
Innholdsfortegnelse
Vi bruker regresjonsanalyse når vi har data fra to variabler fra to forskjellige kilder og ønsker å bygge en relasjon mellom dem. Regresjonsanalyse gir oss en lineær modell som lar oss forutsi mulige utfall. Det vil være noen forskjeller mellom de anslåtte og faktiske verdiene av åpenbare årsaker. Som et resultat beregner vi standardfeilen ved å bruke regresjonsmodellen, som er gjennomsnittsfeilen mellom predikerte og faktiske verdier. I denne opplæringen vil vi vise deg hvordan du beregner standardfeilen for regresjonsanalyse i Excel .
Last ned øvelsesarbeidsbok
Last ned denne øvelsesarbeidsboken for å trene mens du er leser denne artikkelen.
Regresjonsstandardfeil.xlsx
4 enkle trinn for å beregne standardregresjonsfeil i Excel
Anta at du har et datasett med en uavhengig variabel ( X ) og en avhengig variabel ( Y ) . Som du kan se, har de ingen signifikant relasjon. Men vi ønsker å bygge en. Som et resultat vil vi bruke Regresjonsanalyse for å lage et lineært forhold mellom de to. Vi vil beregne standardfeilen mellom de to variablene ved å bruke regresjonsanalysen. Vi vil gå over noen av regresjonsmodellens parametere i andre halvdel av artikkelen for å hjelpe deg med å tolke den.

Trinn 1: Bruk Data Analysis Command påOpprett en regresjonsmodell
- Gå først til Data -fanen og klikk på Dataanalyse kommando.

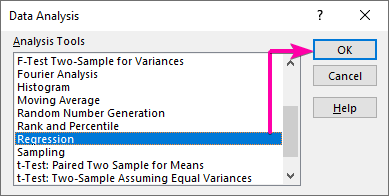
- Fra listeboksen Dataanalyse velger du Alternativet regresjon .
- Klikk deretter OK .
Trinn 2: Sett inn inngangs- og utdataområde i regresjonsboksen
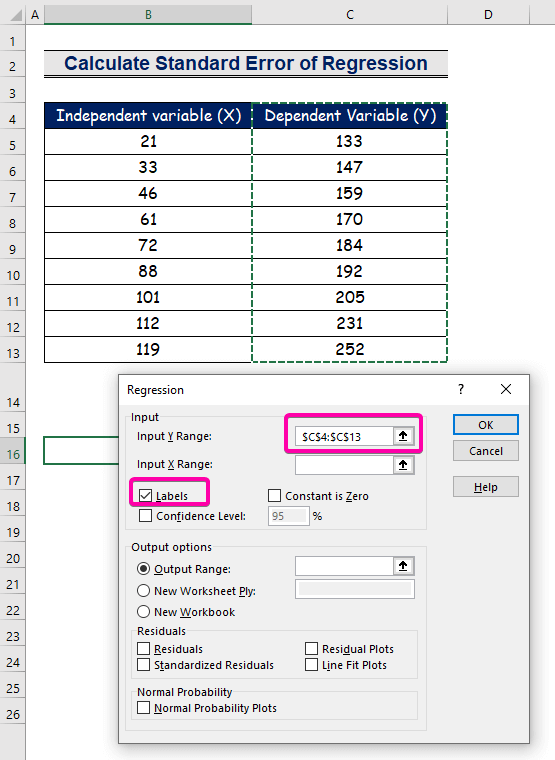
- For Y-inndataområdet , velg området C4:C13 med overskriften.
- Klikk på avmerkingsboksen Etiketter .
- Velg området B4:B13 for Input X Range .
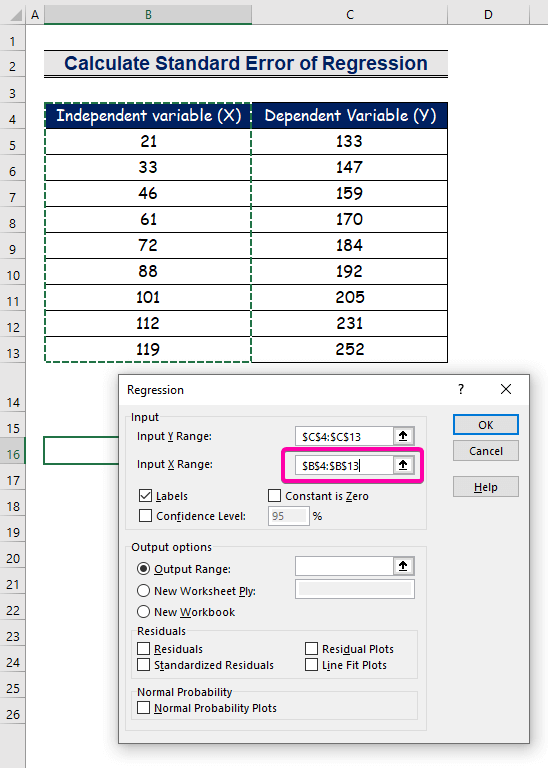
- For å få resultatet på den foretrukne plasseringen, velg en hvilken som helst celle ( B16 ) for utdataområdet .
- Til slutt klikker du OK .

Les mer: Hvordan beregne standardfeilproportion i Excel (med enkle trinn)
Trinn 3: Finn ut standardfeil
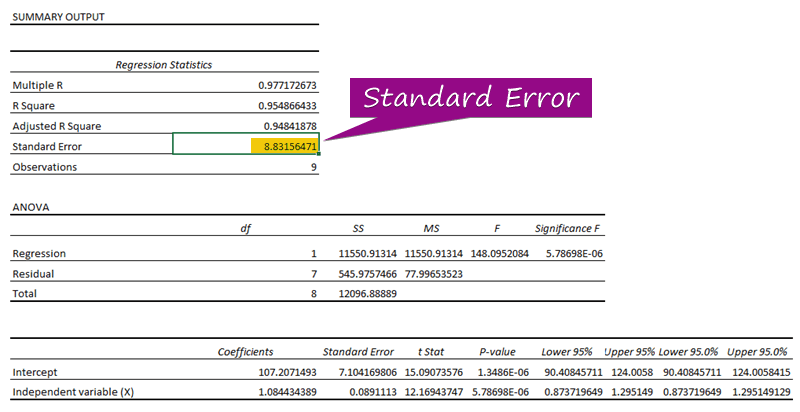
- Fra regresjonsanalysen kan du få ut verdien av standardfeilen ( 3156471 ).
Les mer: Hvordan finne gjenværende standardfeil i Excel (2 enkle metoder)
Trinn 4: Plott regresjonsmodelldiagram
- Klikk først på Sett inn fanen.
- Fra Charts -gruppen velger du Scatter -diagrammet.
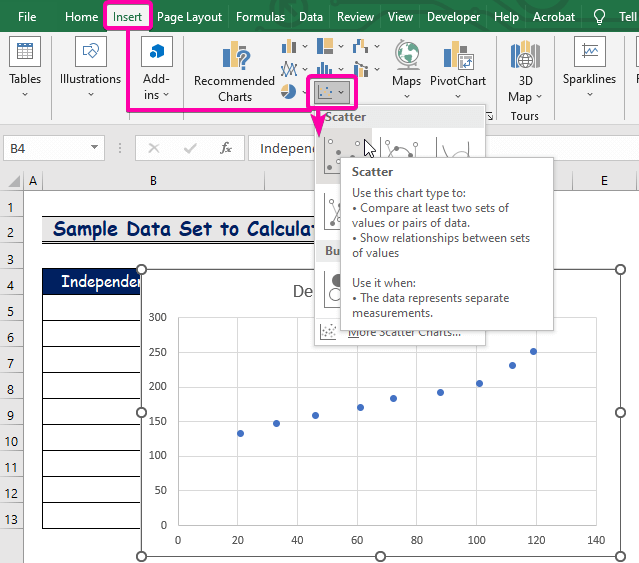
- Høyreklikk over en avpoeng.
- Velg alternativet Legg til trendlinje fra alternativene.
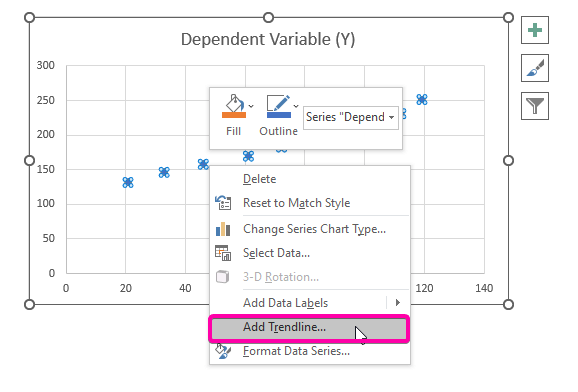
- Derfor, din regresjonsanalyse -diagrammet vil bli plottet som bildet vist nedenfor.

- For å vise regresjonsanalyse -ligning, klikk på Vis ligning på diagram -alternativet fra Format trendlinje.

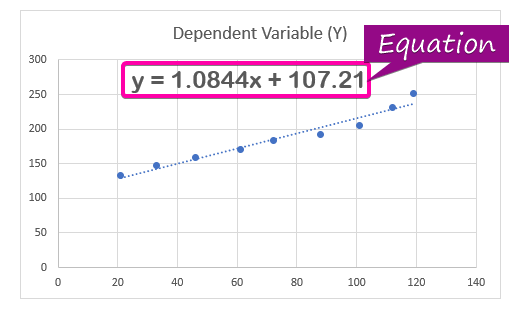
- Som et resultat, ligningen ( y = 1,0844x + 107,21 ) for regresjonsanalysen vises i diagrammet.
Merknader:
Du kan beregne forskjellen mellom de anslåtte verdiene og de faktiske verdier fra ligningen for regresjonsanalyse.
Trinn:
- Skriv inn formelen for å representere regresjonsanalyseligningen.
=1.0844*B5 + 107.21 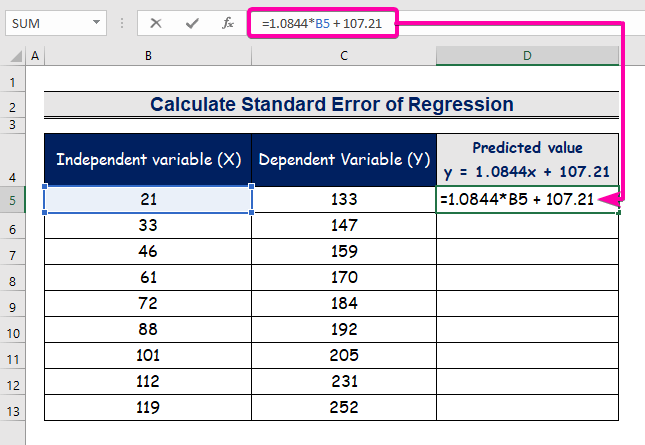
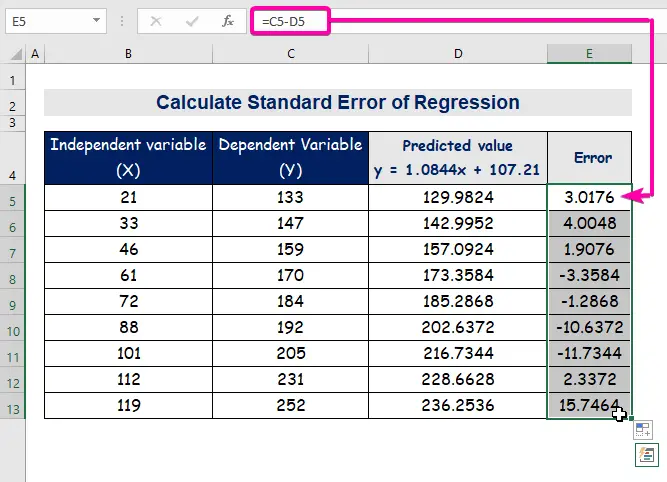
- Derfor vil du få den første anslåtte verdien ( 129.9824 ), som er forskjellig fra den faktiske verdien ( 133 ).

- Bruk Autofyllverktøy for å automatisk fylle ut kolonne D .

- For å beregne feilen, skriv inn følgende formel for å trekke fra.
=C5-D5 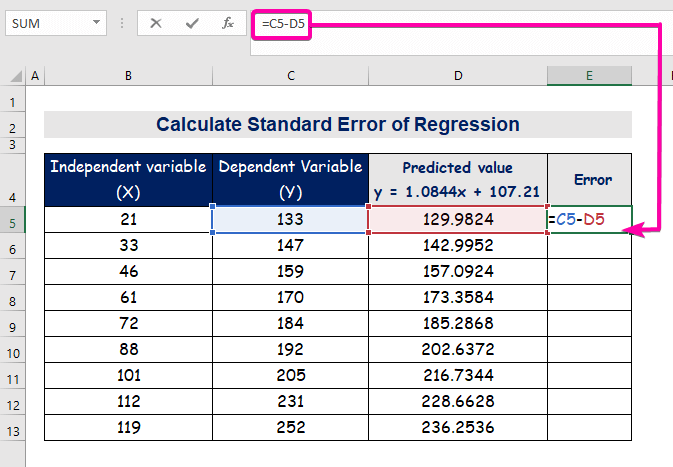
- Til slutt, autofyll kolonne E for å finne feilverdiene.
Les mer: Hvordan beregne standardfeil for regresjonshelling i Excel
Tolkningen av regresjonsanalyse i Excel
1. Standardfeil
Vi kan se fra regresjonsanalyseligningen at det alltid er en forskjell eller feil mellom de predikerte og faktiske verdiene. Som et resultat må vi beregne gjennomsnittsavviket til forskjellene.
En standardfeil representerer gjennomsnittsfeilen mellom den predikerte verdien og den faktiske verdien. Vi oppdaget 8.3156471 som standardfeil i vår eksempelregresjonsmodell. Det indikerer at det er en forskjell mellom de predikerte og faktiske verdiene, som kan være større enn standardfeilen ( 15.7464 ) eller mindre enn standardfeil ( 4.0048 ). Vår gjennomsnittlige feil vil imidlertid være 8.3156471 , som er standardfeilen .
Som et resultat er modellens mål å redusere standardfeilen. Jo lavere standardfeil, jo mer nøyaktig modellen.
2. Koeffisienter
Regresjonskoeffisienten evaluerer svar med ukjente verdier. I regresjonsligningen ( y = 1,0844x + 107,21 ), er 1,0844 koeffisienten , x er den prediktoruavhengige variabelen, 107.21 er konstanten, og y er responsverdien for x .
- En positiv koeffisient forutsier at jo høyere koeffisient, jo høyere responsvariabel. Det indikerer et proporsjonalt forhold.
- En negativ koeffisient forutsier at jo høyere koeffisient, desto lavere er responsverdiene. Det indikerer et uproporsjonalt forhold.
3. P-verdier
I regresjonsanalyse, p- verdier og koeffisienter samarbeider for å informere deg om korrelasjoner i modellen din er statistisk relevante og hvordan disse sammenhengene er. Nullhypotesen at den uavhengige variabelen ikke har noen kobling med den avhengige variabelen testes ved å bruke p-verdien for hver uavhengig variabel. Det er ingen sammenheng mellom endringer i den uavhengige variabelen og variasjoner i den avhengige variabelen hvis det ikke er noen korrelasjon.
- Dine prøvedata gir nok støtte til å falsifisere nullhypotesen for full populasjon hvis p-verdien for en variabel er mindre enn din signifikansgrense. Beviset ditt støtter forestillingen om en korrelasjon som ikke er null . På populasjonsnivå er endringer i den uavhengige variabelen knyttet til endringer i den avhengige variabelen.
- En p-verdi større en signifikansnivået, på hver side , antyder at utvalget ditt har ikke tilstrekkelig bevis til å fastslå at det eksisterer en korrelasjon som ikke er null .
Fordi deres p-verdier ( 5.787E-06 , 1.3E-06 ) er mindre enn signifikantverdien ( 5.787E-06 ), den uavhengige variabelen (X) og Intercept er statistisk signifikante , som vist i eksempelet på regresjonsutdata.
4. R-kvadrerte verdier
For lineære regresjonsmodeller er R-kvadrat en fullstendighetsmåling . Dette forholdet viser prosenten av variansen i den avhengige variabelen som de uavhengige faktorene tar hensyn til når de tas sammen. På en praktisk 0–100 prosentskala kvantifiserer R-kvadrat styrken til forbindelsen mellom modellen og den avhengige variabelen.
Verdien R2 er et mål på hvor godt regresjonsmodellen passer til dataene dine. Jo høyere tallet er, jo bedre er modellen.
Konklusjon
Jeg håper denne artikkelen har gitt deg en veiledning om hvordan du beregner standardfeilen for regresjon i Excel . Alle disse prosedyrene bør læres og brukes på datasettet. Ta en titt på øvelsesarbeidsboken og test disse ferdighetene. Vi er motiverte til å fortsette å lage opplæringsprogrammer som dette på grunn av din verdifulle støtte.
Kontakt oss hvis du har spørsmål. Legg også gjerne igjen kommentarer i seksjonen nedenfor.
Vi, Exceldemy -teamet, er alltid lydhøre for spørsmålene dine.
Bli hos oss og fortsett å lære.
