för att hjälpa dig att tolka den.

Steg 1: Tillämpa kommandot Dataanalys för att skapa en regressionsmodell
- Först går du till Uppgifter och klicka på fliken Analys av data kommandot.

- Från Analys av data i listrutan, väljer du den Regression alternativ.
- Klicka sedan på OK .
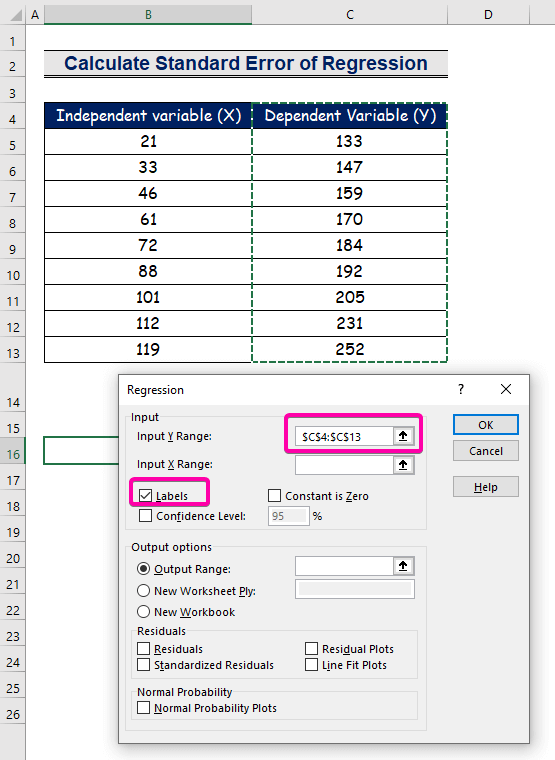
Steg 2: Infoga inmatnings- och utdataområde i regressionsrutan
- För Ingång Y-område , välj intervallet C4:C13 med rubriken.
- Klicka på Etiketter kryssrutan.
- Välj intervallet B4:B13 för Ingång X Område .
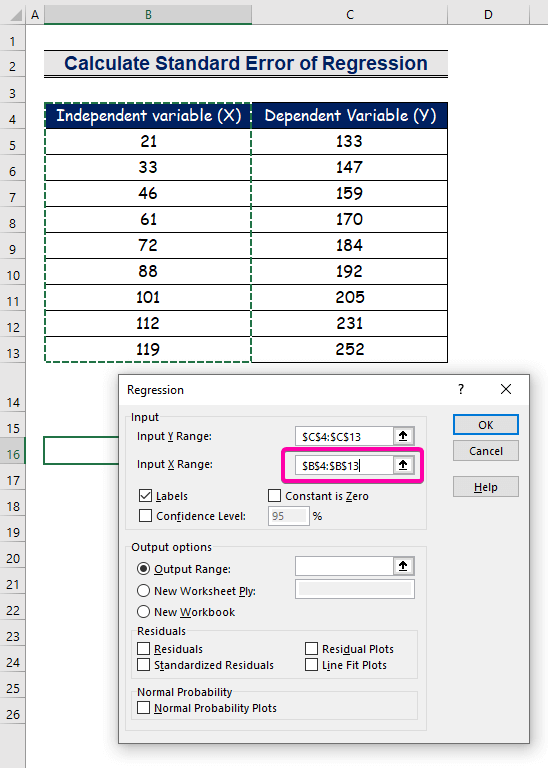
- Om du vill få resultatet på önskad plats markerar du en valfri cell ( B16 ) för Utgångsområde .
- Slutligen klickar du på OK .

Läs mer: Hur man beräknar standardfelet för en andel i Excel (med enkla steg)
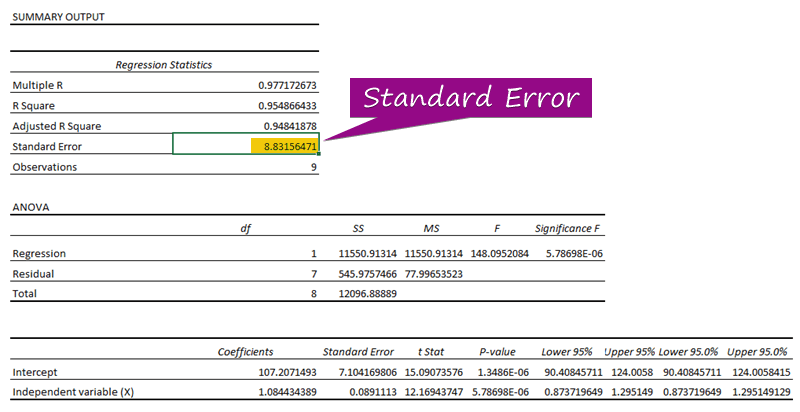
Steg 3: Ta reda på standardfelet
- Från regressionsanalysen kan du få fram värdet på standardfelet ( 3156471 ).
Läs mer: Hur man hittar residual standardfel i Excel (2 enkla metoder)
Steg 4: Plotta regressionsmodellen
- Först klickar du på Infoga fliken.
- Från Diagram grupp, välj den Spridning diagram.
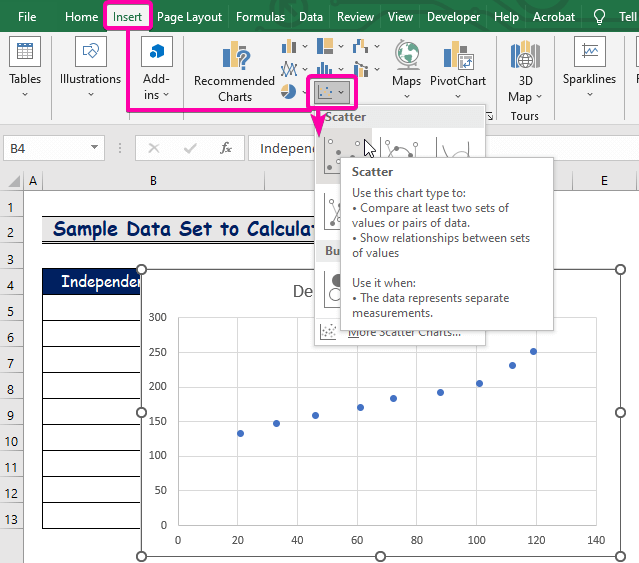
- Högerklicka på över en av punkterna.
- Välj alternativet Lägg till trendlinje alternativ.
- Därför bör din regressionsanalys. diagrammet kommer att visas som bilden nedan.

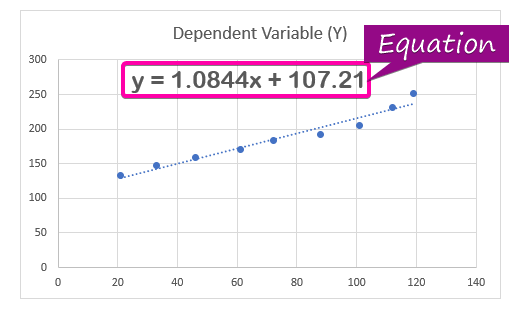
- Visa den regressionsanalys. ekvationen, klicka på Visa ekvationen på diagrammet från alternativet Format Trendlinje.

- Därför kan ekvationen ( y = 1,0844x + 107,21 ) av regressionsanalysen kommer att visas i diagrammet.
Anteckningar:
Du kan beräkna skillnaden mellan de förutspådda värdena och de faktiska värdena med hjälp av regressionsanalysens ekvation.
Steg:
- Ange formeln för att representera ekvationen för regressionsanalysen.
=1.0844*B5 + 107.21 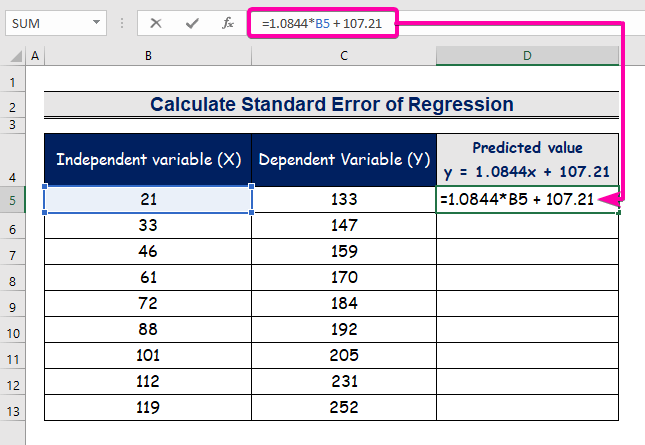
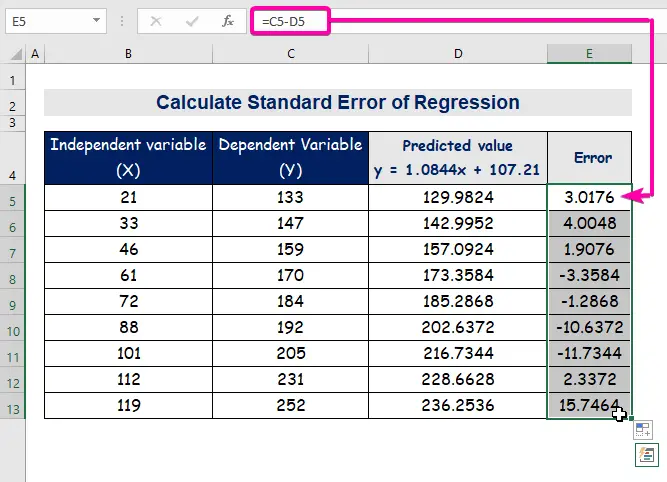
- Därför får du det första förutspådda värdet ( 129.9824 ), som skiljer sig från det faktiska värdet ( 133 ).

- Använd den Verktyg för automatisk ifyllning för att fylla ut kolumnen automatiskt D .

- För att beräkna felet skriver du följande formel för att subtrahera.
=C5-D5 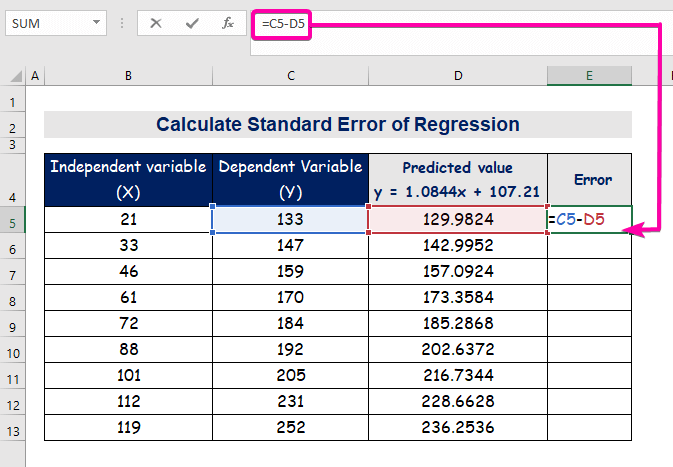
- Slutligen, automatisk utfyllnad av kolumnen E för att hitta felvärdena.
Läs mer: Hur man beräknar standardfelet för regressionens lutning i Excel
Tolkning av regressionsanalys i Excel
1. Standardfel
Av ekvationen för regressionsanalysen framgår att det alltid finns en skillnad eller ett fel mellan de förutspådda och de faktiska värdena, vilket innebär att vi måste beräkna den genomsnittliga avvikelsen för skillnaderna.
A standardfel representerar det genomsnittliga felet mellan det förutspådda värdet och det faktiska värdet. Vi upptäckte att 8.3156471 som standardfel Det visar att det finns en skillnad mellan det förutspådda och det faktiska värdet, som kan vara större än den standardfel ( 15.7464 ) eller mindre än standardfel ( 4.0048 ). Vår genomsnittligt fel kommer att vara 8.3156471 , som är den standardfel .
Modellens mål är därför att minska standardfelet. lägre standardfelet, desto mer korrekt modellen.
2. Koefficienter
Regressionskoefficienten utvärderar svaren på okända värden. I regressionsekvationen ( y = 1,0844x + 107,21 ), 1.0844 är den koefficient , x är den oberoende variabeln för prediktion, 107.21 är konstanten, och y är svarsvärdet för x .
- A Positiv koefficient. förutsäger att ju högre koefficienten är, desto högre är svarsvariabeln. Det indikerar att en proportionell relation.
- A negativ koefficient förutsäger att ju högre koefficienten är, desto lägre är svarsvärdena. Det tyder på en oproportionerlig relation.
3. P-värden
I regressionsanalys, p-värden och koefficienter samarbetar för att informera dig om huruvida korrelationer i din modell är statistiskt relevanta och hur dessa relationer ser ut. nollhypotes att den oberoende variabeln inte har något samband med den beroende variabeln testas med hjälp av p-värde Det finns inget samband mellan förändringar i den oberoende variabeln och variationer i den beroende variabeln om det inte finns någon korrelation.
- Dina exempeluppgifter ger tillräckligt stöd för att förfalska nollhypotesen för hela populationen om den p-värde för en variabel är mindre än ert tröskelvärde för signifikans. Era bevis stöder uppfattningen om att det finns en korrelation som inte är noll. På befolkningsnivå är förändringar i den oberoende variabeln kopplade till förändringar i den beroende variabeln.
- A p-värde större än signifikansnivån, på båda sidor, tyder på att ditt urval har otillräckliga bevis för att fastställa att en korrelation som inte är noll finns.
Eftersom deras p-värden ( 5.787E-06 , 1.3E-06 ) är mindre än den betydande värde ( 5.787E-06 ), den Oberoende variabel (X) och Intercept är statistiskt signifikant , vilket framgår av exemplet med regressionsresultatet.
4. R-kvadratvärden
För linjära regressionsmodeller, R-kvadrat är en Mätning av fullständighet. Detta förhållande visar hur stor Procentuell andel av variansen. i den beroende variabeln som de oberoende faktorerna tillsammans står för. På en praktisk 0-100 procentuell skala, R-kvadrat kvantifierar den styrka av sambandet mellan din modell och den beroende variabeln.
R2 värdet är ett mått på hur väl regressionsmodellen passar in på dina data. högre nummer , den bättre genomförbara modellen.
Slutsats
Jag hoppas att den här artikeln har gett dig en handledning om hur man beräknar standardfelet för regression i Excel Alla dessa procedurer bör du lära dig och tillämpa på ditt dataset. Ta en titt på övningsarbetsboken och sätt dessa färdigheter på prov. Vi är motiverade att fortsätta göra sådana här handledningar tack vare ditt värdefulla stöd.
Kontakta oss gärna om du har några frågor eller lämna kommentarer i avsnittet nedan.
Vi, den Excellent Teamet är alltid lyhörda för dina frågor.
Stanna hos oss och lär dig hela tiden.
