
Სარჩევი
ჩვენ ვიყენებთ რეგრესიის ანალიზს , როდესაც გვაქვს მონაცემები ორი ცვლადისგან ორი განსხვავებული წყაროდან და გვინდა დავამყაროთ ურთიერთობა მათ შორის. რეგრესიის ანალიზი გვაწვდის ხაზოვან მოდელს, რომელიც საშუალებას გვაძლევს ვიწინასწარმეტყველოთ შესაძლო შედეგები. აშკარა მიზეზების გამო იქნება გარკვეული განსხვავებები პროგნოზირებულ და რეალურ მნიშვნელობებს შორის. შედეგად, ჩვენ ვიანგარიშებთ სტანდარტულ შეცდომას რეგრესიის მოდელის გამოყენებით, რომელიც არის საშუალო შეცდომა პროგნოზირებულ და რეალურ მნიშვნელობებს შორის. ამ სახელმძღვანელოში, ჩვენ გაჩვენებთ, თუ როგორ უნდა გამოვთვალოთ რეგრესიული ანალიზის სტანდარტული შეცდომა Excel -ში.
ჩამოტვირთეთ სავარჯიშო სამუშაო წიგნი
ჩამოტვირთეთ ეს სავარჯიშო სამუშაო წიგნი, რომ ივარჯიშოთ სანამ ხართ ამ სტატიის წაკითხვა.
რეგრესიის სტანდარტული შეცდომა.xlsx
4 მარტივი ნაბიჯი Excel-ში რეგრესიის სტანდარტული შეცდომის გამოსათვლელად
ვუშვათ, რომ გაქვთ მონაცემთა ნაკრები დამოუკიდებელი ცვლადით ( X ) და დამოკიდებული ცვლადით ( Y ) . როგორც ხედავთ, მათ არ აქვთ მნიშვნელოვანი ურთიერთობა. მაგრამ ჩვენ გვინდა ავაშენოთ ერთი. შედეგად, ჩვენ გამოვიყენებთ რეგრესიის ანალიზს ამ ორს შორის წრფივი ურთიერთობის შესაქმნელად. ჩვენ გამოვთვლით სტანდარტულ შეცდომას ორ ცვლადს შორის რეგრესიული ანალიზის გამოყენებით. ჩვენ განვიხილავთ რეგრესიის მოდელის ზოგიერთ პარამეტრს სტატიის მეორე ნახევარში, რათა დაგეხმაროთ მის ინტერპრეტაციაში.

ნაბიჯი 1: მონაცემთა ანალიზის ბრძანების გამოყენებაშექმენით რეგრესიული მოდელი
- პირველ რიგში, გადადით მონაცემები ჩანართზე და დააწკაპუნეთ მონაცემთა ანალიზი ბრძანება.

- მონაცემთა ანალიზი სიის ველიდან აირჩიეთ რეგრესია ვარიანტი.
- შემდეგ, დააწკაპუნეთ OK .
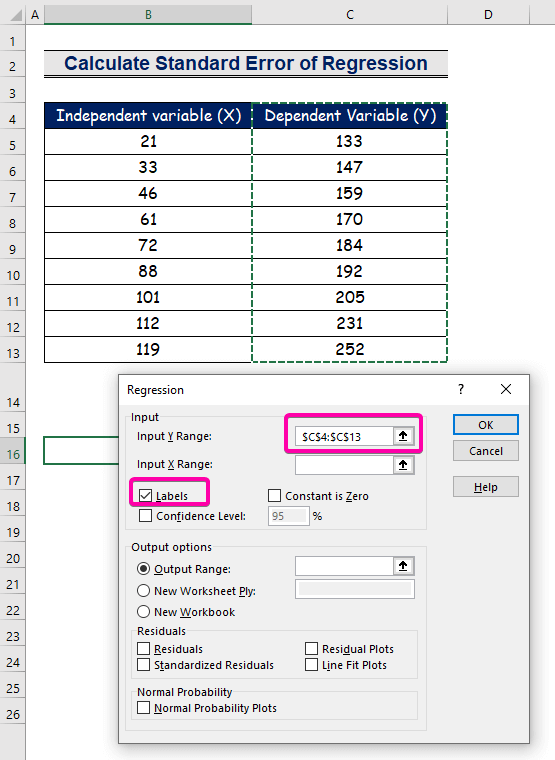
ნაბიჯი 2: შეყვანის და გამომავალი დიაპაზონის ჩასმა რეგრესიის ველში
- შეყვანის Y დიაპაზონისთვის აირჩიეთ დიაპაზონი C4:C13 სათაურით.
- დააწკაპუნეთ ველზე ეტიკეტები .
- აირჩიეთ დიაპაზონი B4:B13 შეყვანის X დიაპაზონისთვის .
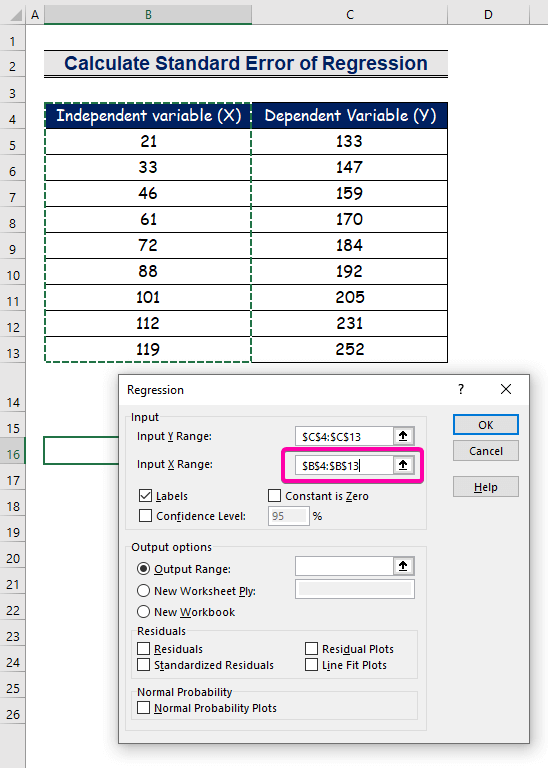
- შედეგის მისაღებად სასურველ ადგილას აირჩიეთ ნებისმიერი უჯრედი ( B16 ) გამომავალი დიაპაზონისთვის .
- და ბოლოს დააწკაპუნეთ OK .

დაწვრილებით: როგორ გამოვთვალოთ პროპორციის სტანდარტული შეცდომა Excel-ში (მარტივი ნაბიჯებით)
ნაბიჯი 3: იპოვნეთ სტანდარტული შეცდომა
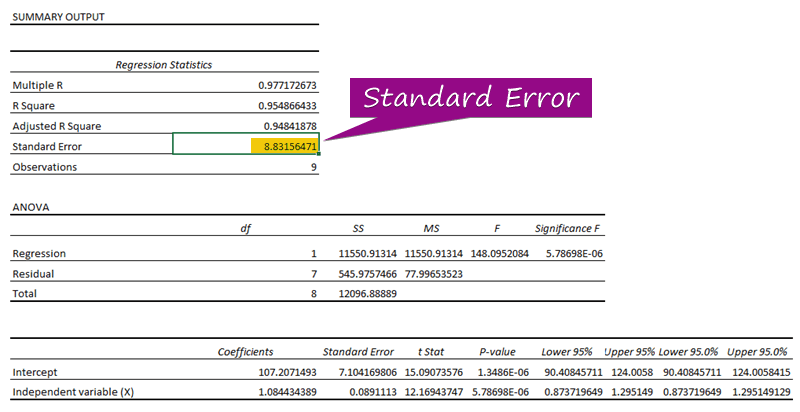
- From რეგრესიის ანალიზით, შეგიძლიათ მიიღოთ მნიშვნელობა სტანდარტული შეცდომა ( 3156471 ).
დაწვრილებით: როგორ ნარჩენი სტანდარტული შეცდომის საპოვნელად Excel-ში (2 მარტივი მეთოდი)
ნაბიჯი 4: შედგენილი რეგრესიის მოდელის დიაგრამა
- პირველ რიგში, დააწკაპუნეთ ჩასმა ჩანართი.
- Charts ჯგუფიდან აირჩიეთ Scatter დიაგრამა.
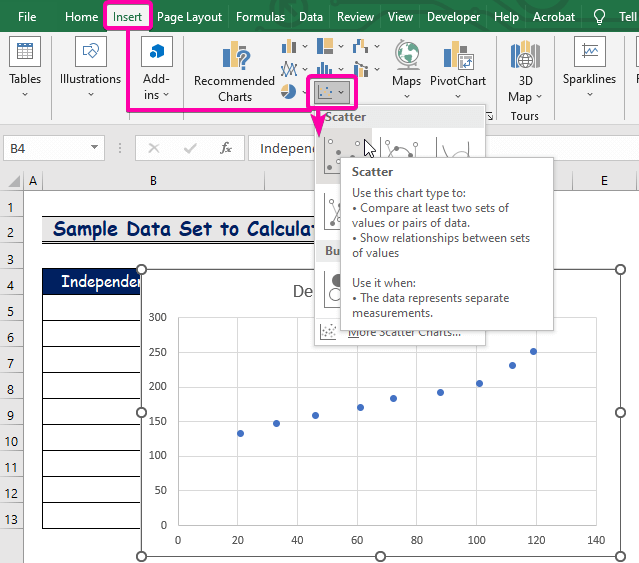
- დააწკაპუნეთ მარჯვენა ღილაკით ერთ-ერთზექულები.
- ოფციებიდან აირჩიეთ ტენდენციის ხაზის დამატება ოპცია.
- ამიტომ, თქვენი რეგრესიის ანალიზი დიაგრამა გამოსახული იქნება როგორც ქვემოთ ნაჩვენები სურათი.

- <-ის ჩვენება 8> რეგრესიის ანალიზი განტოლება, დააწკაპუნეთ განტოლების ჩვენება დიაგრამაზე ოფციაზე ფორმატი Trendline.

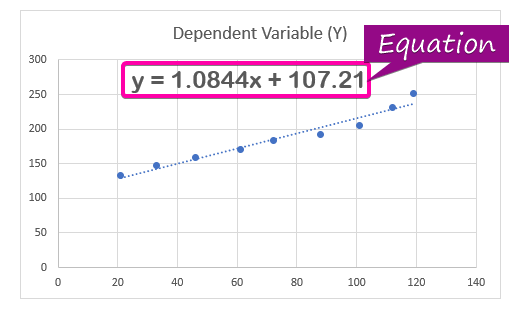
- შედეგად, რეგრესიის ანალიზის განტოლება ( y = 1,0844x + 107,21 ) დიაგრამაზე გამოჩნდება.
შენიშვნები:
შეგიძლიათ გამოთვალოთ განსხვავება პროგნოზირებულ მნიშვნელობებსა და რეალურს შორის მნიშვნელობები რეგრესიული ანალიზის განტოლებიდან.
ეტაპები:
- აკრიფეთ ფორმულა რეგრესიის ანალიზის განტოლების წარმოსადგენად.
=1.0844*B5 + 107.21 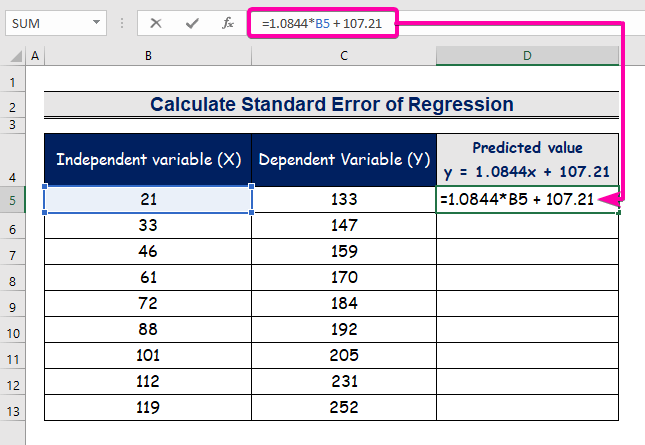
- აქედან გამომდინარე, თქვენ მიიღებთ პირველ პროგნოზირებულ მნიშვნელობას ( 129.9824 ), რომელიც განსხვავდება რეალური მნიშვნელობისაგან ( 133 ).

- გამოიყენეთ ავტომატური შევსების ხელსაწყო სვეტის ავტომატური შევსებისთვის D .

- შეცდომის გამოსათვლელად, ჩაწერეთ შემდეგი ფორმულა გამოკლება.
=C5-D5 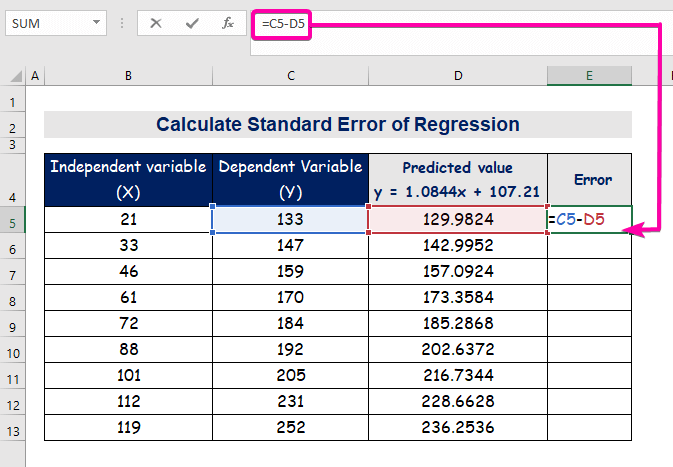
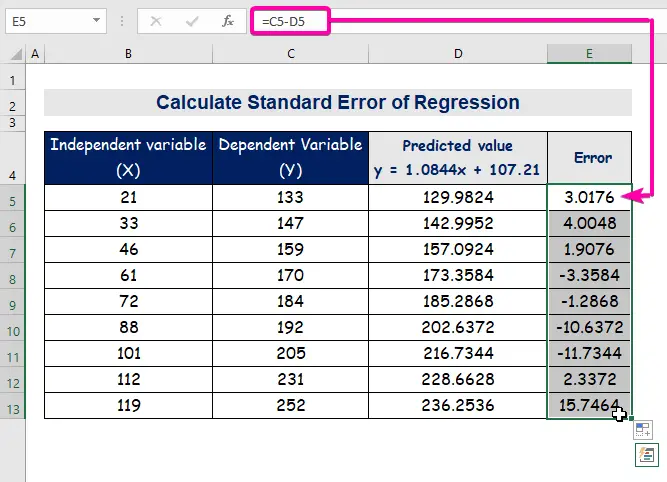
- ბოლოს, ავტომატურად შევსება სვეტი E შეცდომის მნიშვნელობების საპოვნელად.
დაწვრილებით: როგორ გამოვთვალოთ რეგრესიის ფერდობის სტანდარტული შეცდომა Excel
რეგრესიის ანალიზის ინტერპრეტაცია Excel-ში
1. სტანდარტული შეცდომა
რეგრესიული ანალიზის განტოლებიდან ვხედავთ, რომ ყოველთვის არის განსხვავება ან შეცდომა პროგნოზირებულ და რეალურ მნიშვნელობებს შორის. შედეგად, ჩვენ უნდა გამოვთვალოთ განსხვავებების საშუალო გადახრა.
სტანდარტული შეცდომა ასახავს საშუალო შეცდომას პროგნოზირებულ მნიშვნელობასა და რეალურ მნიშვნელობას შორის. ჩვენ აღმოვაჩინეთ 8.3156471 როგორც სტანდარტული შეცდომა ჩვენს მაგალითში რეგრესიის მოდელში. ეს მიუთითებს, რომ არსებობს განსხვავება პროგნოზირებულ და რეალურ მნიშვნელობებს შორის, რომელიც შეიძლება იყოს სტანდარტული შეცდომა ( 15.7464 ) ან ნაკლები. სტანდარტული შეცდომა ( 4.0048 ). თუმცა, ჩვენი საშუალო შეცდომა იქნება 8.3156471 , რაც არის სტანდარტული შეცდომა .
შედეგად, მოდელის მიზანია სტანდარტული შეცდომის შემცირება. რაც უფრო დაბალია სტანდარტული შეცდომა, მით უფრო ზუსტია მოდელი.
2. კოეფიციენტები
რეგრესიის კოეფიციენტი აფასებს უცნობი მნიშვნელობების პასუხები. რეგრესიის განტოლებაში ( y = 1,0844x + 107,21 ), 1,0844 არის კოეფიციენტი , x არის პროგნოზირების დამოუკიდებელი ცვლადი, 107.21 არის მუდმივი და y ეს არის პასუხის მნიშვნელობა x -ისთვის.
- A დადებითი კოეფიციენტი წინასწარმეტყველებს, რომ რაც უფრო მაღალია კოეფიციენტი, მით უფრო მაღალია პასუხიცვლადი. ეს მიუთითებს პროპორციულ ურთიერთობაზე.
- A უარყოფითი კოეფიციენტი პროგნოზირებს, რომ რაც უფრო მაღალია კოეფიციენტი, მით უფრო დაბალია პასუხის მნიშვნელობები. ეს მიუთითებს არაპროპორციულ ურთიერთობაზე.
3. P-მნიშვნელობები
რეგრესიის ანალიზში, p- მნიშვნელობები და კოეფიციენტები თანამშრომლობენ იმისთვის, რომ გაცნობოთ, არის თუ არა თქვენს მოდელში არსებული კორელაციები სტატისტიკურად შესაბამისი და როგორია ეს ურთიერთობები. ნულო ჰიპოთეზა იმის შესახებ, რომ დამოუკიდებელ ცვლადს არ აქვს კავშირი დამოკიდებულ ცვლადთან, შემოწმებულია p-მნიშვნელობის თითოეული დამოუკიდებელი ცვლადის გამოყენებით. არ არსებობს კავშირი დამოუკიდებელ ცვლადში ცვლილებებსა და დამოკიდებულ ცვლადში არსებულ ვარიაციებს შორის, თუ არ არსებობს კორელაცია.
- თქვენი ნიმუშის მონაცემები საკმარის მხარდაჭერას იძლევა გაყალბდეს ნულოვანი ჰიპოთეზის შესახებ სრული პოპულაცია, თუ p-მნიშვნელობა ცვლადისთვის მცირეა თქვენს მნიშვნელობის ზღურბლზე. თქვენი მტკიცებულება მხარს უჭერს არანულოვანი კორელაციის ცნებას . პოპულაციის დონეზე, დამოუკიდებელი ცვლადის ცვლილებები დაკავშირებულია დამოკიდებული ცვლადის ცვლილებებთან.
- A p-მნიშვნელობა აღემატება მნიშვნელოვნების დონეს, ორივე მხრიდან. , ვარაუდობს, რომ თქვენს ნიმუშს აქვს არასაკმარისი მტკიცებულება დასამტკიცებლად, რომ არანულოვანი კორელაცია არსებობს.
რადგან მათი p-მნიშვნელობები ( 5.787E-06 , 1.3E-06 ) არის ნაკლები ვიდრე მნიშვნელოვანი მნიშვნელობა ( 5.787E-06 ), დამოუკიდებელი ცვლადი (X) და გადაკვეთა არის სტატისტიკურად მნიშვნელოვანი , როგორც ეს ჩანს რეგრესიის გამომავალი მაგალითში.
4. R-კვადრატული მნიშვნელობები
წრფივი რეგრესიის მოდელებისთვის R-კვადრატი არის სისრულის საზომი . ეს თანაფარდობა გვიჩვენებს ვარიანტობის პროცენტს დამოკიდებულ ცვლადში, რომელსაც დამოუკიდებელი ფაქტორები ითვალისწინებენ ერთად აღებული. მოსახერხებელი 0-100 პროცენტული სკალით, R-კვადრატი რაოდენობრივად განსაზღვრავს თქვენს მოდელსა და დამოკიდებულ ცვლადს შორის კავშირის სიძლიერეს .
R2 მნიშვნელობა არის საზომი იმისა, თუ რამდენად შეესაბამება რეგრესიის მოდელი თქვენს მონაცემებს. რაც უფრო უმაღლესია ნომერი , მით უკეთესი შესაძლებელია მოდელი.
დასკვნა
იმედი მაქვს, რომ ეს სტატია მოგცემთ გაკვეთილი იმის შესახებ, თუ როგორ გამოვთვალოთ რეგრესიის სტანდარტული შეცდომა Excel -ში. ყველა ეს პროცედურა უნდა იყოს შესწავლილი და გამოყენებული თქვენს მონაცემთა ბაზაში. გადახედეთ პრაქტიკის სამუშაო წიგნს და გამოსცადეთ ეს უნარები. ჩვენ მოტივირებული ვართ გავაგრძელოთ მსგავსი გაკვეთილების გაკეთება თქვენი ღირებული მხარდაჭერის გამო.
გთხოვთ, დაგვიკავშირდეთ, თუ თქვენ გაქვთ რაიმე შეკითხვები. ასევე, მოგერიდებათ დატოვოთ კომენტარები ქვემოთ მოცემულ განყოფილებაში.
ჩვენ, Exceldemy გუნდი, ყოველთვის პასუხობს თქვენს შეკითხვებს.
დარჩით ჩვენთან და განაგრძეთ სწავლა.
