
सामग्री तालिका
डेटा विश्लेषणको आधुनिक युगमा, तपाइँलाई Excel मा P मान गणना गर्न आवश्यक हुन सक्छ। तपाईंले यो One Way Anova वा Two Way Anova प्रयोग गरेर गर्न सक्नुहुन्छ। यस लेखमा, हामी तपाईंलाई तीन P मान गणना गर्ने सम्भावित तरिकाहरू देखाउने छौं। एक्सेल Anova मा। यदि तपाईं यसको बारेमा उत्सुक हुनुहुन्छ भने, हाम्रो अभ्यास कार्यपुस्तिका डाउनलोड गर्नुहोस् र हामीलाई पछ्याउनुहोस्।
अभ्यास कार्यपुस्तिका डाउनलोड गर्नुहोस्
तपाईं यो लेख पढ्दै गर्दा अभ्यासको लागि यो अभ्यास कार्यपुस्तिका डाउनलोड गर्नुहोस्।
P Value.xlsx गणना गर्नुहोस्
ANOVA विश्लेषण के हो?
ANOVA ले हामीलाई डेटासेटमा कुन कारकले महत्त्वपूर्ण प्रभाव पार्छ भनेर निर्धारण गर्ने पहिलो अवसर प्रदान गर्दछ। विश्लेषण पूरा गरेपछि, एक विश्लेषकले डेटा सेटको असंगत प्रकृतिलाई महत्त्वपूर्ण रूपमा प्रभाव पार्ने विधिगत कारकहरू मा अतिरिक्त विश्लेषण गर्दछ। थप रूपमा, उसले अनुमानित रिग्रेसन विश्लेषणसँग सान्दर्भिक अतिरिक्त डाटा सिर्जना गर्न f-test मा Anova विश्लेषण निष्कर्षहरू प्रयोग गर्दछ। तिनीहरू बीचको सम्बन्ध। ANOVA एक सांख्यिकीय विधि हो जुन डेटासेट भित्र अवलोकन गरिएको भिन्नतालाई दुई खण्डमा विभाजन गरेर विश्लेषण गर्न प्रयोग गरिन्छ:
-
-
-
-
-
-
-
-
-
- >व्यवस्थित कारक र
- यादृच्छिककारकहरू 11>
-
-
-
Anova को लागि गणितीय सूत्र हो:
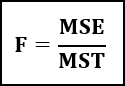
यहाँ,
- F = Anova गुणांक,
- MST = उपचारका कारण वर्गहरूको औसत योगफल,
- MSE = त्रुटिका कारण वर्गहरूको औसत योगफल।
P मान के हो?
P मान ले कुनै पनि डेटासेटको सम्भाव्यता मानलाई प्रतिनिधित्व गर्दछ। यदि शून्य परिकल्पना साँचो हो भने, तथ्याङ्कीय परिकल्पना परीक्षणबाट निष्कर्षहरू प्राप्त गर्ने सम्भावनालाई वास्तविक नतिजाहरू जत्तिकै गम्भीर रूपमा p-value भनिन्छ। महत्वको सबैभन्दा सानो स्तर जसमा शून्य परिकल्पनालाई अस्वीकार गरिनेछ p-value द्वारा अस्वीकार बिन्दुहरूको विकल्पको रूपमा प्रदान गरिएको छ। वैकल्पिक परिकल्पनाको लागि बलियो समर्थन कम p-value द्वारा संकेत गरिएको छ।
3 Excel ANOVA मा P मान गणना गर्न उपयुक्त उदाहरणहरू
उदाहरणहरू प्रदर्शन गर्न, हामी को डेटासेट विचार गर्छौं। दुई नमूनाहरू। हामी कुनै पनि संस्थाको दुई शिफ्टबाट गणित र रसायनशास्त्र मा चार विद्यार्थीहरूको परीक्षा अंक लिन्छौँ। त्यसोभए, हामी दावी गर्न सक्छौं कि हाम्रो डेटासेट कक्षहरूको दायरामा छ B5:D12।

१. एकल कारक एनोभा विश्लेषण प्रयोग गर्दै
पहिलो उदाहरणमा, हामी तपाईंलाई Anova: Single Factor प्रयोग गरेर P मान गणना गर्ने प्रक्रिया देखाउनेछौं। यस विधिका चरणहरू तल दिइएका छन्:
📌चरणहरू:
- सबैभन्दा पहिले, डेटा ट्याबबाट, समूह विश्लेषण बाट डेटा टूलप्याक चयन गर्नुहोस्। यदि तपाइँसँग डेटा ट्याबमा डेटा टूलप्याक छैन भने, तपाइँ यसलाई एक्सेल विकल्पहरू बाट सक्षम गर्न सक्नुहुन्छ।
- परिणामको रूपमा, डेटा विश्लेषण भनिने एउटा सानो संवाद बाकस देखा पर्नेछ।
- अब, Anova: एकल कारक<चयन गर्नुहोस्। 2> विकल्पमा क्लिक गर्नुहोस् र ठीक छ क्लिक गर्नुहोस्।

- अर्को संवाद बक्स भनिन्छ Anova: सिंगल फ्याक्टर देखा पर्नेछ।
- त्यसपछि, इनपुट खण्डमा, डेटासेटको इनपुट सेल दायरा चयन गर्नुहोस्। यहाँ, इनपुट दायरा $C$5:$D$12 हो।
- स्तम्भ<2 मा द्वारा समूहबद्ध विकल्प राख्नुहोस्।>।
- त्यसपछि, आउटपुट सेक्सनमा, तपाईंले नतिजा कसरी प्राप्त गर्न चाहनुहुन्छ भनेर निर्दिष्ट गर्नुपर्छ। तपाईं यसलाई तीन विभिन्न तरिकामा प्राप्त गर्न सक्नुहुन्छ। हामी उही पाना मा नतिजा प्राप्त गर्न चाहन्छौं।
- त्यसैले, हामी आउटपुट दायरा विकल्प छान्छौं र सेल सन्दर्भलाई $F$4<को रूपमा बुझाउँछौं। 2>।
- अन्तमा, ठीक छ मा क्लिक गर्नुहोस्।

- एक सेकेन्ड भित्र, तपाईंले परिणाम प्राप्त गर्नुहुनेछ। । हाम्रो मनपर्ने P मान सेल K14 मा छ। यस बाहेक, तपाईंले कक्षहरूको दायरामा सारांश परिणाम पनि पाउनुहुनेछ F6:J9 ।
 यो पनि हेर्नुहोस्: कसरी एक्सेलमा फुटर सम्पादन गर्ने (3 द्रुत विधिहरू)
यो पनि हेर्नुहोस्: कसरी एक्सेलमा फुटर सम्पादन गर्ने (3 द्रुत विधिहरू)यसैले , हामी भन्न सक्छौं कि हाम्रो विधिले राम्रोसँग काम गर्यो, र हामीले Excel Anova मा P मान गणना गर्न सक्षम भयौं।
🔎 नतिजाको व्याख्या
यो पनि हेर्नुहोस्: Excel मा औसत प्रतिशत कसरी गणना गर्ने (3 सजिलो तरिका)यसमाउदाहरण, हामीले 0.1462 को P मान पायौं। यसको मतलब दुबै समूहमा समान संख्या प्राप्त गर्ने सम्भावना 0.1462 वा 14.62% हो। त्यसोभए, हामीले यो P मान हाम्रो रोजेको डेटासेटमा महत्त्वपूर्ण छ भनी दाबी गर्न सक्छौं।
थप पढ्नुहोस्: एक्सेलमा ANOVA एकल कारक परिणामहरू कसरी व्याख्या गर्ने
2. प्रतिकृति ANOVA विश्लेषण संग दुई-कारक को उपयोग
निम्न उदाहरणमा, हामी हाम्रो P मान गणना गर्न Anova: प्रतिकृति संग दुई-कारक प्रक्रिया प्रयोग गर्न जाँदैछौं। डाटासेट। यस दृष्टिकोणका चरणहरू निम्नानुसार दिइएका छन्:
📌 चरणहरू:
- पहिले, डेटा ट्याबमा, <चयन गर्नुहोस्। 1>डेटा टूलप्याक समूहबाट विश्लेषण। यदि तपाईंसँग डेटा ट्याबमा डेटा टूलप्याक छैन भने, तपाईंले यसलाई बाट सक्षम गर्न सक्नुहुन्छ। 1>एक्सेल विकल्पहरू ।

- परिणामको रूपमा, डेटा विश्लेषण संवाद बाकस देखा पर्नेछ।<11
- त्यसपछि, Anova: प्रतिकृतिसँग दुई-फ्याक्टर छान्नुहोस् र ठीक छ मा क्लिक गर्नुहोस्।
-
- अर्को एउटा सानो संवाद बक्स भनिन्छ Anova: प्रतिकृतिसँग दुई-फ्याक्टर देखा पर्नेछ।
- अब, इनपुट सेक्सनमा, डेटासेटको इनपुट सेल दायरा चयन गर्नुहोस्। । यहाँ, इनपुट दायरा $B$4:$D$12 हो।
- त्यसपछि, प्रति नमूना पङ्क्तिहरू फिल्डलाई को रूपमा बुझाउनुहोस्। 4 ।
- पछि, आउटपुट खण्डमा, तपाईंले नतिजा कसरी प्राप्त गर्न चाहनुहुन्छ भनेर उल्लेख गर्नुपर्नेछ। तपाईं यसलाई भित्र पाउन सक्नुहुन्छ तीन विभिन्न तरिकाहरू। यस उदाहरणमा, हामी नयाँ कार्यपत्र मा परिणाम प्राप्त गर्न चाहन्छौं।
- यसैले, नयाँ कार्यपत्र प्लाई विकल्प छान्नुहोस् र तपाईंको अनुसार उपयुक्त नाम लेख्नुहोस्। इच्छा। हामी यो नामको नयाँ कार्यपत्र प्राप्त गर्न Anova Two Factor लेख्छौं।
- अन्तमा, ठीक छ मा क्लिक गर्नुहोस्।
- तपाईँले एउटा नयाँ कार्यपत्र सिर्जना भएको देख्नुहुनेछ, र एक्सेलले त्यो कार्यपत्रमा विश्लेषण परिणाम देखाउनेछ। हाम्रो वांछित P मान कक्षहरूको दायरामा छ G25:G27 । यस बाहेक, तपाईले सेलहरूको दायरामा सारांश परिणाम पनि पाउनुहुनेछ B3:D20 ।
- पहिले, डेटा ट्याबमा, चयन गर्नुहोस्। डेटा टुलप्याक समूहबाट विश्लेषण। यदि तपाईंसँग डेटा ट्याबमा डेटा टूलप्याक छैन भने, तपाईंले यसलाई सक्रिय गर्न सक्नुहुन्छ। एक्सेल विकल्पहरू ।
- परिणामको रूपमा, डेटा विश्लेषण नामक सानो संवाद बाकस देखा पर्नेछ। .
- अर्को, Anova: Two-factor Without Replication विकल्प चयन गर्नुहोस् र ठीक छ थिच्नुहोस्।
- अर्को सानो संवाद बक्स भनिन्छ Anova: दुई-फ्याक्टर बिना प्रतिकृति देखा पर्नेछ।
- त्यसपछि, इनपुट खण्डमा, इनपुट छान्नुहोस्। डाटासेट को सेल दायरा। यहाँ, इनपुट दायरा $B$4:$D$12 हो।
- त्यसपछि, लेबलहरू विकल्प जाँच गर्नुहोस् यदि यो अझै जाँच गरिएको छैन भने। .
- अब, आउटपुट सेक्सनमा, तपाईंले नतिजा कसरी प्राप्त गर्न चाहनुहुन्छ भनेर निर्दिष्ट गर्नुपर्छ। तपाईं यसलाई तीन विभिन्न तरिकामा प्राप्त गर्न सक्नुहुन्छ। हामी उही पाना मा नतिजा प्राप्त गर्न चाहन्छौं।
- त्यसैले, हामी आउटपुट दायरा विकल्प रोज्छौं र सेल सन्दर्भलाई $F$4<को रूपमा बुझाउँछौं। 2>।
- अन्तमा, ठीक छ मा क्लिक गर्नुहोस्।
- एक सेकेन्ड भित्र, तपाईंले परिणाम देख्नुहुनेछ। देखि देखाइएको छसेल F4 । हाम्रो मनपर्ने P मान सेल K22:K23 को दायरामा छ। यस बाहेक, तपाईंले कक्षहरूको दायरामा सारांश परिणाम पनि पाउनुहुनेछ F6:J17 ।



त्यसैले, हामी भन्न सक्छौं कि हाम्रो विधिले प्रभावकारी रूपमा काम गर्यो, र हामीले Excel Anova मा P मान गणना गर्न सक्षम भयौं।
🔎 नतिजाको व्याख्या
यस उदाहरणमा, स्तम्भहरू को लागि P-मान 0.0373 हो, जुन सांख्यिकीय रूपमा महत्त्वपूर्ण छ, त्यसैले हामी भन्न सक्छौं कि परीक्षामा विद्यार्थीहरूको प्रदर्शनमा परिवर्तनको प्रभाव छ। तर उदाहरण प्रक्रियाको 3rd छविले मान 0.05 को अल्फा मानको नजिक छ भनेर देखाउँछ, त्यसैले प्रभाव कम महत्त्वपूर्ण छ।
त्यसैगरी, अन्तरक्रियाहरू को P-मान 0.0010 हो, जुन अल्फा मान भन्दा धेरै कम छ, त्यसैले यसको सांख्यिकीय रूपमा उच्च महत्त्व छ, र हामी दुवै परीक्षामा शिफ्टको प्रभाव धेरै उच्च रहेको टिप्पणी गर्नुहोस्।
थप पढ्नुहोस्: 1>कसरी व्याख्या गर्नेएक्सेलमा ANOVA परिणामहरू (3 तरिकाहरू)
3. प्रतिकृति बिना दुई-कारक लागू गर्दै ANOVA विश्लेषण
यस उदाहरणमा, Anova: प्रतिकृति बिना दुई-कारक हामीलाई P मान गणना गर्न मद्दत गर्नेछ। प्रक्रिया तल चरणबद्ध रूपमा वर्णन गरिएको छ:
📌 चरणहरू:




अन्तमा , हामी भन्न सक्छौं कि हाम्रो विधिले सफलतापूर्वक काम गर्यो, र हामीले Excel Anova मा P मान गणना गर्न सक्षम भयौं।
🔎 नतिजाको व्याख्या
यहाँ, स्तम्भहरू को लागि P-मान 0.2482 हो, जुन सांख्यिकीय रूपमा महत्त्वपूर्ण छ। तसर्थ, परीक्षामा विद्यार्थीहरूको प्रदर्शनमा परिवर्तनको प्रभाव छ भन्न सक्छौं। यद्यपि, मान 0.05 को अल्फा मानको नजिक छ, त्यसैले प्रभाव कम महत्त्वपूर्ण छ।
थप पढ्नुहोस्: एक्सेलमा दुई-तरिका ANOVA परिणामहरू कसरी व्याख्या गर्ने
निष्कर्ष
यो यो लेखको अन्त्य हो। मलाई आशा छ कि यो लेख तपाईको लागि उपयोगी हुनेछ र तपाईले Excel Anova मा P मान गणना गर्न सक्षम हुनुहुनेछ। यदि तपाईंसँग कुनै थप प्रश्न वा सिफारिसहरू छन् भने कृपया तलको टिप्पणी सेक्सनमा हामीसँग थप प्रश्नहरू वा सिफारिसहरू साझा गर्नुहोस्।
धेरै Excel-का लागि हाम्रो वेबसाइट, ExcelWIKI जाँच गर्न नबिर्सनुहोस्। सम्बन्धित समस्या र समाधान। नयाँ तरिकाहरू सिक्नुहोस् र बढ्दै जानुहोस्!
-
-
-
-
