
Innholdsfortegnelse
I den moderne tidsepoken med dataanalyse kan det hende du må beregne P-verdien i Excel. Du kan gjøre dette ved å bruke One Way Anova eller Two Way Anova. I denne artikkelen skal vi demonstrere tre mulige måter å beregne P-verdien på. i Excel Anova. Hvis du er nysgjerrig på det, last ned øvelsesarbeidsboken vår og følg oss.
Last ned øvelsesarbeidsbok
Last ned denne øvelsesarbeidsboken for øvelse mens du leser denne artikkelen.
Beregn P-verdi.xlsx
Hva er ANOVA-analyse?
ANOVA gir oss den første muligheten til å finne ut hvilke faktorer som har en signifikant effekt på et datasett. Etter å ha fullført analysen, gjør en analytiker ekstra analyse av metodologiske faktorene som i betydelig grad påvirker den inkonsekvente naturen til det datasettet. I tillegg bruker han Anova-analysefunnene i f-testen for å lage ekstra data som er relevante for den estimerte regresjonsanalysen. ANOVA-analysen sammenligner mange datasett samtidig for å se om det er noen forbindelser mellom dem. ANOVA er en statistisk metode som brukes til å analysere varians observert i et datasett ved å dele det i to seksjoner:
-
-
-
-
-
-
-
-
-
-
-
-
- Systematiske faktorer og
- Tilfeldigfaktorer
-
-
-
-
-
-
-
-
-
-
-
Den matematiske formelen for Anova er:
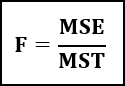
Her,
- F = Anova-koeffisient,
- MST = Gjennomsnittlig sum av kvadrater på grunn av behandling,
- MSE = Gjennomsnittlig sum av kvadrater på grunn av feil.
Hva er P-verdi?
P-verdien representerer sannsynlighetsverdien for ethvert datasett. Hvis nullhypotesen er sann, er sannsynligheten for å motta funn fra en statistisk hypotesetest som er minst like alvorlige som de faktiske resultatene kjent som p-verdien. Det minste signifikansnivået der nullhypotesen ville bli forkastet, er gitt av p-verdien som et alternativ til avvisningspunkter. Sterkere støtte for den alternative hypotesen indikeres med en lavere p-verdi.
3 egnede eksempler for å beregne P-verdi i Excel ANOVA
For å demonstrere eksemplene tar vi for oss et datasett med to prøver. Vi tar fire studenters eksamenskarakterer i matte og kjemi fra to skift ved enhver institusjon. Så vi kan hevde at datasettet vårt er i celleområdet B5:D12.

1. Bruke enkeltfaktor ANOVA-analyse
I det første eksemplet vil vi vise deg fremgangsmåten for å beregne P-verdien ved å bruke Anova: Single Factor. Trinnene til denne metoden er gitt nedenfor:
📌Trinn:
- Først av alt, fra Data -fanen, velg Data Toolpak fra gruppen Analyse. Hvis du ikke har Data Toolpak i kategorien Data , kan du aktivere den fra Excel-alternativene .
- Som et resultat vil en liten dialogboks kalt Dataanalyse vises.
- Nå velger du Anova: Single Factor og klikk OK .

- En annen dialogboks kalt Anova: Single Factor vil vises .
- Deretter, i Inndata -delen, velg inndatacelleområdet til datasettet. Her er Inndataområde $C$5:$D$12 .
- Behold Gruppert etter -alternativet i Kolonner .
- Etter det, i Output -delen, må du spesifisere hvordan du vil få resultatet. Du kan få det på tre forskjellige måter. Vi ønsker å få resultatet på samme ark .
- Så vi velger alternativet Output Range og angir cellereferansen som $F$4 .
- Til slutt klikker du OK .

- I løpet av et sekund får du resultatet . Vår ønskede P-verdi er i celle K14 . Utenom det vil du også få et sammendrag resultat i celleområdet F6:J9 .

Dermed , kan vi si at metoden vår fungerte perfekt, og vi var i stand til å beregne P-verdien i Excel Anova.
🔎 Tolkning av resultatet
I dettefor eksempel fikk vi en P-verdi på 0,1462 . Det betyr at muligheten for å få et tilsvarende tall i begge gruppene er 0,1462 eller 14,62 % . Så vi kan hevde at denne P-verdien har betydning i vårt valgte datasett.
Les mer: Hvordan tolke ANOVA Single Factor-resultater i Excel
2. Bruk av tofaktor med replikering ANOVA-analyse
I følgende eksempel skal vi bruke Anova: tofaktor med replikering -prosessen for å beregne P-verdien til vår datasett. Trinnene for denne tilnærmingen er gitt som følger:
📌 Trinn:
- Først, i Data -fanen, velg Data Toolpak fra gruppen Analyse. Hvis du ikke har Data Toolpak i kategorien Data , kan du aktivere den fra Excel-alternativene .

- Som et resultat vil dialogboksen Dataanalyse vises.
- Deretter velger du Anova: Tofaktor med replikering og klikker OK .

- En annen liten dialogboks kalt Anova: Tofaktor med replikering vil vises.
- Nå, i Inndata -delen, velg inndatacelleområdet til datasettet . Her er Inndataområde $B$4:$D$12 .
- Deretter angir du feltet Rader per prøve som 4 .
- Etterpå, i Output -delen, må du nevne hvordan du ønsker å få resultatet. Du kan få den inn tre forskjellige måter. I dette eksemplet ønsker vi å få resultatet i et nytt regneark .
- Velg derfor alternativet Nytt regnearklag og skriv ned et passende navn i henhold til din ønske. Vi skriver Anova Two Factor for å få et nytt regneark med dette navnet.
- Til slutt klikker du OK .

- Du vil legge merke til at et nytt regneark vil bli opprettet, og Excel vil vise analyseresultatet på det regnearket. Vår ønskede P-verdi er i celleområdet G25:G27 . I tillegg vil du også få et oppsummeringsresultat i celleområdet B3:D20 .

Derfor kan vi si at vår metoden fungerte effektivt, og vi var i stand til å beregne P-verdien i Excel Anova.
🔎 Tolkning av resultatet
I dette eksemplet, P-verdien for kolonnene er 0,0373 , som er statistisk signifikant, så vi kan si at det er en effekt av skift på prestasjonene til studentene på eksamen. Men tredje -bildet av eksempelprosedyren viser at verdien er nær alfa -verdien på 0,05 , så effekten er mindre signifikant.
På samme måte er P-verdien til interaksjoner 0,0010 , som er mye mindre enn alfa -verdien, så den har statistisk høy signifikans, og vi kan bemerk at effekten av skiftet på begge eksamener er svært høy.
Les mer: Hvordan tolkeANOVA-resultater i Excel (3 måter)
3. Bruk av tofaktor uten replikering ANOVA-analyse
I dette eksemplet er Anova: tofaktor uten replikering vil hjelpe oss å beregne P-verdien. Prosedyren er beskrevet nedenfor trinn for trinn:
📌 Trinn:
- Først, i kategorien Data , velg Data Toolpak fra gruppen Analyse. Hvis du ikke har Data Toolpak i kategorien Data , kan du aktivere den fra Excel-alternativene .

- Som et resultat vil en liten dialogboks kalt Dataanalyse vises .
- Deretter velger du Anova: Tofaktor uten replikering og trykker OK .

- En annen liten dialogboks kalt Anova: Tofaktor uten replikering vises.
- Deretter, i Inndata -delen, velger du inngangen celleområdet til datasettet. Her er Inndataområde $B$4:$D$12 .
- Deretter merker du av for Etiketter hvis det ikke er merket ennå .
- Nå, i delen Utdata , må du spesifisere hvordan du vil få resultatet. Du kan få det på tre forskjellige måter. Vi ønsker å få resultatet i samme ark .
- Derfor velger vi alternativet Output Range og angir cellereferansen som $F$4 .
- Til slutt klikker du OK .

- I løpet av et sekund vil du legge merke til resultatet vist fracelle F4 . Vår ønskede P-verdi er i området til celle K22:K23 . I tillegg vil du også få et sammendrag resultat i celleområdet F6:J17 .

Til slutt , kan vi si at metoden vår fungerte vellykket, og vi var i stand til å beregne P-verdien i Excel Anova.
🔎 Tolkning av resultatet
Her er P-verdien for kolonner 0,2482 , som er statistisk signifikant. Så vi kan si at det er en effekt av skift på prestasjonene til studentene i eksamen. Verdien er imidlertid nær alfa -verdien på 0,05 , så effekten er mindre signifikant.
Les mer: Slik tolker du toveis ANOVA-resultater i Excel
Konklusjon
Det er slutten på denne artikkelen. Jeg håper at denne artikkelen vil være nyttig for deg, og du vil kunne beregne P-verdien i Excel Anova. Vennligst del eventuelle ytterligere spørsmål eller anbefalinger med oss i kommentarfeltet nedenfor hvis du har flere spørsmål eller anbefalinger.
Ikke glem å sjekke nettsiden vår, ExcelWIKI , for flere Excel- relaterte problemer og løsninger. Fortsett å lære nye metoder og fortsett å vokse!
