
目次
を使用しています。 回帰分析 2つの異なるソースから得た2つの変数のデータがあり、それらの間に関係を構築したい場合。 回帰分析 は、可能な結果を予測するための線形モデルを提供する。 予測値と実際の値には、明らかな理由で多少の違いがある。 その結果、我々は 標準誤差を計算する での回帰分析の標準誤差を計算する方法を紹介します。 エクセル .
練習用ワークブックをダウンロードする
この練習用ワークブックをダウンロードして、この記事を読みながらエクササイズしてください。
回帰標準誤差.xlsxExcelで回帰の標準誤差を計算する4つの簡単なステップ
を持つデータセットがあるとします。 独立変数( X ) であり 従属変数( Y ) このように、両者には有意な関係がありません。 しかし、有意な関係を構築したいのです。 そのために 回帰分析 を使って、両者の間に線形関係を作ります。 回帰分析を使って、2つの変数の間の標準誤差を計算します。 後半では、回帰モデルのパラメータをいくつか見て、解釈の手助けをします。

ステップ1:データ解析コマンドを適用して回帰モデルを作成する
- まずは データ タブをクリックし データ分析 コマンドを使用します。

- より データ分析 リストボックスで リグレッション オプションを使用します。
- をクリックします。 よっしゃー .
ステップ2:リグレッションボックスに入力と出力の範囲を挿入する
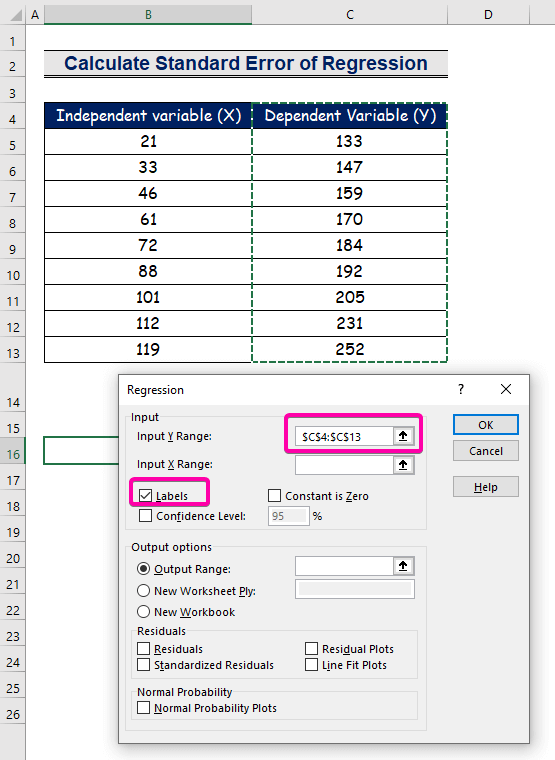
- については 入力Yレンジ は、範囲を選択します。 C4:C13 をヘッダとする。
- をクリックします。 ラベル のチェックボックスにチェックを入れます。
- 範囲を選択する B4:B13 に対して 入力X範囲 .
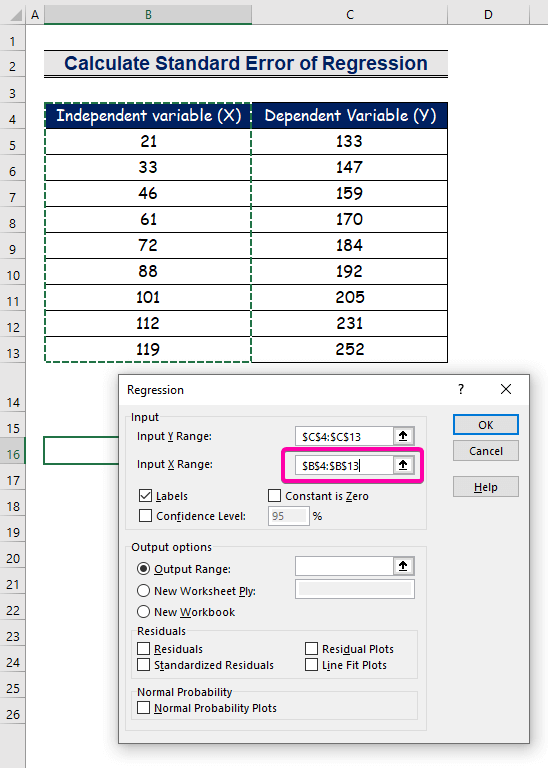
- 結果を好みの場所に表示させるには、任意のセル( B16 )に対応しています。 出力範囲 .
- 最後に よっしゃー .

続きを読む Excelで割合の標準誤差を計算する方法(簡単なステップ付き)
ステップ3:標準誤差を求める
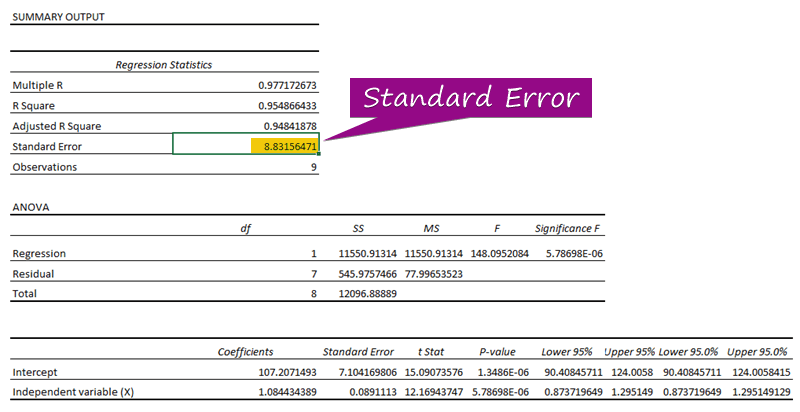
- 回帰分析から、標準誤差の値を求めることができます( 3156471 ).
続きを読む Excelで残差標準誤差を求める方法(2つの簡単な方法)
ステップ4:回帰モデル図の作図
- まず インサート タブで表示します。
- より チャート グループを選択します。 散布 チャートで確認できます。
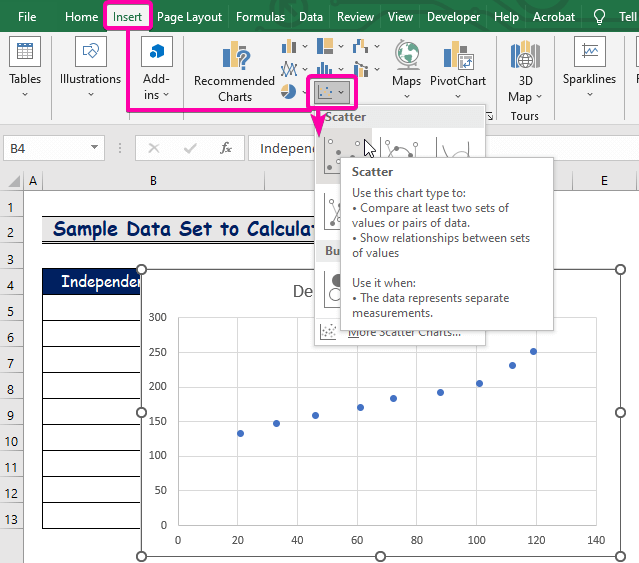
- 右クリック を1点だけ追加しました。
- オプションから、以下のものを選択します。 トレンドラインの追加 オプションを使用します。
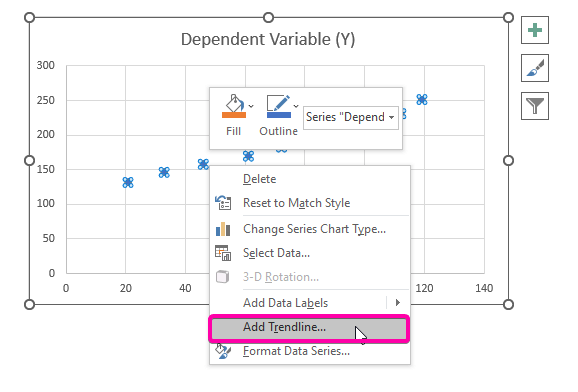
- したがって、あなたの 回帰分析 のチャートは、下図のようにプロットされます。

- を表示するには 回帰分析 式をクリックします。 数式をチャートに表示する オプションを指定します。 フォーマット トレンドライン

- その結果、式( y = 1.0844x + 107.21 )の回帰分析がチャートに表示されます。
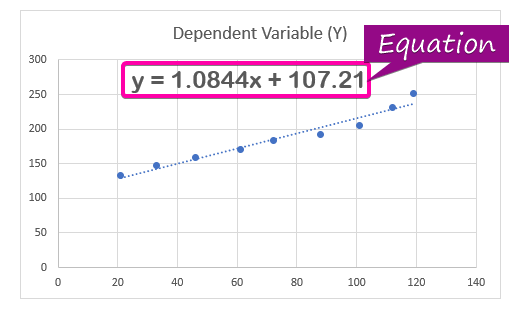
注意事項
回帰分析の式から予測値と実測値の差を計算することができます。
ステップス
- 回帰分析式を表す数式を入力する。
=1.0844*B5 + 107.21 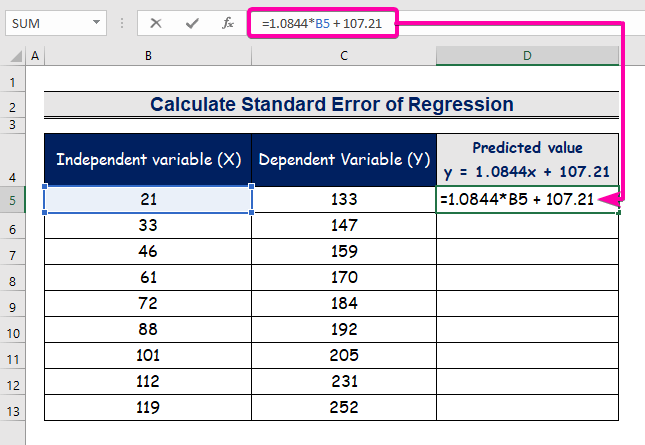
- したがって、最初の予測値を得ることになります( 129.9824 )と異なり、実際の値( 133 ).

- を使用します。 オートフィルツール をクリックすると、カラムがオートフィルされます。 D .

- 誤差を計算するには、以下の数式を入力して引き算します。
=C5-D5 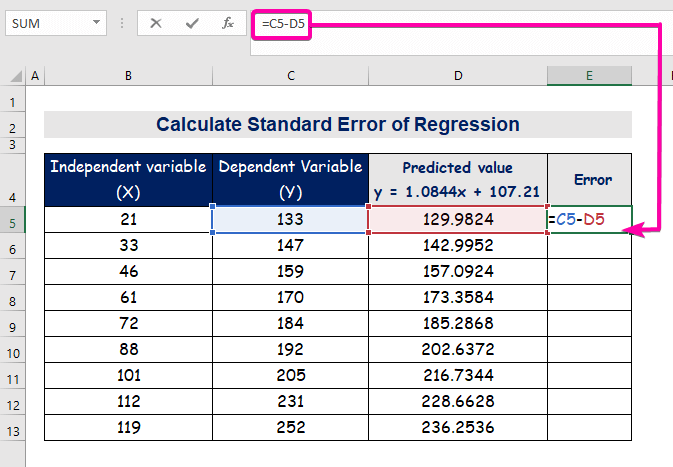
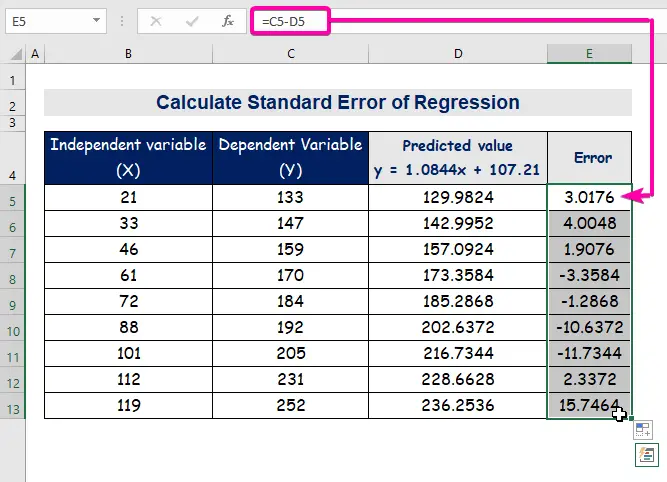
- 最後に、オートフィルカラム E を使って誤差の値を求めます。
続きを読む Excelで回帰の傾きの標準誤差を計算する方法
エクセルによる回帰分析の解釈
1.標準誤差
回帰分析式から、予測値と実測値には必ず差や誤差があることがわかる。 そのため、差の平均偏差を算出する必要がある。
A 標準エラー は、予測値と実測値の平均的な誤差を表しています。 私たちは、次のことを発見しました。 8.3156471 として 標準エラー この例では、予測値と実測値の間に差があることを示し、その差は、「予測値」よりも大きい可能性があります。 標準エラー ( 15.7464 )以下であることを確認します。 標準エラー ( 4.0048 しかし 平均誤差 であろう 8.3156471 である。 標準エラー .
その結果、モデルの目標は標準誤差を小さくすることで ある。 下げる 標準誤差が大きいほど 正確 モデルです。
2.係数
回帰係数は、未知の値の応答を評価するものである。 回帰式( y = 1.0844x + 107.21 ), 1.0844 は 係数 , x は予測独立変数である。 107.21 は定数であり y の応答値です。 x .
- A 正係数 は、係数が大きいほど応答変数が大きくなることを予言するものです。 比例 の関係にあります。
- A 負の係数 は、係数が高いほど応答値が低くなることを予言するものである。 を示す。 不釣り合い の関係にあります。
3.P-Value(ピーバリュー
回帰分析において。 p値 と係数が協力して、モデル内の相関関係が統計的に適切かどうか、またその関係がどのようなものであるかを知らせます。 帰無仮説 独立変数が従属変数と関連性がないことを検定するには p値 独立変数の変化と従属変数の変化との間に相関がなければ、関連性はない。
- あなたのサンプルデータは、十分な裏付けを与えてくれます。 誤魔化す の場合、全母集団に対する帰無仮説が成立する。 p値 は、変数に対して 少なく という概念を裏付ける証拠です。 非ゼロ相関 母集団レベルでは、独立変数の変化が従属変数の変化に連動している。
- A p値 大きめ のどちらか一方でも、有意水準より高い場合は、あなたのサンプルが ふしん を確立すること。 非ゼロ相関 が存在します。
なぜなら、彼らの p値 ( 5.787E-06 , 1.3E-06 ) は 少なく よりも 有意な値 ( 5.787E-06 ) を使用することができます。 独立変数(X) と インターセプト アール 統計的に有意 回帰出力例で見たように
4.R2乗値
線形回帰モデルの場合。 R二乗 は 網羅性測定 この比率は 分散率 は,独立要因が一緒になったときに従属変数に占める割合である。 ハンディタイプでは 0-100 パーセントのスケールで表示します。 R二乗 を定量化する。 強さ モデルと従属変数の間の接続の
があります。 R2 の値は、回帰モデルがどれだけデータに適合しているかを示す尺度です。 上 その 番号 は、その マシ が実現可能なモデルです。
結論
での回帰の標準誤差の計算方法について、この記事でチュートリアルができたかと思います。 エクセル これらの手順を習得し、データセットに適用する必要があります。 練習用ワークブックを見て、これらのスキルをテストしてください。 このようなチュートリアルを作り続けることができるのは、皆様の貴重なご支援のおかげです。
ご不明な点はお問い合わせください。 また、以下の欄にお気軽にコメントをお寄せください。
私たち Exceldemy また、このチームでは、お客様からの問い合わせに常に迅速に対応しています。
私たちと一緒に、学び続けましょう。
