
Inhoudsopgave
Eenvoudige regressie analyse wordt gewoonlijk gebruikt om de relatie tussen twee variabelen te schatten, bijvoorbeeld de relatie tussen gewasopbrengsten en regenval of de relatie tussen de smaak van brood en oventemperatuur. Maar vaker moeten we de relatie tussen een afhankelijke variabele en twee of meer onafhankelijke variabelen onderzoeken. Bijvoorbeeld, een makelaar kan willen wetenof en hoe maatregelen zoals de grootte van het huis, het aantal slaapkamers en het gemiddelde inkomen van de buurt verband houden met de prijs waarvoor een huis wordt verkocht. Dit soort problemen kan worden opgelost door toepassing van meervoudige regressieanalyse. En dit artikel geeft u een overzicht van hoe u een meervoudige regressieanalyse kunt uitvoeren met Excel.
Probleem
Stel dat we 5 willekeurig gekozen verkopers nemen en de informatie verzamelen zoals in de onderstaande tabel. Heeft opleiding of motivatie invloed op de jaaromzet of niet?
| Hoogste jaar van voltooide school | Motivatie zoals gemeten door de Higgins Motivatieschaal | Jaarlijkse verkoop in dollars |
| 12 | 32 | $350,000 |
| 14 | 35 | $399,765 |
| 15 | 45 | $429,000 |
| 16 | 50 | $435,000 |
| 18 | 65 | $433,000 |
Vergelijking
In het algemeen, meervoudige regressieanalyse veronderstelt dat er een lineair verband bestaat tussen de afhankelijke variabele (y) en de onafhankelijke variabelen (x1, x2, x3 ... xn). En dit soort lineair verband kan worden beschreven met de volgende formule:
Y = constante + β1*x1 + β2*x2+...+ βn*xn
Hier zijn de verklaringen voor de constanten en coëfficiënten:
| Y | De voorspelde waarde van Y |
| Constant | Het Y-intercept |
| β1 | De verandering in Y elke 1 incrementele verandering in x1 |
| β2 | De verandering in Y elke 1 incrementele verandering in x2 |
| ... | ... |
| βn | De verandering in Y bij elke verandering van 1 increment in xn |
Constante en β1, β2... βn kunnen worden berekend op basis van beschikbare steekproefgegevens. Nadat je de waarden van constante, β1, β2... βn hebt verkregen, kun je ze gebruiken om de voorspellingen te doen.
Voor ons probleem zijn er slechts twee factoren die ons interesseren. Daarom wordt de vergelijking:
Jaaromzet = constante + β1*(Hoogst voltooide schooljaar) + β2*(Motivatie zoals gemeten door de Higgins Motivatieschaal)
Model instellen
Jaaromzet, hoogst behaalde schooljaar en Motivatie werden ingevoerd in kolom A, kolom B en kolom C, zoals weergegeven in figuur 1. Het is beter de afhankelijke variabele (Jaaromzet hier) altijd vóór de onafhankelijke variabelen te plaatsen.
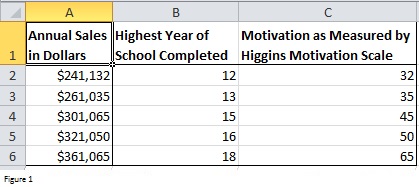
Figuur 1
Download Analyse ToolPak
Excel biedt ons de functie Gegevensanalyse die waarden van constanten en coëfficiënten kan weergeven. Maar voordat u deze functie kunt gebruiken, moet u Analysis ToolPak downloaden. Hieronder leest u hoe u dit kunt installeren.
Klik op de Bestand tab -> Opties en klik dan op Toevoegingen in Excel-opties dialoogvenster. Klik op Ga naar knop aan de onderkant van Excel-opties dialoogvenster te openen Toevoegingen dialoogvenster. In het Toevoegingen dialoogvenster, selecteer Analyse TookPak checkbox en klik dan op Ok .
Als u nu klikt op Gegevens tabblad, ziet u Gegevensanalyse verschijnt in de Analyse groep (rechterpaneel).
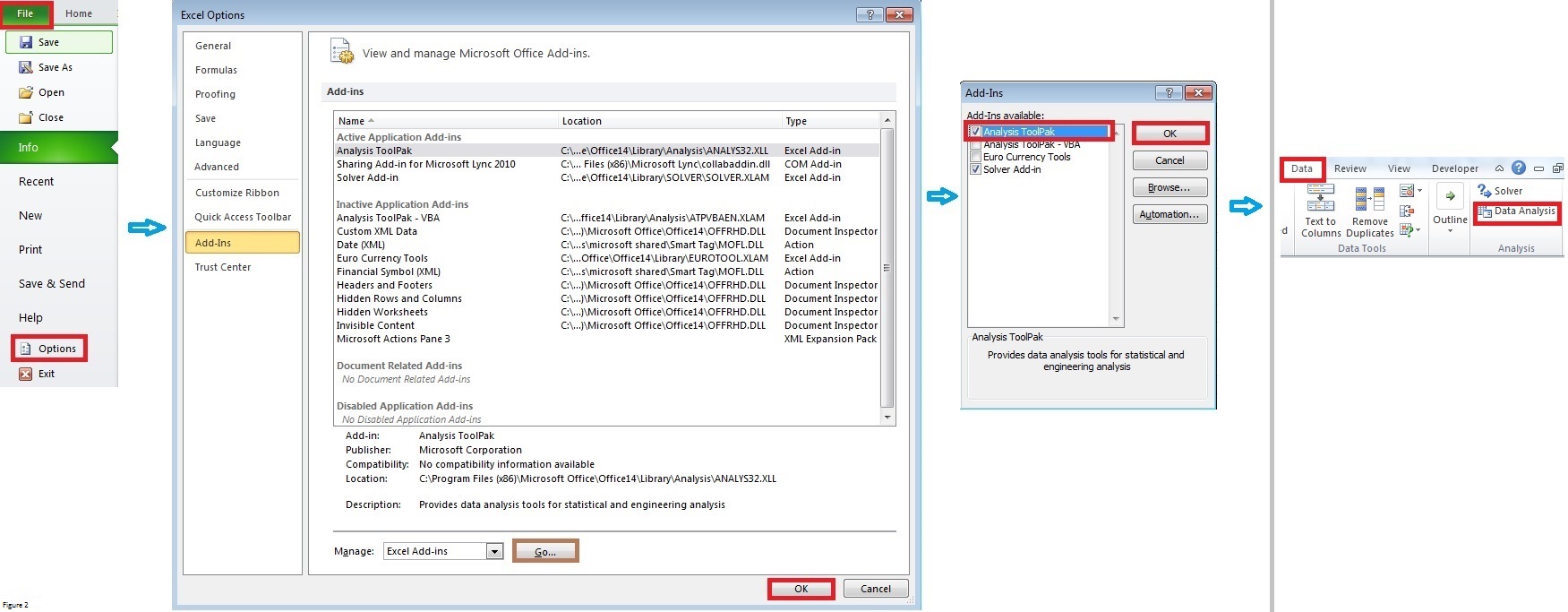
Figuur 2 [klik op de afbeelding voor een volledig beeld].
Meervoudige regressieanalyse
Klik op Gegevensanalyse in de Analyse groep op de Gegevens tabblad. Selecteer Regressie In de gevraagde Gegevensanalyse dialoogvenster. U kunt ook andere statistische analyse zoals t-test, ANOVA, enzovoort.
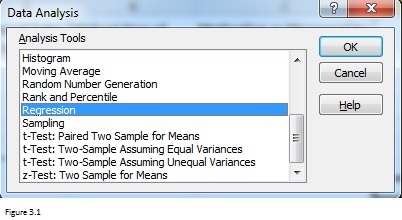
Figuur 3.1
A Regressie dialoogvenster wordt gevraagd nadat u hebt geselecteerd Regressie . vul het dialoogvenster in zoals getoond in figuur 3.2.
Input Y Range bevat de afhankelijke variabele en gegevens, terwijl Input X Range de onafhankelijke variabelen en gegevens bevat. Hier moet ik u eraan herinneren dat onafhankelijke variabelen in aangrenzende kolommen moeten staan. En het maximum aantal onafhankelijke variabelen is 15.
Aangezien het bereik A1: C1 variabele labels bevat, moet het vakje Labels worden geselecteerd. Ik raad u zelfs aan telkens labels op te nemen wanneer u het bereik Input Y en Input X vult. Deze labels zijn nuttig wanneer u samenvattende rapporten bekijkt die door Excel worden geretourneerd.
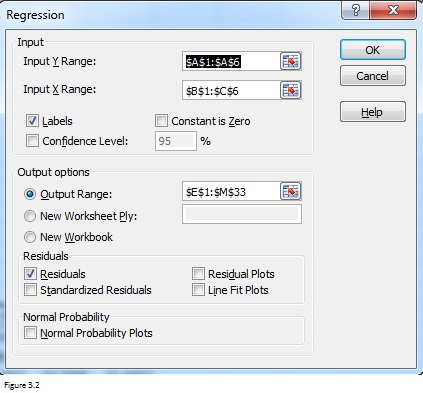
Figuur 3.2
Door het selectievakje Residuen in te schakelen, kunt u Excel in staat stellen residuen voor elke waarneming in een lijst op te nemen. Kijk naar figuur 1, er zijn in totaal 5 waarnemingen en u krijgt 5 residuen. Residu is iets dat overblijft wanneer u de voorspelde waarde aftrekt van de waargenomen waarde. Gestandaardiseerd residu is het residu gedeeld door de standaardafwijking.
U kunt ook het selectievakje Residuplot inschakelen, zodat Excel restplots kan weergeven. Het aantal restplots is gelijk aan het aantal onafhankelijke variabelen. Een restplot is een grafiek die de residuen op de Y-as en de onafhankelijke variabelen op de x-as toont. Willekeurig verspreide punten rond de x-as in een restplot impliceren dat de lineaire regressie Bijvoorbeeld, figuur 3.3 toont drie typische patronen van restplots. Alleen het patroon in het linker paneel geeft aan dat het een goede fit is voor een lineair model. De andere twee patronen suggereren een betere fit voor een niet-lineair model.
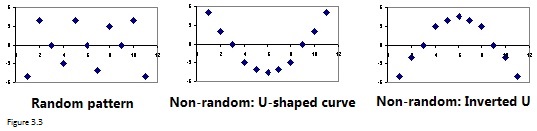
Figuur 3.3
Excel geeft een gepaste lijnplot als u het selectievakje Gepaste lijnplots selecteert. Een gepaste lijnplot kan de relatie tussen één afhankelijke variabele en één onafhankelijke variabele plotten. Met andere woorden, Excel geeft u hetzelfde aantal gepaste lijnplots met die van de onafhankelijke variabele. U krijgt bijvoorbeeld 2 gepaste lijnplots voor ons probleem.
Resultaten
Nadat u op de knop Ok hebt geklikt, geeft Excel een samenvattend rapport als hieronder. De groen en geel gemarkeerde cellen zijn het belangrijkste deel waaraan u aandacht moet besteden.
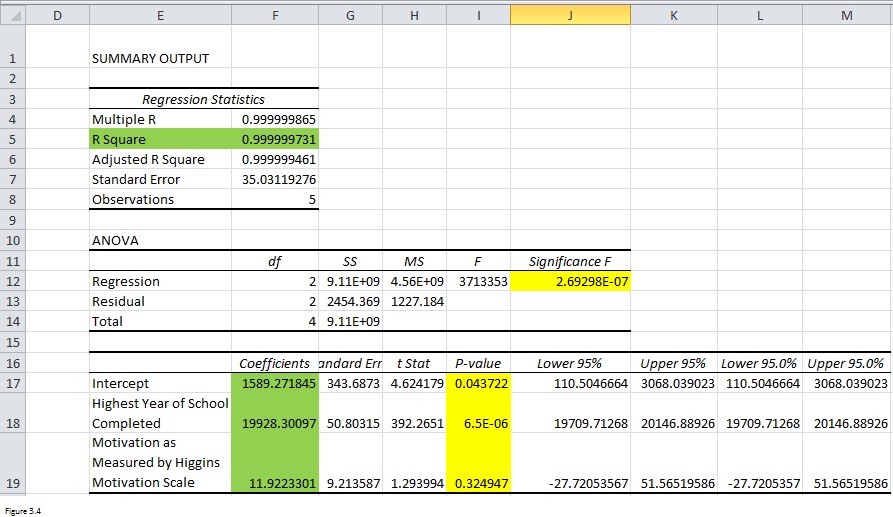
Figuur 3.4
Hoe hoger de R-kwadraat (cel F5), hoe nauwer het verband tussen de afhankelijke variabelen en de onafhankelijke variabelen. En de coëfficiënten (bereik F17: F19) in de derde tabel geven u de waarden van de constanten en coëfficiënten. De vergelijking zou moeten luiden Jaarlijkse verkoop = 1589,2 + 19928,3*(Hoogst voltooide schooljaar) + 11,9*(Motivatie zoals gemeten door de Higgins Motivatieschaal).
Maar om te zien of de resultaten betrouwbaar zijn, moet u ook de geel gemarkeerde p-waarden controleren. Alleen als de p-waarde in cel J12 kleiner is dan 0,05, is de hele regressievergelijking betrouwbaar. Maar u moet ook de p-waarden in het bereik I17: I19 controleren om te zien of constante en onafhankelijke variabelen nuttig zijn voor de voorspelling van de afhankelijke variabele. Voor ons probleem is het beter om weg te gooienmotivatie bij het beschouwen van onafhankelijke variabelen.
Lees meer: Hoe P-waarde berekenen in lineaire regressie in Excel (3 manieren)
Motivatie verwijderen uit de onafhankelijke variabelen
Na het verwijderen van Motivatie als onafhankelijke variabele, heb ik dezelfde aanpak toegepast en een eenvoudige regressieanalyse gedaan. U ziet dat alle waarden nu kleiner zijn dan 0,05. De uiteindelijke vergelijking moet zijn:
Jaaromzet = 1167,8 + 19993,3*(Hoogst voltooide schooljaar)

Figuur 3.5 [klik op de afbeelding voor een volledig beeld].
Opmerking
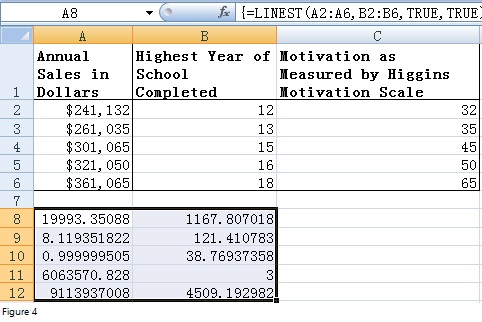
Figuur 4
Naast de invoegtoepassingen kunt u ook de LINEST-functie gebruiken om een meervoudige regressieanalyse uit te voeren. De LINEST-functie is een matrixfunctie die het resultaat in één cel of in een cellenbereik kan weergeven. Selecteer eerst het bereik A8:B12 en voer vervolgens de formule "=LINEST (A2:A6, B2:B6, TRUE, TRUE)" in de eerste cel van dit bereik (A8) in. Nadat u op CTRL + SHIFT +ENTER hebt gedrukt, zal Excel de resultaten weergeven alsDoor vergelijking met figuur 3.4 kunt u zien dat 19993,3 de coëfficiënt is voor het hoogst behaalde schooljaar, terwijl 1167,8 constant is. Hoe dan ook, ik raad u aan Add-Ins te gebruiken. Dat is veel gemakkelijker.
Lees meer...
Omgekeerde wat-als-analyse in Excel
Hoe jokertekens gebruiken in Excel?
Werkbestand downloaden
Download het werkbestand van de onderstaande link.
Multiple-Regression-Analysis.xlsx
