
目次
分散分析 または 分散分析 は、複数の統計モデルを組み合わせて、グループ内またはグループ間の平均の差を求めるものです。 ユーザーは、複数のコンポーネントの ANOVA分析 を使い、Excelで結果を解釈します。
があるとします。 ANOVA分析 の結果は、以下のスクリーンショットのようになります。

今回は、複数種類の解釈 分散分析 の結果は、Excelを使用して得られたものです。
Excelワークブックをダウンロードする
ANOVA結果の解釈.xlsxExcelでANOVAの結果を解釈する3つの簡単な方法
Excelでは、次の3つのタイプがあります。 ANOVA分析 があります。
(i) ANOVA: 単因子。 単一要因分散分析 分析の結果は、データ・モデルの平均値に有意な差があるかどうかを見つけることである。 したがって、解決すべき2つの顕著な仮説を担っている。
(a) 帰無仮説(H) 0 ): この因子は、グループ内またはグループ間の平均に差を生じない。 平均を記号で表すと、次のようになる。 µ であれば、その Null Hypothesis(帰結仮説 を締結しています。 µ 1 = µ 2 = µ 3 .... = µ N .
(b) 代替仮説(H) 1 ): であり、平均値に有意な差を生じさせる要因である。 代替仮説 の結果 µ 1 ≠ µ 2 .
(ii) 複製を伴うANOVA二要因。 データに因子または独立変数の各セットについて複数の反復が含まれている場合、ユーザーは複製を使用して2つの因子を適用します。 ANOVA分析 .シングルファクターと同様 分散分析 の2つのバリアントについて、再現分析テストによる2因子 Null Hypothesis(帰結仮説 (H 0 ) .
(a) 各グループは、最初の独立変数の平均値に差はない .
(b) 各グループは、第二の独立変数の平均値に差はない .
インタラクションの場合、ユーザーは別の Null Hypothesis(帰結仮説 状態表示
(c) ある独立変数が他の独立変数の影響に影響を与えない、あるいはその逆である。 .
(iii) 複製なしのANOVA二要因。 複数のタスクが異なるグループによって行われる場合、ユーザーは2つの要素を複製せずに実行し ANOVA分析 その結果、2つの Null Hypotheses(帰結仮説 .
について 列 :
Null Hypothesis (H 0 ): 各職種の平均値に有意な差はない .
について コラム :
Null Hypothesis (H 0 ): グループタイプ別の平均値に有意な差はない .
方法1:Excelで単一因子分析のためのANOVA結果を解釈する
実行中 ANOVA: 単因子 分析 から データ解析ツールパック 3つ以上の独立したサンプル(またはグループ)の平均値の間に統計的に有意な差があるかどうかを調べることができます。 次の画像は、テストを実行するために利用可能なデータを示しています。
を実行したとします。 ANOVA: 1因子データ解析 を経由して、エクセルで データ > データ分析 は 分析 セクション)> Anova: 単因子 (以下 解析ツール オプション)。 テスト結果は、下の画像に描かれています。

結果の解釈
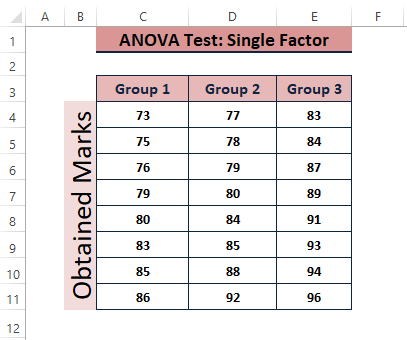
パラメータ:Anova分析 が決まります。 Null Hypothesis(帰結仮説 とは異なる結果値です。 アノーバ分析 の結果はピンポイントになります。 Null解析 の状態になります。

平均と分散。 より 概要 を見ると、平均値が最も高いグループ(=。 89.625 )であり、グループ3では最も大きな分散は 28.125 をグループ 2 で取得した。

検定統計量(F)と臨界値(F)の比較 クリティカル ): Anova結果ショーケース 統計データ ( F= 8.53 )> 臨界統計量 ( F クリティカル =3.47 を拒否します。 Null Hypothesis(帰結仮説 .

P値 vs. 有意水準(a)。 今回もまた 分散分析 の結果は、その P値 ( 0.0019 ) <があります。 有意水準 ( a = 0.05 )であるから、平均が異なると言って、拒否することができる。 Null Hypothesis(帰結仮説 .

続きを読む ExcelでAnovaの結果をグラフ化する方法(3つの適切な例)
方法2: Excelで再現分析による2要因のANOVA結果を解読する
あるいは。 ANOVA: 複製を含む2因子 2つ以上のグループの平均値の差を評価します。 この分析を行うために、以下のデータを割り当ててみましょう。

を実行した後 Anova: 複製分析による2因子法 は、次のような結果になることがあります。

結果の解釈
パラメータ P値 を拒否または受け入れるためのパラメータとしてのみ作用する。 Null Hypothesis(帰結仮説 .

変数1 有意な状態。 変数1 (すなわち サンプル ) があります。 P値 (すなわち 0.730 )よりも大きい。 有意水準 (すなわち 0.05 )。 このように 変数1 を拒否することはできません。 Null Hypothesis(帰結仮説 .
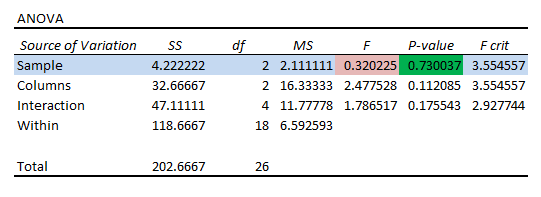 変数2 有意な状態。 に似ています。 変数1 , 変数2 (すなわち コラム ) があります。 P値 (すなわち 0.112 ) よりも大きい。 0.05 この場合 変数2 も該当します。 Null Hypothesis(帰結仮説 従って、平均値は同じである。
変数2 有意な状態。 に似ています。 変数1 , 変数2 (すなわち コラム ) があります。 P値 (すなわち 0.112 ) よりも大きい。 0.05 この場合 変数2 も該当します。 Null Hypothesis(帰結仮説 従って、平均値は同じである。

インタラクションの状態。 変数 1 と 2 を持っているので、交流はありません。 P値 (すなわち 0.175 )よりも多い。 有意水準 (すなわち 0.05 ).

全体として、どの変数も互いに有意な影響を及ぼしていない。
平均的な相互作用。 の手段のうち グループA , B そして C , グループA の平均値が最も高い。 しかし、この平均値では、この比較が有意であるかどうかはわからない。 このような場合に、平均値を見ることができるのは、次のようなものである。 グループ1 , 2 そして 3 .

の平均値。 グループ1 , 2 そして 3 の方が大きい。 グループ3 しかし、どの変数も互いに大きな影響を及ぼしていないため。

また、エントリーはランダムで範囲内の繰り返しのようなので、有意な交互作用はない。
続きを読む Excelで二元配置分散分析の結果を解釈する方法
方法3: 複製分析なしの2要因のANOVA結果をExcelで変換する
両方の要因や変数が従属変数に影響を与える場合、ユーザーは通常、以下を実行します。 ANOVA: 複製分析なしの二要因 後者のデータを使って、このような分析を行うとしよう。
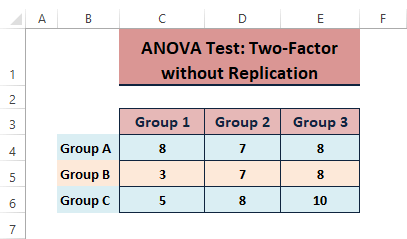
再現性のない2因子分析の結果は、以下のようになります。
結果の解釈
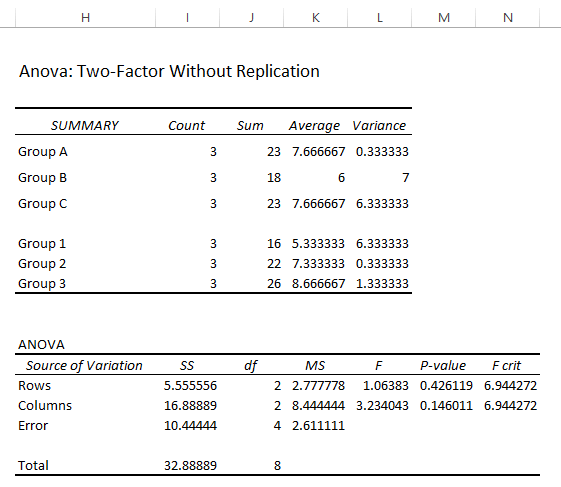
パラメータ:再現性のない2要因分散分析 は、単一因子 分散分析 .
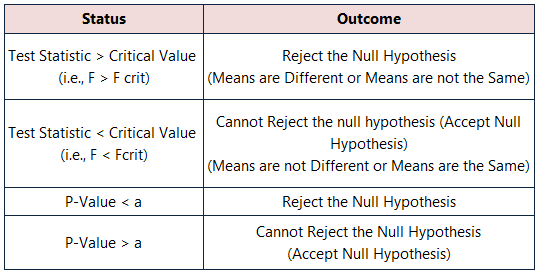
検定統計量(F)と臨界値(F)の比較 クリティカル ): いずれの変数についても 統計値 値( F= 1.064, 3.234 ) < 臨界統計量 ( F クリティカル =6.944, 6.944 を拒否することができません。 Null Hypothesis(帰結仮説 .つまり、手段は等価である。

P値 vs 有意水準(a)。 さて、その中で 分散分析 の結果は、その P値 ( 0.426, 0.146 )>です。 有意水準 ( a = 0.05 この場合、平均値が同じであることを認めて Null Hypothesis(帰結仮説 .

続きを読む Excelで二元配置分散分析を行う方法 (簡単なステップ)
結論
今回は、その種類を説明します。 ANOVA分析 と解釈する方法を示す。 分散分析 この記事を読んで、結果を理解し、それぞれの製品を選択するための一助となれば幸いです。 ANOVA分析 ご質問やご意見がありましたら、お気軽にお寄せください。
ぜひ一度、私たちの素晴らしい作品をご覧ください。 ウェブサイト と、Excelに関する最近の記事をご覧ください。 Happy Excelling.
