
Зміст
Ми використовуємо регресійний аналіз коли ми маємо дані про дві змінні з двох різних джерел і хочемо побудувати взаємозв'язок між ними. Регресійний аналіз дає нам лінійну модель, яка дозволяє спрогнозувати можливі результати. Зі зрозумілих причин між прогнозованими і фактичними значеннями будуть деякі відмінності. В результаті ми розрахувати стандартну похибку за допомогою регресійної моделі, яка є середньою похибкою між прогнозованими і фактичними значеннями. У цьому уроці ми покажемо вам, як розрахувати стандартну похибку регресійного аналізу в Excel .
Завантажити Практичний посібник
Завантажте цей практичний посібник, щоб потренуватися, поки ви читаєте цю статтю.
Стандартна помилка регресії.xlsx4 простих кроки для розрахунку стандартної помилки регресії в Excel
Припустимо, що у вас є набір даних з незалежна змінна ( X ) і залежна змінна ( Y ) Як бачите, вони не мають суттєвого взаємозв'язку, але ми хочемо його побудувати. В результаті, ми будемо використовувати Регресійний аналіз Ми розрахуємо стандартну похибку між двома змінними за допомогою регресійного аналізу. У другій частині статті ми розглянемо деякі параметри регресійної моделі, щоб допомогти вам її інтерпретувати.

Крок 1: Застосування команди "Аналіз даних" для створення регресійної моделі
- По-перше, зверніться до Дані та натисніть на вкладку Аналіз даних командування.

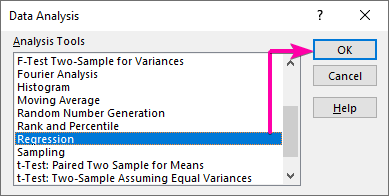
- Від Аналіз даних у вікні зі списком виберіть пункт Регресія варіант.
- Потім натисніть ГАРАЗД. .
Крок 2: Вставте вхідний та вихідний діапазон у поле регресії
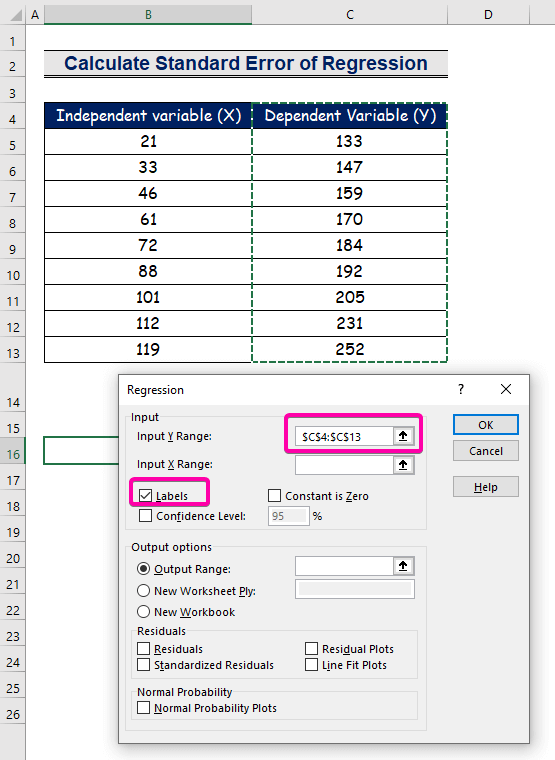
- Для Діапазон введення Y , виберіть діапазон C4:C13 із заголовком.
- Натисніть на кнопку Етикетки прапорець.
- Виберіть діапазон B4:B13 для Діапазон вхідного сигналу X .
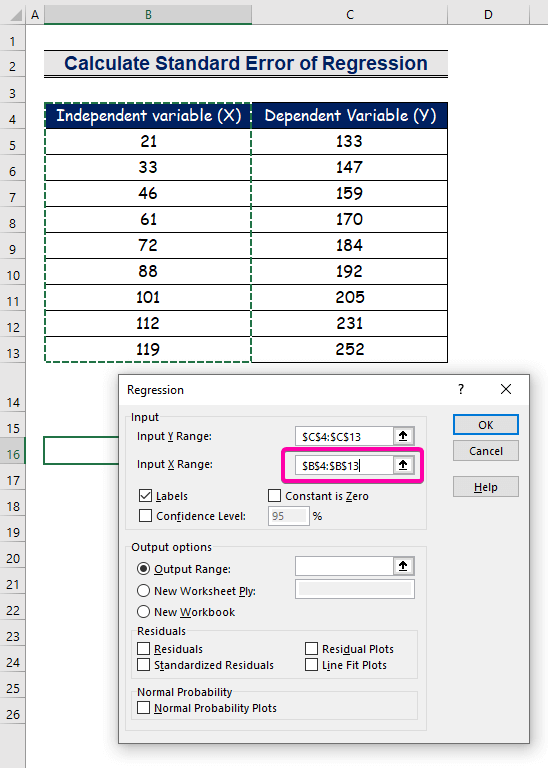
- Щоб отримати результат в бажаному місці, виберіть будь-яку комірку ( B16 ) для Вихідний діапазон .
- Нарешті, натисніть ГАРАЗД. .

Читати далі: Як розрахувати стандартну похибку пропорційності в Excel (з простими кроками)
Крок 3: З'ясуйте типову помилку
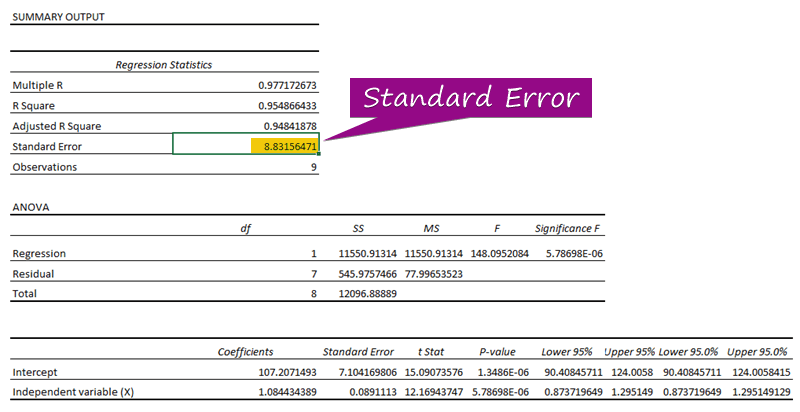
- З регресійного аналізу можна отримати значення стандартної похибки ( 3156471 ).
Читати далі: Як знайти залишкову середньоквадратичну похибку в Excel (2 простих способи)
Крок 4: Побудова графіка регресійної моделі
- По-перше, натисніть на кнопку Вставка рахунок.
- Від Графіки у групі, виберіть пункт Розкид діаграму.
- Клацніть правою кнопкою миші по одному з пунктів.
- Із запропонованих варіантів виберіть Додати лінію тренду варіант.
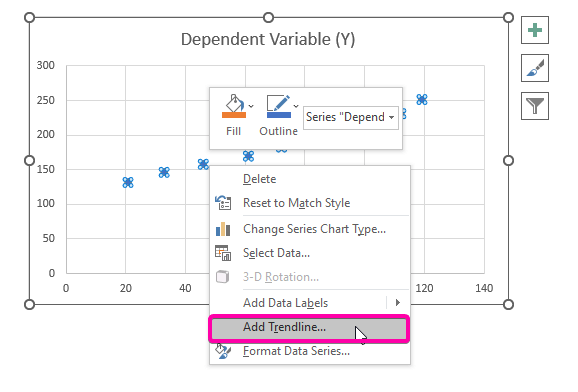
- Тому ваша регресійний аналіз Графік буде побудований у вигляді зображення, наведеного нижче.

- Для відображення регресійний аналіз рівняння, натисніть на кнопку Відобразити рівняння на графіку опція від Формат Trendline.

- Як наслідок, рівняння ( y = 1,0844x + 107,21 ) регресійного аналізу з'являться на графіку.
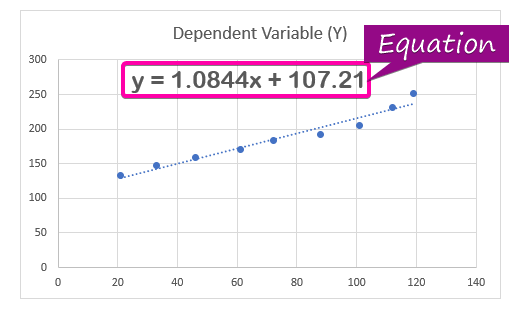
Нотатки:
Розрахувати різницю між прогнозованими та фактичними значеннями можна з рівняння регресійного аналізу.
Сходинки:
- Введіть формулу для представлення рівняння регресійного аналізу.
=1.0844*B5 + 107.21 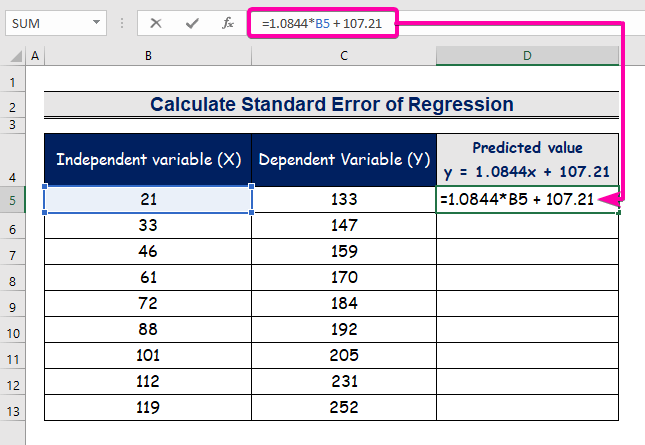
- Таким чином, ви отримаєте перше прогнозоване значення ( 129.9824 ), що відрізняється від фактичного значення ( 133 ).

- Скористайтеся кнопкою Інструмент автозаповнення для автозаповнення колонки D .

- Для розрахунку похибки введіть наступну формулу для віднімання.
=C5-D5 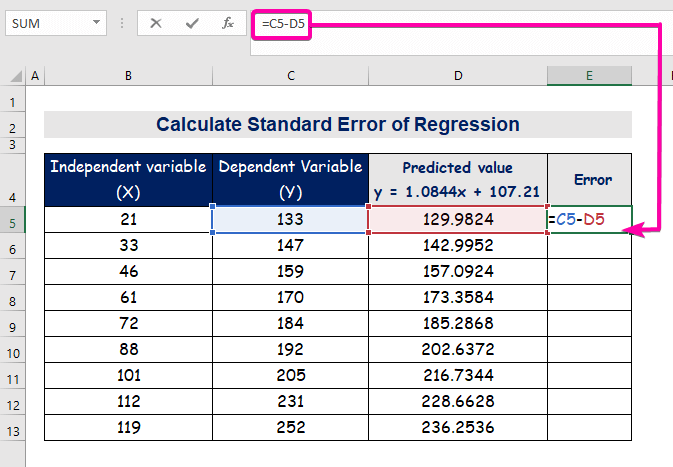
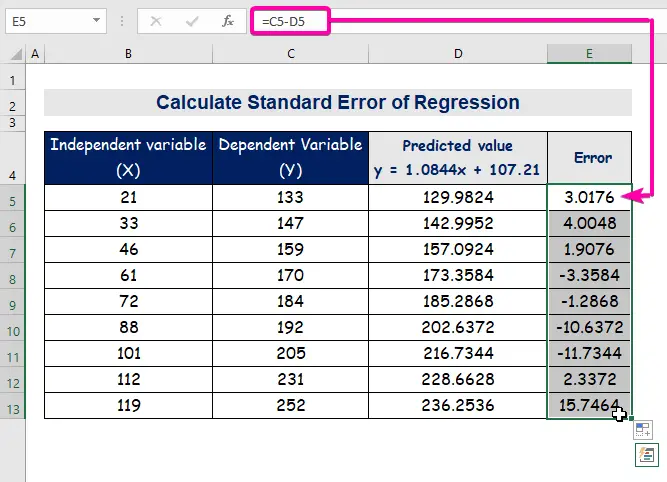
- Нарешті, колонка автозаповнення E для знаходження значень похибок.
Читати далі: Як розрахувати стандартну похибку нахилу регресії в Excel
Інтерпретація регресійного аналізу в Excel
1. стандартна помилка
З рівняння регресійного аналізу ми бачимо, що між прогнозованими та фактичними значеннями завжди існує різниця або помилка. Як наслідок, ми повинні розрахувати середнє відхилення різниць.
A стандартна похибка представляє середню похибку між прогнозованим та фактичним значенням. Ми виявили 8.3156471 в якості стандартна похибка У нашому прикладі регресійної моделі це свідчить про те, що між прогнозованими і фактичними значеннями існує різниця, яка може бути більшою, ніж стандартна похибка ( 15.7464 ) або менше, ніж стандартна похибка ( 4.0048 Втім, наші середня похибка буде 8.3156471 який є стандартна похибка .
Як наслідок, метою моделі є зменшення стандартної похибки. нижній чим більша стандартна похибка, тим більше точний модель.
2. коефіцієнти
Коефіцієнт регресії оцінює реакцію невідомих величин. У рівнянні регресії ( y = 1,0844x + 107,21 ), 1.0844 це коефіцієнт , x незалежна змінна предиктора, 107.21 константа, а y є значенням відгуку для x .
- A позитивний коефіцієнт передбачає, що чим вищий коефіцієнт, тим вища змінна відгуку. Це свідчить про те, що пропорційний стосунки.
- A від'ємний коефіцієнт прогнозує, що чим вищий коефіцієнт, тим нижчі значення відповідей. Це свідчить про непропорційний стосунки.
3. значення P-Values
У регресійному аналізі, p-значення і коефіцієнти співпрацюють, щоб повідомити вам, чи є кореляції у вашій моделі статистично значущими і якими є ці взаємозв'язки. нульова гіпотеза що незалежна змінна не має зв'язку з залежною змінною, перевіряється за допомогою p-значення Зв'язок між змінами незалежної змінної та змінами залежної змінної відсутній, якщо не існує кореляції.
- Дані Вашої вибірки дають достатню підставу для того, щоб фальсифікувати нульову гіпотезу для генеральної сукупності, якщо p-значення для змінної дорівнює менше Ваші докази підтверджують думку про те, що ненульова кореляція На рівні населення зміни в незалежній змінній пов'язані зі змінами в залежній змінній.
- A p-значення більший ніж рівень значущості з обох боків, свідчить про те, що ваша вибірка має недостатність доказів встановити, що ненульова кореляція існує.
Тому що їхні p-значення ( 5.787E-06 , 1.3E-06 ) є менше ніж у значне значення ( 5.787E-06 ), угода між Україною та ЄС про асоціацію між Україною та ЄС Незалежна змінна (X) і Перехоплення є статистично значущий як показано в прикладі виходу регресії.
4. значення R-квадрата
Для лінійних регресійних моделей, R-квадрат це оцінка повноти Це співвідношення показує, що відсоток відхилення у залежній змінній, на яку впливають незалежні фактори, взяті разом. 0-100 відсоткова шкала, R-квадрат кількісно оцінює сила зв'язку між вашою моделлю та залежною змінною.
На сьогоднішній день, на жаль, це не так. R2 є мірою того, наскільки добре регресійна модель відповідає вашим даним. вище в "Урядовому кур'єрі". кількість "Про те, що в Україні не існує жодного закону, який би краще реалістичність моделі.
Висновок
Я сподіваюся, що ця стаття дала вам підручник про те, як розрахувати стандартну помилку регресії в Excel Всі ці процедури необхідно вивчити і застосувати до вашого набору даних. Погляньте на практичний посібник і випробуйте ці навички на практиці. Ми мотивовані продовжувати створювати подібні посібники завдяки вашій цінній підтримці.
Якщо у Вас виникли запитання, будь ласка, звертайтеся до нас. Також не соромтеся залишати коментарі у розділі нижче.
Ми, представники Ексельдемія Team, завжди оперативно реагують на ваші запити.
Залишайтеся з нами і продовжуйте вчитися.
