
Inhoudsopgave
ANOVA of Analyse van de variantie is een samenvoeging van meerdere statistische modellen om de verschillen in gemiddelden binnen of tussen groepen te vinden. Gebruikers kunnen meerdere componenten van een ANOVA-analyse om de resultaten in Excel te interpreteren.
Laten we zeggen dat we de ANOVA-analyse resultaten zoals weergegeven in de onderstaande schermafbeelding.

In dit artikel interpreteren wij meerdere soorten ANOVA resultaten verkregen met behulp van Excel.
Excel-werkboek downloaden
ANOVA-resultaten interpreteren.xlsx3 Eenvoudige methoden om ANOVA-resultaten in Excel te interpreteren
In Excel zijn er 3 soorten ANOVA-analyse beschikbaar. Ze zijn
(i) ANOVA: Enkele factor: Enkele factor ANOVA Het resultaat van de analyse is om na te gaan of het gegevensmodel significante verschillen in de gemiddelden vertoont. Daarom zijn er twee belangrijke hypothesen om op te lossen.
(a) Nulhypothese (H 0 ): De factor veroorzaakt geen verschil in middelen binnen of tussen groepen. Als middelen worden gesymboliseerd met µ dan is de Nulhypothese concludeert: µ 1 = µ 2 = µ 3 .... = µ N .
(b) Alternatieve hypothese (H 1 ): de factor significante verschillen in de gemiddelden veroorzaakt. Dus, de Alternatieve hypothesen s resultaten in µ 1 ≠ µ 2 .
(ii) ANOVA Twee-factor met replicatie: Wanneer de gegevens meer dan één iteratie bevatten voor elke set van de factoren of onafhankelijke variabelen, passen de gebruikers twee factoren met replicatie toe ANOVA-analyse . vergelijkbaar met de enkele factor ANOVA-analyse twee factoren met replicatieanalyse testen voor twee varianten van Nulhypothese (H 0 ) .
(a) De groepen hebben geen verschil in hun gemiddelde voor de eerste onafhankelijke variabele .
(b) De groepen hebben geen verschil in hun gemiddelde voor de tweede onafhankelijke variabele .
Voor Interactie kunnen gebruikers een andere Nulhypothese stating-
(c) Een onafhankelijke variabele heeft geen invloed op het effect van de andere onafhankelijke variabele of omgekeerd. .
(iii) ANOVA Two-Factor zonder replicatie: Wanneer meer dan één taak wordt uitgevoerd door verschillende groepen, voeren gebruikers twee factoren uit zonder replicatie in ANOVA-analyse Bijgevolg zijn er twee Nulhypothesen .
Voor Rijen :
Nulhypothese (H 0 ): Geen significant verschil tussen de gemiddelden van de verschillende soorten banen .
Voor Kolommen :
Nulhypothese (H 0 ): Geen significant verschil tussen de gemiddelden van de verschillende groepstypen .
Methode 1: ANOVA-resultaten interpreteren voor analyses met één factor in Excel
Uitvoeren van ANOVA: Enkele factor Analyse van Toolpak voor gegevensanalyse helpt gebruikers te bepalen of er een statistisch significant verschil is tussen de gemiddelden van 3 of meer onafhankelijke steekproeven (of groepen). De volgende afbeelding toont de gegevens die beschikbaar zijn om de test uit te voeren.
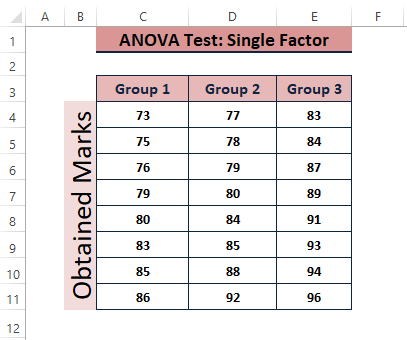
Stel dat we de ANOVA: Analyse van gegevens met één factor in Excel door Gegevens > Gegevensanalyse (in de Analyse sectie)> Anova: Enkele factor (onder de Analyse-instrumenten De resultaten van de test zijn weergegeven in de onderstaande afbeelding.

Interpretatie van de resultaten
Parameters: Anova-analyse bepaalt de Nulhypothese de toepasbaarheid in de gegevens. Verschillende resultaatwaarden van de Anova-analyse resultaat kan de Nietige analyse status.

Gemiddelde en Variantie: Van de Samenvatting kunt u zien dat de groepen het hoogste gemiddelde hebben (d.w.z., 89.625 ) voor groep 3 en de hoogste variantie is 28.125 verkregen voor groep 2.

Teststatistiek (F) versus kritische waarde (F Crit ): Anova resultaten showcase Statistiek ( F= 8.53 )> Kritische statistiek ( F Crit =3.47 ). Daarom verwerpt het gegevensmodel de Nulhypothese .

P-waarde versus significantieniveau (a): Nogmaals, van de ANOVA resultaten, de P Waarde ( 0.0019 ) <de Significantieniveau ( a = 0.05 ). U kunt dus zeggen dat de middelen verschillend zijn en de Nulhypothese .

Lees meer: Anova-resultaten grafisch weergeven in Excel (3 geschikte voorbeelden)
Methode 2: decoderen van ANOVA-resultaten voor twee factoren met replicatieanalyse in Excel
Als alternatief, ANOVA: Twee-factor met replicatie evalueert het verschil tussen de gemiddelden van meer dan twee groepen. Laten we de onderstaande gegevens gebruiken om deze analyse uit te voeren.

Na het uitvoeren van de Anova: Twee-factor met replicatie-analyse kan het resultaat er als volgt uitzien.

Interpretatie van de resultaten
Parameters: P Waarde fungeert alleen als parameter voor de verwerping of aanvaarding van Nulhypothese .

Variabele 1 Significante status: Variabele 1 (d.w.z, Voorbeeld ) heeft P Waarde (d.w.z, 0.730 ) groter dan de Significantieniveau (d.w.z, 0.05 ). Dus, Variabele 1 kan de Nulhypothese .
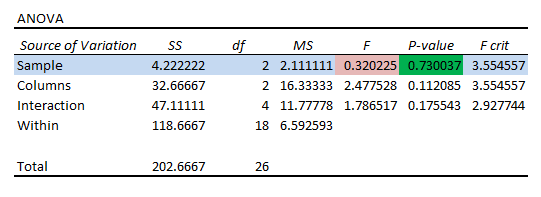 Variabele 2 Significante status: Vergelijkbaar met Variabele 1 , Variabele 2 (d.w.z, Kolommen ) heeft een P Waarde (d.w.z, 0.112 ) die groter is dan 0.05 In dit geval, Variabele 2 valt ook onder de Nulhypothese Daarom zijn de middelen hetzelfde.
Variabele 2 Significante status: Vergelijkbaar met Variabele 1 , Variabele 2 (d.w.z, Kolommen ) heeft een P Waarde (d.w.z, 0.112 ) die groter is dan 0.05 In dit geval, Variabele 2 valt ook onder de Nulhypothese Daarom zijn de middelen hetzelfde.

Interactie Status: Variabelen 1 en 2 hebben geen interactie omdat ze een P Waarde (d.w.z, 0.175 ) meer dan de Significantieniveau (d.w.z, 0.05 ).

In het algemeen heeft geen enkele variabele een significant effect op elkaar.
Gemiddelde interactie: Onder de middelen voor Groepen A , B en C , Groep A heeft het hoogste gemiddelde. Maar deze gemiddelde waarden zeggen niet of deze vergelijking significant is of niet. In dit geval kunnen we kijken naar de gemiddelde waarden voor Groepen 1 , 2 en 3 .

De gemiddelde waarden van Groepen 1 , 2 en 3 hebben grotere waarden voor Groep 3 Aangezien echter geen enkele variabele een significant effect op elkaar heeft.

Ook zijn er geen significante interactie-effecten, aangezien de inzendingen willekeurig lijken te zijn en zich binnen een bereik herhalen.
Lees meer: De resultaten van een tweezijdige ANOVA interpreteren in Excel
Methode 3: Vertaling van ANOVA-resultaten voor twee-factorige analyse zonder replicatie in Excel
Wanneer beide factoren of variabelen de afhankelijke variabelen beïnvloeden, voeren gebruikers gewoonlijk ANOVA: Twee-factor zonder replicatieanalyse Laten we zeggen dat we deze laatste gegevens gebruiken om een dergelijke analyse uit te voeren.
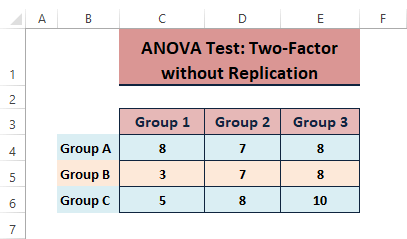
De resultaten van een analyse met twee factoren zonder replicatie zien er als volgt uit.
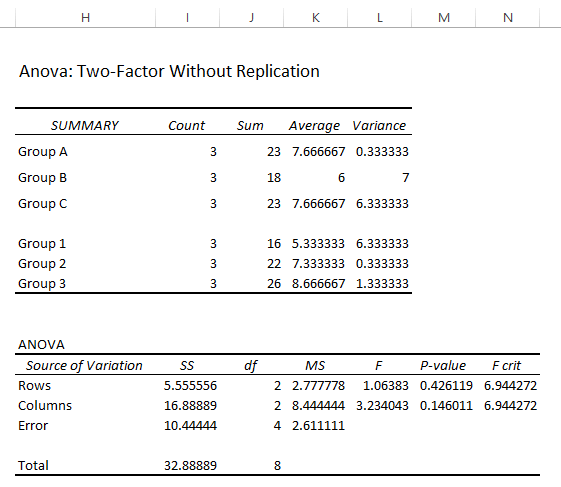
Interpretatie van de resultaten
Parameters: Twee-factor ANOVA-analyse zonder replicatie heeft soortgelijke parameters als de enkele factor ANOVA .
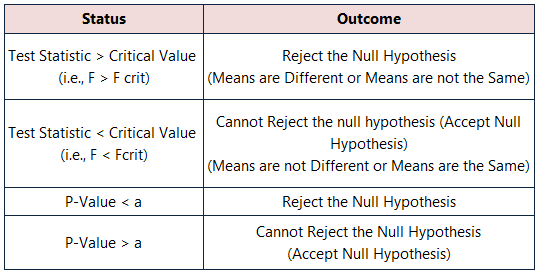
Teststatistiek (F) vs Kritische waarde (F Crit ): Voor beide variabelen is de Statistiek waarden ( F= 1.064, 3.234 ) < Kritische statistiek ( F Crit =6.944, 6.944 ). Daardoor kan het gegevensmodel de Nulhypothese Dus de middelen zijn gelijkwaardig.

P-waarde versus significantieniveau (a): Nu, in de ANOVA resultaten, de P-waarden ( 0.426, 0.146 )> de Significantieniveau ( a = 0.05 ). In dat geval kun je zeggen dat de middelen hetzelfde zijn en de Nulhypothese .

Lees meer: Hoe een tweezijdige ANOVA uitvoeren in Excel (in eenvoudige stappen)
Conclusie
In dit artikel beschrijven wij de soorten ANOVA-analyse en laten zien hoe je ANOVA We hopen dat dit artikel u helpt om de uitkomsten te begrijpen en u de overhand geeft om de respectieve ANOVA-analyses die het beste bij uw gegevens passen. Reageer als u nog vragen heeft of iets toe te voegen heeft.
Breng snel een bezoek aan onze geweldige website en bekijk onze recente artikelen over Excel. Happy Excelling.
