
Tartalomjegyzék
Használjuk regressziós elemzés amikor két különböző forrásból származó két változó adatai állnak rendelkezésünkre, és összefüggést szeretnénk létrehozni közöttük. Regressziós elemzés egy lineáris modellt ad nekünk, amely lehetővé teszi számunkra, hogy megjósoljuk a lehetséges eredményeket. A megjósolt és a tényleges értékek között nyilvánvaló okokból lesz némi különbség. Ennek eredményeként, mi kiszámítani a standard hibát a regressziós modell segítségével, ami az előre jelzett és a tényleges értékek közötti átlagos hiba. Ebben a bemutatóban azt mutatjuk be, hogyan lehet kiszámítani a regresszióelemzés standard hibáját a Excel .
Gyakorlati munkafüzet letöltése
Töltse le ezt a gyakorlati munkafüzetet, hogy gyakorolhasson, miközben ezt a cikket olvassa.
Regressziós standard hiba.xlsx4 egyszerű lépés a regresszió standard hibájának kiszámításához az Excelben
Tegyük fel, hogy van egy adathalmazunk egy független változó ( X ) és egy függő változó ( Y ) Amint láthatod, nincs jelentős kapcsolatuk. De mi szeretnénk létrehozni egyet. Ennek eredményeképpen a Regressziós elemzés hogy lineáris kapcsolatot hozzunk létre a kettő között. A regresszióelemzés segítségével kiszámítjuk a két változó közötti standard hibát. A cikk második felében a regressziós modell néhány paraméterét tekintjük át, hogy segítsünk az értelmezésben.

1. lépés: Adatelemzési parancs alkalmazása a regressziós modell létrehozásához
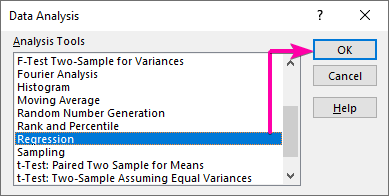
- Először is, menjen a Adatok fülre, és kattintson a Adatelemzés parancs.

- A Adatelemzés listaboxban válassza ki a Regresszió opció.
- Ezután kattintson a OK .
2. lépés: Bemeneti és kimeneti tartomány beillesztése a regressziós mezőbe
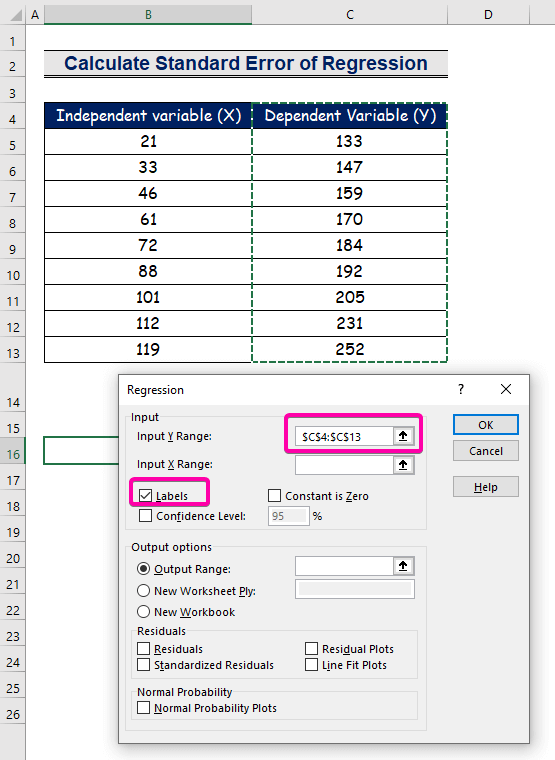
- A Y bemeneti tartomány , válassza ki a tartományt C4:C13 a fejléccel.
- Kattintson a Címkék jelölőnégyzet.
- Válassza ki a tartományt B4:B13 a X bemeneti tartomány .
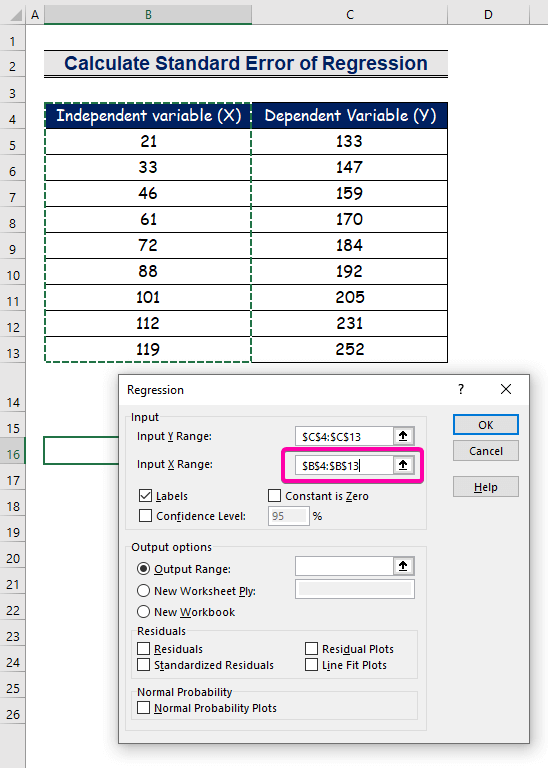
- Ha az eredményt a kívánt helyen szeretné megkapni, jelölje ki bármelyik cellát ( B16 ) a Kimeneti tartomány .
- Végül kattintson a OK .

Bővebben: Hogyan számítsuk ki az arány standard hibáját az Excelben (egyszerű lépésekkel)
3. lépés: Standard hiba megállapítása
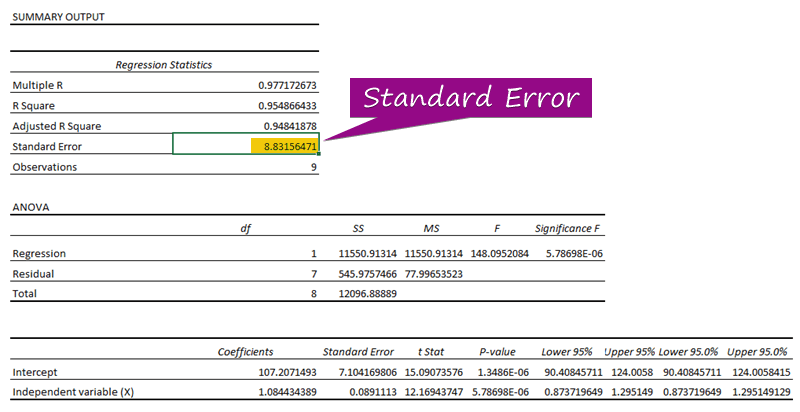
- A regresszióelemzésből megkaphatjuk a standard hiba értékét ( 3156471 ).
Bővebben: Hogyan lehet megtalálni a maradék standard hibát az Excelben (2 egyszerű módszer)
4. lépés: A regressziós modell ábrázolása
- Először kattintson a Beillesztés tab.
- A Diagramok csoport, válassza ki a Scatter táblázat.
- Kattintson a jobb gombbal a címre. az egyik pont felett.
- A lehetőségek közül válassza ki a Trendvonal hozzáadása opció.
- Ezért az Ön regressziós elemzés diagram az alábbi képen látható ábrát fogja ábrázolni.

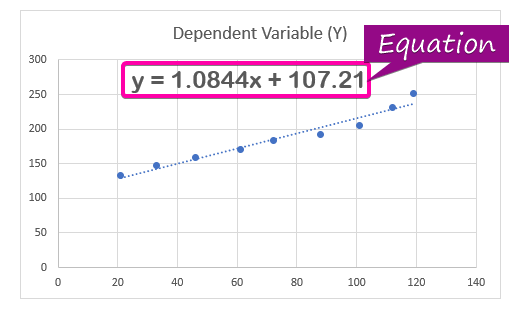
- A regressziós elemzés egyenletet, kattintson a Egyenlet megjelenítése a diagramon opciót a Formátum Trendvonal.

- Ennek eredményeképpen az egyenlet ( y = 1,0844x + 107,21 ) a regresszióelemzés eredménye megjelenik a grafikonon.
Megjegyzések:
A regresszióanalízis egyenletéből kiszámíthatja az előre jelzett értékek és a tényleges értékek közötti különbséget.
Lépések:
- Írja be a regresszióelemzési egyenletet reprezentáló képletet.
=1.0844*B5 + 107.21 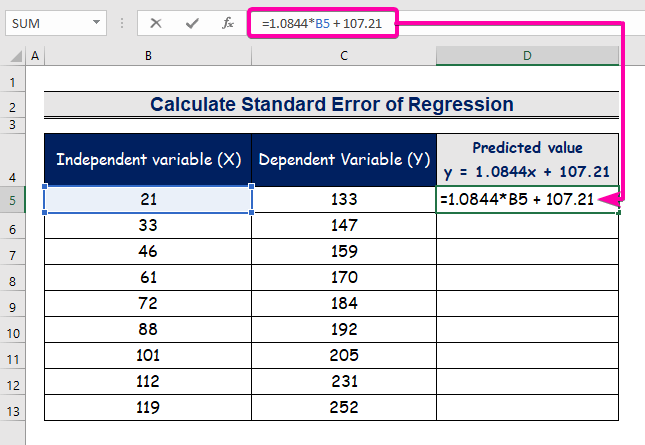
- Ezért az első előre jelzett értéket ( 129.9824 ), amely eltér a tényleges értéktől ( 133 ).

- Használja a AutoFill eszköz az oszlop automatikus kitöltéséhez D .

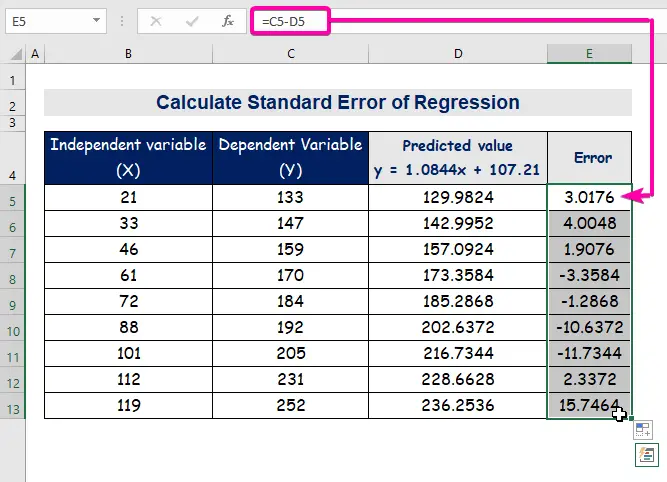
- A hiba kiszámításához írja be a következő képletet a kivonáshoz.
=C5-D5 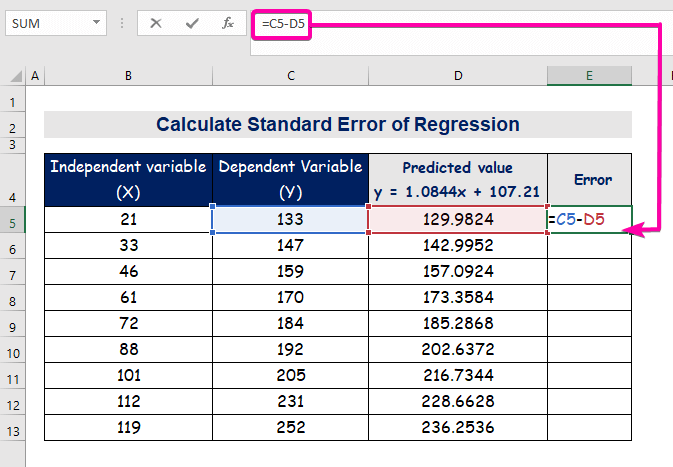
- Végül, automatikus kitöltés oszlop E a hibaértékek megtalálására.
Bővebben: A regressziós meredekség standard hibájának kiszámítása Excelben
A regresszióelemzés értelmezése Excelben
1. Standard hiba
A regresszióelemzés egyenletéből láthatjuk, hogy az előre jelzett és a tényleges értékek között mindig van különbség vagy hiba. Ennek eredményeként ki kell számolnunk a különbségek átlagos eltérését.
A standard hiba a megjósolt érték és a tényleges érték közötti átlagos hibát jelenti. Megállapítottuk, hogy 8.3156471 mint a standard hiba Ez azt jelzi, hogy az előre jelzett és a tényleges értékek között különbség van, ami nagyobb lehet, mint a standard hiba ( 15.7464 ) vagy kevesebb, mint a standard hiba ( 4.0048 ). Azonban a mi átlagos hiba lesz 8.3156471 , ami a standard hiba .
Ennek eredményeképpen a modell célja a standard hiba csökkentése. alsó a standard hiba, annál több pontos a modell.
2. Együtthatók
A regressziós együttható az ismeretlen értékek válaszait értékeli. A regressziós egyenletben ( y = 1,0844x + 107,21 ), 1.0844 a együttható , x az előrejelző független változó, 107.21 a konstans, és y a válaszérték a x .
- A pozitív együttható azt jósolja, hogy minél magasabb az együttható, annál magasabb a válaszváltozó. Ez azt jelzi, hogy a arányos kapcsolat.
- A negatív együttható azt jósolja, hogy minél magasabb az együttható, annál alacsonyabbak a válaszértékek. Ez azt jelzi, hogy a aránytalan kapcsolat.
3. P-értékek
A regressziós elemzésben, p-értékek és az együtthatók együttműködve tájékoztatják Önt arról, hogy a modellben lévő összefüggések statisztikailag relevánsak-e, és milyenek ezek az összefüggések. A nullhipotézis hogy a független változónak nincs kapcsolata a függő változóval, a következő módszerrel vizsgálják p-érték A független változóban bekövetkező változások és a függő változó változásai között nincs kapcsolat, ha nincs korreláció.
- A mintaadatok elegendő támpontot nyújtanak ahhoz, hogy meghamisítani a nullhipotézis a teljes populációra, ha a p-érték egy változó esetében kevesebb mint az Ön szignifikancia küszöbértéke. Az Ön bizonyítékai alátámasztják a nem nulla korreláció A populáció szintjén a független változó változásai a függő változó változásaihoz kapcsolódnak.
- A p-érték nagyobb mint a szignifikanciaszint, bármelyik oldalon, azt sugallja, hogy a mintája elégtelen bizonyíték annak megállapítása, hogy egy nem nulla korreláció létezik.
Mert az ő p-értékek ( 5.787E-06 , 1.3E-06 ) vannak kevesebb mint a jelentős érték ( 5.787E-06 ), a Független változó (X) és Intercept a statisztikailag jelentős , amint az a regressziós kimeneti példában látható.
4. R-négyzet értékek
Lineáris regressziós modellek esetén, R-négyzet egy teljességmérés Ez az arány mutatja a variancia százalékos aránya a függő változóban, amelyet a független tényezők együttesen okoznak. Egy kézzelfogható 0-100 százalékos skála, R-négyzet számszerűsíti a erő a modell és a függő változó közötti kapcsolatról.
A R2 érték azt mutatja meg, hogy a regressziós modell mennyire illeszkedik az adatokhoz. A magasabb a szám , a jobb megvalósítható a modell.
Következtetés
Remélem, hogy ez a cikk adott egy útmutatót arról, hogyan kell kiszámítani a regresszió standard hibáját a Excel Mindezeket az eljárásokat meg kell tanulni és alkalmazni kell az adatállományra. Nézze meg a gyakorló munkafüzetet, és tegye próbára ezeket a készségeket. Az Önök értékes támogatása miatt vagyunk motiválva, hogy továbbra is ilyen oktatóanyagokat készítsünk.
Kérjük, lépjen kapcsolatba velünk, ha bármilyen kérdése van. Továbbá, bátran hagyjon megjegyzéseket az alábbi részben.
Mi, a Exceldemy Csapat, mindig reagálnak az Ön kérdéseire.
Maradjon velünk és tanuljon tovább.
