
সুচিপত্র
ডাটা বিশ্লেষণের আধুনিক যুগে, আপনাকে Excel-এ P মান গণনা করতে হতে পারে। আপনি ওয়ান ওয়ে আনোভা বা টু ওয়ে আনোভা ব্যবহার করে এটি করতে পারেন। এই নিবন্ধে, আমরা আপনাকে তিনটি P মান গণনা করার সম্ভাব্য উপায় প্রদর্শন করতে যাচ্ছি। এক্সেল আনোভাতে। আপনি যদি এটি সম্পর্কে কৌতূহলী হন, আমাদের অনুশীলন ওয়ার্কবুক ডাউনলোড করুন এবং আমাদের অনুসরণ করুন।
অনুশীলন ওয়ার্কবুক ডাউনলোড করুন
আপনি এই নিবন্ধটি পড়ার সময় অনুশীলনের জন্য এই অনুশীলন ওয়ার্কবুকটি ডাউনলোড করুন।
P Value.xlsx গণনা করুন
ANOVA বিশ্লেষণ কি?
ANOVA একটি ডেটাসেটের উপর কোন উপাদানগুলির উল্লেখযোগ্য প্রভাব রয়েছে তা নির্ধারণ করার প্রথম সুযোগ আমাদের প্রদান করে৷ বিশ্লেষণটি সম্পূর্ণ করার পর, একজন বিশ্লেষক পদ্ধতিগত কারণের উপর অতিরিক্ত বিশ্লেষণ করেন যা সেই ডেটা সেটের অসঙ্গতিপূর্ণ প্রকৃতিকে উল্লেখযোগ্যভাবে প্রভাবিত করে। উপরন্তু, তিনি আনুমানিক রিগ্রেশন বিশ্লেষণের সাথে প্রাসঙ্গিক অতিরিক্ত ডেটা তৈরি করতে f-test -এ আনোভা বিশ্লেষণের ফলাফলগুলি ব্যবহার করেন। তাদের মধ্যে সংযোগ। ANOVA হল একটি পরিসংখ্যানগত পদ্ধতি যা একটি ডেটাসেটের মধ্যে দেখা বৈচিত্র্যকে দুটি ভাগে ভাগ করে বিশ্লেষণ করতে ব্যবহৃত হয়:
-
-
-
-
-
-
-
-
-
-
-
-
- সিস্টেমেটিক ফ্যাক্টর এবং
- এলোমেলোফ্যাক্টর
-
-
-
-
-
-
-
-
-
আনোভার গাণিতিক সূত্র হল:
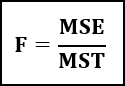 <3
<3 এখানে,
- F = আনোভা সহগ,
- MST = চিকিত্সার কারণে বর্গক্ষেত্রের গড় যোগফল,<11
- MSE = ত্রুটির কারণে বর্গক্ষেত্রের গড় যোগফল।
-
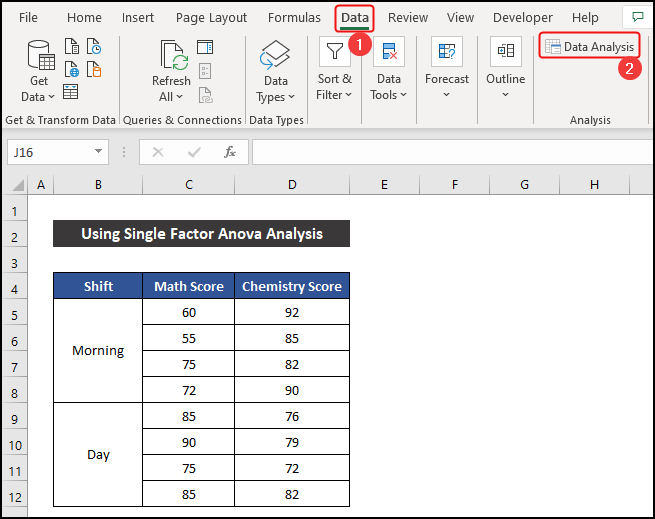
- প্রথমে, ডেটা ট্যাব থেকে, বিশ্লেষণ গ্রুপ থেকে ডেটা টুলপ্যাক নির্বাচন করুন। আপনার যদি ডেটা ট্যাবে ডেটা টুলপ্যাক না থাকে, তাহলে আপনি এক্সেল বিকল্পগুলি থেকে এটি সক্রিয় করতে পারেন।
- ফলে ডেটা অ্যানালাইসিস নামে একটি ছোট ডায়ালগ বক্স আসবে।
- এখন, আনোভা: সিঙ্গেল ফ্যাক্টর<নির্বাচন করুন। 2> বিকল্পে ক্লিক করুন এবং ঠিক আছে ক্লিক করুন।
- অন্য একটি ডায়ালগ বক্স যাকে বলা হয় আনোভা: সিঙ্গেল ফ্যাক্টর প্রদর্শিত হবে .
- তারপর, ইনপুট বিভাগে, ডেটাসেটের ইনপুট সেল পরিসর নির্বাচন করুন। এখানে, ইনপুট রেঞ্জ হল $C$5:$D$12 ।
- কলাম<2 এ গ্রুপ করা বিকল্পটি রাখুন।>.
- এর পর, আউটপুট বিভাগে, আপনি কীভাবে ফলাফল পেতে চান তা উল্লেখ করতে হবে। আপনি এটি তিন বিভিন্ন উপায়ে পেতে পারেন। আমরা একই শীটে ফলাফল পেতে চাই।
- সুতরাং, আমরা আউটপুট রেঞ্জ বিকল্পটি নির্বাচন করি এবং সেল রেফারেন্সটিকে $F$4<হিসাবে চিহ্নিত করি। 2>।
- অবশেষে, ঠিক আছে ক্লিক করুন।
- এক সেকেন্ডের মধ্যে, আপনি ফলাফল পাবেন . আমাদের কাঙ্ক্ষিত P মানটি সেলে রয়েছে K14 । এছাড়াও, আপনি সেলের পরিসরে একটি সারাংশ ফলাফলও পাবেন F6:J9 ।
- প্রথমে, ডেটা ট্যাবে, <নির্বাচন করুন 1>ডেটা টুলপ্যাক গ্রুপ থেকে বিশ্লেষণ। যদি আপনার ডেটা ট্যাবে ডেটা টুলপ্যাক না থাকে, তাহলে আপনি এটি থেকে সক্রিয় করতে পারেন। 1>এক্সেল বিকল্পগুলি ।
- এর ফলে, ডেটা বিশ্লেষণ ডায়ালগ বক্স প্রদর্শিত হবে।
- এর পর, আনোভা: টু-ফ্যাক্টর উইথ রেপ্লিকেশন বেছে নিন এবং ঠিক আছে ক্লিক করুন।
- আরেকটি ছোট ডায়ালগ বক্স যার নাম আনোভা: টু-ফ্যাক্টর উইথ রেপ্লিকেশন প্রদর্শিত হবে।
- এখন, ইনপুট বিভাগে, ডেটাসেটের ইনপুট সেল পরিসর নির্বাচন করুন। . এখানে, ইনপুট রেঞ্জ হল $B$4:$D$12 ।
- তারপর, প্রতি নমুনা ক্ষেত্রটিকে হিসাবে চিহ্নিত করুন 4 ।
- পরে, আউটপুট বিভাগে, আপনি কীভাবে ফলাফল পেতে চান তা উল্লেখ করতে হবে। আপনি এটা পেতে পারেন তিন বিভিন্ন উপায়ে। এই উদাহরণে, আমরা একটি নতুন ওয়ার্কশীটে ফলাফল পেতে চাই।
- এইভাবে, নতুন ওয়ার্কশীট প্লাই বিকল্পটি বেছে নিন এবং আপনার অনুযায়ী একটি উপযুক্ত নাম লিখুন ইচ্ছা. এই নামের একটি নতুন ওয়ার্কশীট পেতে আমরা আনোভা টু ফ্যাক্টর লিখি।
- অবশেষে, ঠিক আছে ক্লিক করুন।
- আপনি লক্ষ্য করবেন একটি নতুন ওয়ার্কশীট তৈরি হবে, এবং এক্সেল সেই ওয়ার্কশীটে বিশ্লেষণের ফলাফল দেখাবে। আমাদের কাঙ্ক্ষিত P মানটি কোষের পরিসরে রয়েছে G25:G27 । এছাড়াও, আপনি সেলের পরিসরে একটি সংক্ষিপ্ত ফলাফলও পাবেন B3:D20 ।
- প্রথমে, ডেটা ট্যাবে, নির্বাচন করুন গ্রুপ থেকে ডেটা টুলপ্যাক এক্সেল বিকল্পগুলি ।
- এর ফলে, ডেটা বিশ্লেষণ নামে একটি ছোট ডায়ালগ বক্স প্রদর্শিত হবে .
- এরপর, আনোভা: টু-ফ্যাক্টর উইদাউট রেপ্লিকেশন বিকল্পটি নির্বাচন করুন এবং ঠিক আছে টিপুন।
- আরেকটি ছোট ডায়ালগ বক্স নামক আনোভা: টু-ফ্যাক্টর উইদাউট রেপ্লিকেশন প্রদর্শিত হবে।
- এর পরে, ইনপুট বিভাগে, ইনপুটটি নির্বাচন করুন ডেটাসেটের সেল পরিসর। এখানে, ইনপুট রেঞ্জ হল $B$4:$D$12 ।
- তারপর, লেবেল বিকল্পটি চেক করুন যদি এটি এখনও চেক করা না থাকে .
- এখন, আউটপুট বিভাগে, আপনি কীভাবে ফলাফল পেতে চান তা উল্লেখ করতে হবে। আপনি এটি তিন বিভিন্ন উপায়ে পেতে পারেন। আমরা একই শীটে ফলাফল পেতে চাই।
- অতএব, আমরা আউটপুট রেঞ্জ বিকল্পটি নির্বাচন করি এবং সেল রেফারেন্সটিকে $F$4<হিসাবে চিহ্নিত করি। 2>।
- অবশেষে, ঠিক আছে ক্লিক করুন।
- এক সেকেন্ডের মধ্যে, আপনি ফলাফলটি লক্ষ্য করবেন থেকে দেখানো হয়েছেসেল F4 । আমাদের কাঙ্ক্ষিত P মানটি সেলের পরিসরে K22:K23 । এছাড়াও, আপনি সেলের পরিসরে একটি সারাংশ ফলাফলও পাবেন F6:J17 ।
P মান কী?
P মান যে কোনো ডেটাসেটের সম্ভাব্যতার মান উপস্থাপন করে। যদি নাল হাইপোথিসিস সত্য হয়, তাহলে পরিসংখ্যানগত হাইপোথিসিস পরীক্ষা থেকে ফলাফল প্রাপ্তির সম্ভাবনা যা প্রকৃত ফলাফলের মতোই গুরুতর তা পি-মান হিসাবে পরিচিত। তাত্পর্যের ক্ষুদ্রতম স্তর যেখানে শূন্য অনুমান প্রত্যাখ্যান করা হবে তা প্রত্যাখ্যান পয়েন্টের বিকল্প হিসাবে p-মান দ্বারা প্রদান করা হয়। বিকল্প অনুমানের জন্য শক্তিশালী সমর্থন একটি নিম্ন p-মান দ্বারা নির্দেশিত হয়৷
3 এক্সেল ANOVA-এ P মান গণনা করার জন্য উপযুক্ত উদাহরণ
উদাহরণ প্রদর্শনের জন্য, আমরা এর একটি ডেটাসেট বিবেচনা করি দুটি নমুনা। আমরা যেকোনো প্রতিষ্ঠানের দুই শিফট থেকে গণিত এবং রসায়নে ছাত্রদের চার পরীক্ষার নম্বর নিই। সুতরাং, আমরা দাবি করতে পারি যে আমাদের ডেটাসেট কোষের পরিসরে রয়েছে B5:D12।

1. একক ফ্যাক্টর ANOVA বিশ্লেষণ
<ব্যবহার করে 0>প্রথম উদাহরণে, আমরা আপনাকে আনোভা: একক ফ্যাক্টর ব্যবহার করে P মান গণনা করার পদ্ধতি দেখাব। এই পদ্ধতির ধাপগুলি নীচে দেওয়া হল:📌ধাপ:



এভাবে , আমরা বলতে পারি যে আমাদের পদ্ধতিটি পুরোপুরি কাজ করেছে, এবং আমরা এক্সেল আনোভাতে P মান গণনা করতে সক্ষম হয়েছি।
🔎 ফলাফলের ব্যাখ্যা
এতেউদাহরণস্বরূপ, আমরা 0.1462 এর একটি P মান পেয়েছি। এর মানে হল উভয় গ্রুপে একই নম্বর পাওয়ার সম্ভাবনা 0.1462 বা 14.62% । সুতরাং, আমরা দাবি করতে পারি যে আমাদের নির্বাচিত ডেটাসেটে এই P মানটির তাৎপর্য রয়েছে।
আরও পড়ুন: এক্সেলে অ্যানোভা সিঙ্গেল ফ্যাক্টর ফলাফল কীভাবে ব্যাখ্যা করবেন
2. প্রতিলিপি ANOVA বিশ্লেষণের সাথে টু-ফ্যাক্টর ব্যবহার করা
নিম্নলিখিত উদাহরণে, আমরা আমাদের P মান গণনা করতে আনোভা: প্রতিলিপির সাথে টু-ফ্যাক্টর প্রক্রিয়া ব্যবহার করতে যাচ্ছি। ডেটাসেট এই পদ্ধতির ধাপগুলি নিম্নরূপ দেওয়া হয়েছে:
📌 ধাপ:




অতএব, আমরা বলতে পারি যে আমাদের পদ্ধতিটি কার্যকরভাবে কাজ করেছে, এবং আমরা এক্সেল আনোভাতে P মান গণনা করতে সক্ষম হয়েছি।
🔎 ফলাফলের ব্যাখ্যা
এই উদাহরণে, কলামের জন্য P-মান হল 0.0373 , যা পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ, তাই আমরা বলতে পারি যে পরীক্ষায় শিক্ষার্থীদের পারফরম্যান্সের উপর পরিবর্তনের প্রভাব রয়েছে। কিন্তু উদাহরণ পদ্ধতির 3য় চিত্রটি দেখায় যে মানটি 0.05 এর আলফা মানের কাছাকাছি, তাই প্রভাবটি কম তাৎপর্যপূর্ণ।
একইভাবে, ইন্টার্যাকশনের P-মান হল 0.0010 , যা আলফা মানের থেকে অনেক কম, তাই এটির পরিসংখ্যানগতভাবে উচ্চ তাৎপর্য রয়েছে এবং আমরা পারি মন্তব্য করুন যে উভয় পরীক্ষায় শিফটের প্রভাব খুব বেশি৷
আরও পড়ুন: কিভাবে ব্যাখ্যা করবেনএক্সেলে আনোভা ফলাফল (3 উপায়)
3. প্রতিলিপি ছাড়াই দ্বি-ফ্যাক্টর প্রয়োগ করা ANOVA বিশ্লেষণ
এই উদাহরণে, আনোভা: প্রতিলিপি ছাড়াই টু-ফ্যাক্টর আমাদের P মান গণনা করতে সাহায্য করবে। পদ্ধতিটি ধাপে ধাপে নিচে বর্ণনা করা হয়েছে:
📌 ধাপ:




অবশেষে , আমরা বলতে পারি যে আমাদের পদ্ধতি সফলভাবে কাজ করেছে, এবং আমরা এক্সেল আনোভাতে P মান গণনা করতে সক্ষম হয়েছি।
🔎 ফলাফলের ব্যাখ্যা
এখানে, কলামের জন্য P-মান হল 0.2482 , যা পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ। সুতরাং, আমরা বলতে পারি যে পরীক্ষায় শিক্ষার্থীদের পারফরম্যান্সের উপর পরিবর্তনের প্রভাব রয়েছে। যাইহোক, মানটি 0.05 এর আলফা মানের কাছাকাছি, তাই প্রভাবটি কম তাৎপর্যপূর্ণ।
আরও পড়ুন: কিভাবে এক্সেল এ দ্বি-মুখী ANOVA ফলাফল ব্যাখ্যা করবেন
উপসংহার
এটি এই নিবন্ধের শেষ। আমি আশা করি এই নিবন্ধটি আপনার জন্য সহায়ক হবে এবং আপনি এক্সেল আনোভাতে P মান গণনা করতে সক্ষম হবেন। আপনার যদি আরও কোনো প্রশ্ন বা সুপারিশ থাকে তাহলে অনুগ্রহ করে নিচের মন্তব্য বিভাগে আমাদের সাথে আরও কোনো প্রশ্ন বা সুপারিশ শেয়ার করুন।
বিভিন্ন Excel-এর জন্য আমাদের ওয়েবসাইট, ExcelWIKI চেক করতে ভুলবেন না। সম্পর্কিত সমস্যা এবং সমাধান। নতুন পদ্ধতি শিখতে থাকুন এবং বাড়তে থাকুন!
-
