
فهرست مطالب
از تحلیل رگرسیون زمانی استفاده میکنیم که دادههایی از دو متغیر از دو منبع مختلف داشته باشیم و بخواهیم بین آنها رابطه ایجاد کنیم. تحلیل رگرسیون یک مدل خطی در اختیار ما قرار می دهد که به ما امکان می دهد نتایج احتمالی را پیش بینی کنیم. به دلایل واضح، بین مقادیر پیشبینیشده و واقعی تفاوتهایی وجود خواهد داشت. در نتیجه، ما خطای استاندارد را با استفاده از مدل رگرسیون محاسبه می کنیم که میانگین خطای بین مقادیر پیش بینی شده و واقعی است. در این آموزش، نحوه محاسبه خطای استاندارد تحلیل رگرسیون را در Excel به شما نشان خواهیم داد.
دانلود کتاب تمرین تمرین
دانلود این کتاب تمرینی برای تمرین در حالی که هستید خواندن این مقاله.
Error Standard Regression.xlsx
4 مرحله ساده برای محاسبه خطای استاندارد رگرسیون در اکسل
فرض کنید شما دارید یک مجموعه داده با یک متغیر مستقل ( X ) و یک متغیر وابسته ( Y ) . همانطور که می بینید، آنها هیچ رابطه معنی داری ندارند. اما ما می خواهیم یکی بسازیم. در نتیجه، ما از تحلیل رگرسیون برای ایجاد رابطه خطی بین این دو استفاده خواهیم کرد. خطای استاندارد بین دو متغیر را با استفاده از تحلیل رگرسیون محاسبه می کنیم. ما در نیمه دوم مقاله برخی از پارامترهای مدل رگرسیون را بررسی خواهیم کرد تا به شما در تفسیر آن کمک کنیم.

مرحله 1: دستور تجزیه و تحلیل داده را اعمال کنیدیک مدل رگرسیون ایجاد کنید
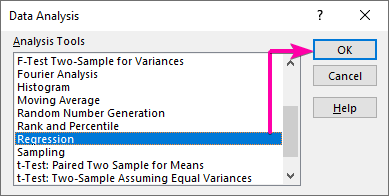
- ابتدا به برگه Data بروید و بر روی تحلیل داده ها کلیک کنید. فرمان.

- از کادر فهرست تحلیل داده ، را انتخاب کنید. رگرسیون گزینه.
- سپس، روی OK کلیک کنید.
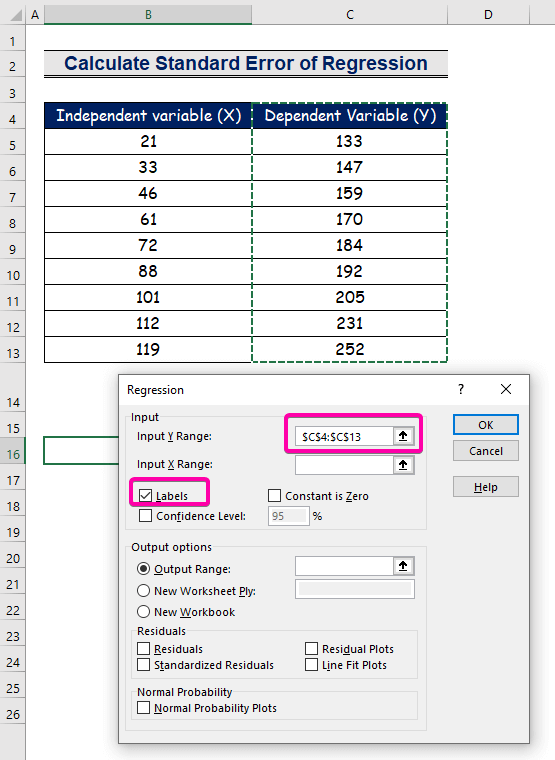
مرحله 2: محدوده ورودی و خروجی را در جعبه رگرسیون وارد کنید
- برای Input Y Range ، محدوده C4:C13 را انتخاب کنید با هدر.
- روی کادر چک برچسب ها کلیک کنید.
- محدوده B4:B13 را برای Input X Range انتخاب کنید.
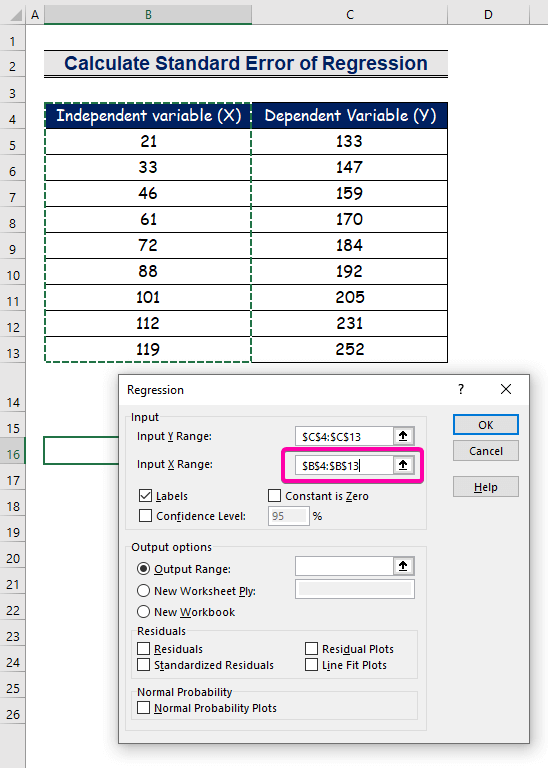
- برای دریافت نتیجه در مکان ترجیحی، هر سلول ( B16 ) را برای محدوده خروجی انتخاب کنید .
- در نهایت، OK را کلیک کنید.

بیشتر بخوانید: نحوه محاسبه خطای استاندارد نسبت در اکسل (با مراحل آسان)
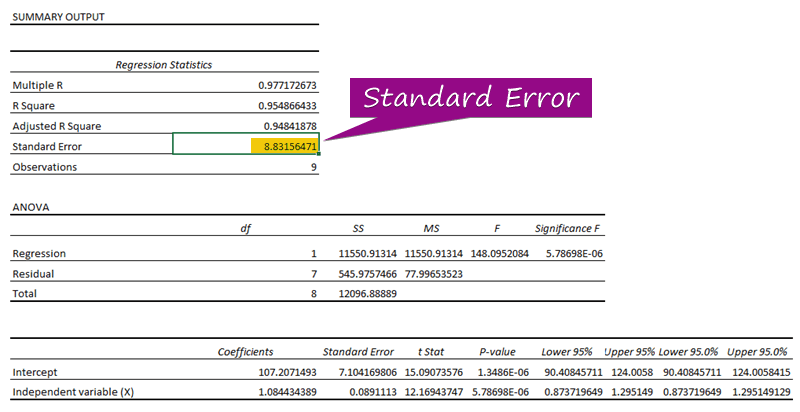
مرحله 3: خطای استاندارد را پیدا کنید
- از با تجزیه و تحلیل رگرسیون، می توانید مقدار آن را بدست آورید خطای استاندارد ( 3156471 ).
بیشتر بخوانید: چگونه برای یافتن خطای استاندارد باقیمانده در اکسل (2 روش آسان)
مرحله 4: نمودار مدل رگرسیون رسم
- ابتدا، روی Insert <کلیک کنید 9> برگه.
- از گروه Charts ، Scatter نمودار را انتخاب کنید.
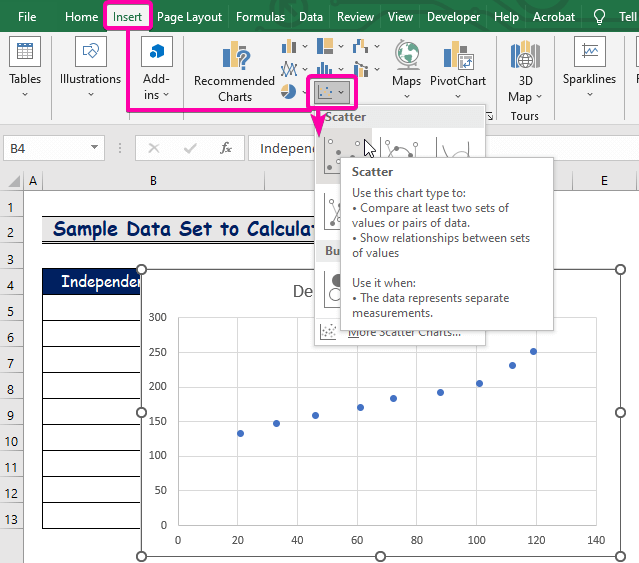
- راست کلیک کنید روی یکی ازنقاط.
- از بین گزینه ها، گزینه افزودن خط روند را انتخاب کنید.
- بنابراین، شما<1 نمودار> تجزیه و تحلیل رگرسیون مطابق تصویر زیر ترسیم می شود.

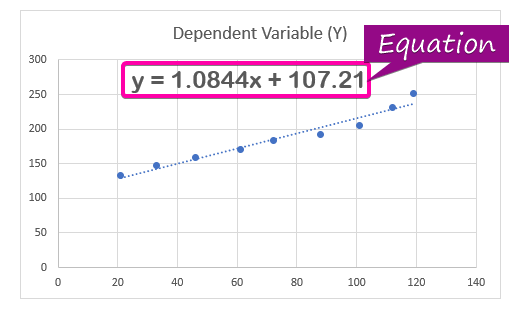
- برای نمایش معادله تحلیل رگرسیون ، روی گزینه نمایش معادله در نمودار از Format Trendline کلیک کنید. <در نتیجه، معادله ( y = 1.0844x + 107.21 ) تحلیل رگرسیون در نمودار ظاهر می شود.
نکته:
می توانید تفاوت بین مقادیر پیش بینی شده و واقعی را محاسبه کنید. مقادیر از معادله تحلیل رگرسیون.
مراحل:
- فرمول را برای نمایش معادله تحلیل رگرسیون تایپ کنید.
=1.0844*B5 + 107.21 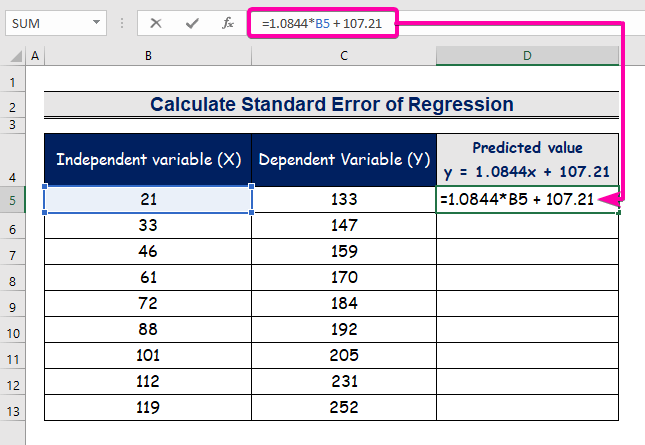
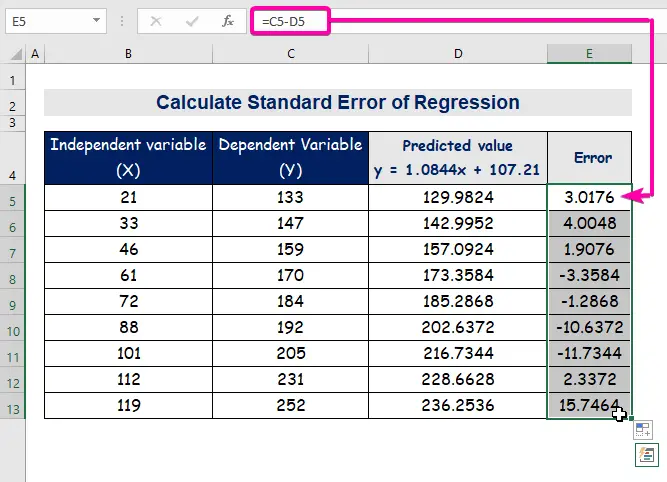
- بنابراین، اولین مقدار پیش بینی شده را دریافت خواهید کرد ( 129.9824 )، که با مقدار واقعی ( 133 ) متفاوت است.

- از <1 استفاده کنید> ابزار تکمیل خودکار برای تکمیل خودکار ستون D .

- برای محاسبه خطا، فرمول زیر را تایپ کنید تفریق کنید.
=C5-D5 
- در نهایت، ستون تکمیل خودکار E برای یافتن مقادیر خطا.
بیشتر بخوانید: نحوه محاسبه خطای استاندارد شیب رگرسیون در Excel
تفسیر تحلیل رگرسیون در اکسل
1. خطای استاندارد
از معادله تحلیل رگرسیون می توان دریافت که همیشه بین مقادیر پیش بینی شده و واقعی تفاوت یا خطا وجود دارد. در نتیجه، ما باید میانگین انحراف تفاوت ها را محاسبه کنیم.
A خطای استاندارد نماینده میانگین خطای بین مقدار پیش بینی شده و مقدار واقعی است. ما 8.3156471 را به عنوان خطای استاندارد در مدل رگرسیون مثال خود کشف کردیم. این نشان می دهد که بین مقادیر پیش بینی شده و واقعی تفاوت وجود دارد که می تواند بزرگتر از خطای استاندارد ( 15.7464 ) یا کمتر از باشد. خطای استاندارد ( 4.0048 ). با این حال، خطای متوسط ما خواهد بود 8.3156471 ، که خطای استاندارد است.
<0 در نتیجه، هدف مدل کاهش خطای استاندارد است. هر چهخطای استاندارد کمتر باشد، دقیقمدل بیشتر است.2. ضرایب
ضریب رگرسیون ارزیابی می کند پاسخ های مقادیر ناشناخته در معادله رگرسیون ( y = 1.0844x + 107.21 )، 1.0844 ضریب است. ، x متغير مستقل پيش بيني كننده، 107.21 ثابت، و y <9 است> مقدار پاسخ برای x است.
- A ضریب مثبت پیشبینی میکند که هر چه ضریب بیشتر باشد، پاسخ بالاتر استمتغیر. این یک رابطه نسبی را نشان می دهد.
- A ضریب منفی پیش بینی می کند که هر چه ضریب بیشتر باشد، مقادیر پاسخ کمتر است. نشان دهنده یک رابطه نامتناسب است.
3. P-Values
در تحلیل رگرسیون، p- مقادیر و ضرایب با هم همکاری می کنند تا به شما اطلاع دهند که آیا همبستگی ها در مدل شما از نظر آماری مرتبط هستند و آن روابط چگونه است. فرضیه صفر مبنی بر اینکه متغیر مستقل هیچ پیوندی با متغیر وابسته ندارد با استفاده از p-value برای هر متغیر مستقل آزمایش می شود. اگر همبستگی وجود نداشته باشد، هیچ ارتباطی بین تغییرات متغیر مستقل و تغییرات در متغیر وابسته وجود ندارد.
- دادههای نمونه شما پشتیبانی کافی برای جعل فرضیه صفر برای جمعیت کامل اگر p-value برای یک متغیر کمتر از آستانه اهمیت شما باشد. شواهد شما از مفهوم همبستگی غیر صفر پشتیبانی می کند. در سطح جامعه، تغییرات در متغیر مستقل با تغییرات متغیر وابسته مرتبط است. ، نشان می دهد که نمونه شما دارای اثبات کافی برای اثبات وجود یک همبستگی غیر صفر است.
زیرا مقادیر p آنها ( 5.787E-06 ، 1.3E-06 ) کمتر هستند از مقدار قابل توجه ( 5.787E-06 )، متغیر مستقل (X) و Intercept از نظر آماری معنی دار هستند، همانطور که در مثال خروجی رگرسیون مشاهده می شود.
4. مقادیر R-Squared
برای مدل های رگرسیون خطی، R-squared یک اندازه گیری کامل است. این نسبت درصد واریانس را در متغیر وابسته نشان میدهد که فاکتورهای مستقل وقتی با هم در نظر گرفته میشوند. در مقیاس دستی 0-100 درصد، R-squared قدرت ارتباط بین مدل شما و متغیر وابسته را کمیت می کند.
هر چه عددبیشتر باشد، بهترمدل امکان پذیر است.نتیجه گیری
امیدوارم این مقاله به شما پاسخ داده باشد. آموزش نحوه محاسبه خطای استاندارد رگرسیون در اکسل . همه این رویهها باید یاد بگیرند و در مجموعه داده شما اعمال شوند. به کتاب کار تمرینی نگاهی بیندازید و این مهارت ها را امتحان کنید. ما به دلیل حمایت ارزشمند شما انگیزه داریم که به ساختن چنین آموزش هایی ادامه دهیم.
لطفاً در صورت داشتن هرگونه سوال با ما تماس بگیرید. همچنین، در بخش زیر نظر خود را آزاد بگذارید.
ما، تیم Exceldemy ، همیشه پاسخگوی سوالات شما هستیم.
با ما بمانید و به یادگیری ادامه دهید.
