
目次
デフォルトでは、Microsoft Excelは、複数のデバイスを扱うことはできません。 1048576列 を使えば、それ以上のデータを解析することができます。 データモデル の機能をご紹介します。 6 早足で 手掛ける 余り 1048576列 をExcelで表示します。
練習用ワークブックをダウンロードする
1Mを超える行の処理.xlsx
Excelで1048576行を超える行を処理する手順
を超える処理について、順を追って説明します。 1048576 漕ぎ手 をExcelで表示します。
ステップ1:ソースデータセットの設定
最初のステップでは、ソースデータセットを準備しました。 数千のユニークな行を作成し、それを繰り返し使用してデータセットを作成しました。 次のことが可能です。 このデータセットをダウンロードする から OneDrive を搭載しています。
- まず、今回の記事の元となるデータセットには、以下の3つのカラムがある。 名称 ", " 売上高 " と、" ゾーン ".
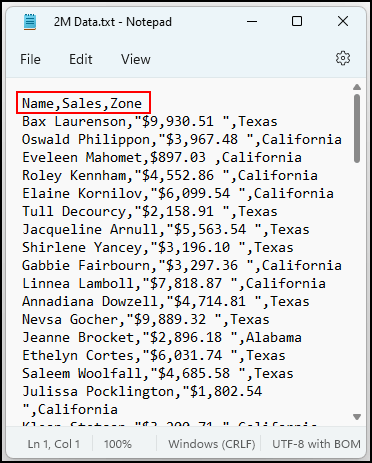
- 次に、次のようなものがあることがわかります。 2,00,001 見出し行を含むデータセットの行(または列)を指定します。

ステップ2:ソースデータセットのインポート
Excelでは、さまざまな方法でデータをインポートすることができます。 データの取得と変換 サブタブ
- まず最初に、から。 データ タブ → 選択 テキスト/CSVから .
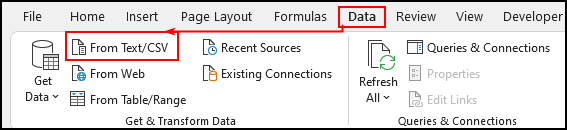
- で、その インポートデータ のウィンドウが表示されます。
- 次に、ダウンロードしたソースデータセットを OneDrive .
- その後、 を押してください。 輸入 .

ステップ3:データモデルへの追加
このステップでは、インポートしたデータセットを データモデル .
- 前のステップの最後にImportを押した後、別の ダイアログボックス が表示されます。
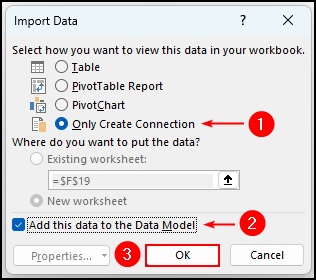
- 次に、" "を押します。 ロード・トゥ... "

- 次に、""を選択します。 コネクションの作成のみ ".
- 次に、「」を選択します。 このデータをデータモデルに追加する ".
- その後 よっしゃー .
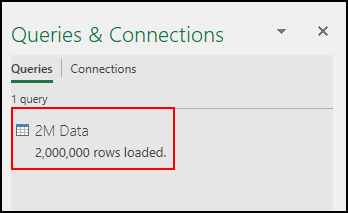
- ステータスには、" 2,000,000行のロード ".
ステップ4:データモデルからPivotTableを挿入する
では、その情報を活用して データモデル を追加しました。 ピボットテーブル .
- そもそも、から インサート タブ → ピボットテーブル → より データモデル .

- そのため ピボットテーブル から データモデル ダイアログボックス がポップアップ表示されます。
- そして、「」を選択します。 既存のワークシート 「を選択し、出力を指定します。 この例では、セル B4 .
- 最後に よっしゃー .

- そのため、白紙のピボット・テーブルが表示されます。
- 次に、" ゾーン " のフィールドに表示されます。 列 " 領域と " 売上高 " のフィールドに表示されます。 価値観 " の領域です。
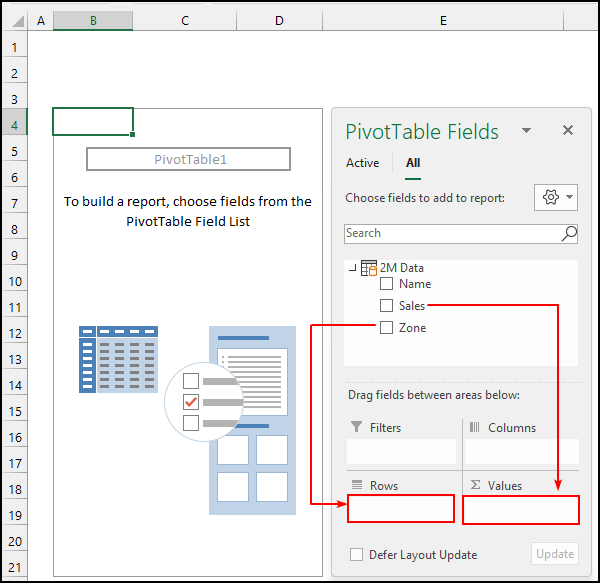
- 次に、ピボット・テーブル内の任意の場所を選択し、その場所で デザイン タブ → レポートレイアウト →選択 アウトラインフォームで表示する .今回の変更点 " 行ラベル " から " ゾーン ".

- この手順が正しく実行されていれば、これがピボット・テーブルの出力になります。

ステップ5:スライサーを採用する
があります。 エクセルスライサー は、ピボット・テーブルをフィルタリングするための優れたツールであり、これを使用して、より多くの 1.05 百万行のデータ
- まず、ピボット・テーブル内の任意の場所を選択します。
- では、その中から ピボットテーブルの分析 タブ → 選択 インサートスライサー .

- で、その スライサーの挿入ダイアログボックス がポップアップ表示されます。
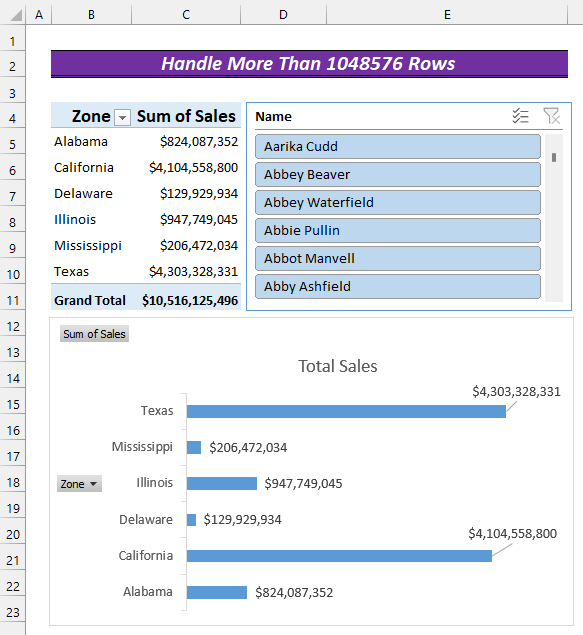
- 次に、""を選択します。 名称 "を押してください。 よっしゃー .

- したがって、" 名称 " スライサー が表示されます。

ステップ6:チャートの挿入
最後のステップでは バーチャート を使用してデータを可視化します。
- まず、ピボット・テーブル内の任意の場所を選択します。
- 2つ目は、から ピボットテーブルの分析 タブ → 選択 ピボットチャート .

- その後 チャートの挿入 のボックスがポップアップ表示されます。
- その後、" "を選択します。 バー "を押してください。 よっしゃー .

- そうすると、グラフが表示されます。

- 最後に、タイトルを追加し、グラフを少し修正すると、このようになります。
覚えておきたいこと
- エクセル データモデル の機能から利用できます。 エクセル 2013 この機能により、データはコンピュータのメモリに保存されます。 そのため、遅いコンピュータを使用している場合、大量の行を解析するのに多くの時間がかかります。
