
목차
분산은 통계에서 가장 유용한 주제 중 하나입니다. 데이터가 평균 주위에 어떻게 분포되어 있는지 측정합니다. 모든 데이터를 보고 분포를 계산합니다. 이 기사에서는 Excel에서 샘플 분산을 계산하는 2가지 방법을 배웁니다.
실습 워크북 다운로드
이 기사를 준비하는 데 사용한 다음 실습 워크북을 다운로드할 수 있습니다.
샘플 분산이란?
일반적으로 분산은 평균 차이의 제곱을 모집단 수로 나누어 계산합니다. 샘플 분산에서 샘플은 모집단에서 선택한 샘플 수입니다.
예를 들어 미국인의 키를 측정하려는 경우 실용적이지 않습니다(금전적 또는 시간적 측면에서). 기준점) 미국 인구에서 각 사람의 키를 계산할 수 있습니다.
이 경우 1000명과 같은 인구의 표본을 추출하고 이 표본 크기를 사용하여 키를 계산해야 합니다. 전체 인구의. 샘플 분산은 키의 분산을 찾는 데 도움이 됩니다.
Excel에서 샘플 분산을 계산하는 2가지 방법
1. 기본 수학 공식을 적용하여 샘플 분산 계산
The 표본 분산에 대한 교과서 공식은 다음과 같이 주어진다.
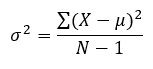
여기서
- μ 은 산술평균
- X 은 개별 값
- N 은 모집단의 크기
- σ 2 은 표본분산이다.
5개 데이터(개별값, X )의 표본분산을 계산하고자 한다. 평균 (X-μ) 에 대한 편차와 평균 (X-μ)^2 에 대한 편차의 제곱에 대한 2개의 열이 있습니다. 이제 아래 단계를 따르십시오. .
📌 단계:
- 먼저 총 데이터 수를 결정합니다(이 예에서는 N=5. <13)>
- 이제 개별 값에 대한 산술 평균을 계산하려면 다음 공식을 사용하십시오.
=AVERAGE(C5:C9) 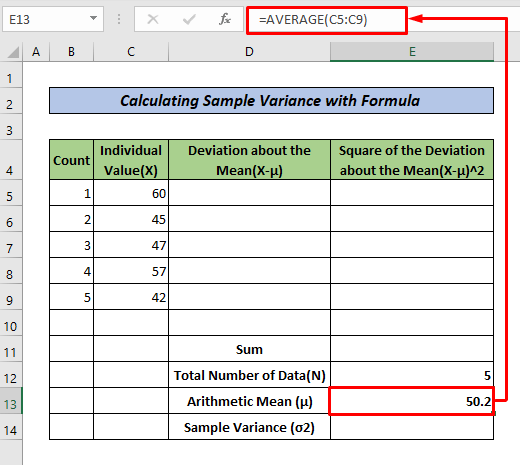
- 셀 D5, 의 평균 (X-μ), 에 대한 편차를 얻으려면 다음 수식을 입력한 다음 ENTER, 키를 누릅니다. 채우기 핸들을 D9.
=C5-$E$13 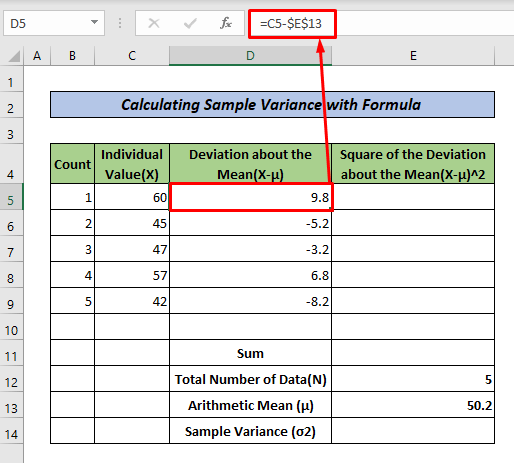
- 으로 드래그합니다. 셀 E5, 의 평균 (X-μ)^2, 에 대한 편차의 제곱 다음 수식을 복사하고 ENTER, 를 누르고 채우기 나머지 셀을 처리합니다.
=D5^2 
- 편차의 제곱합을 계산하려면 평균 (X-μ)^2, 에 대해 셀 E11,
=SUM(E5:E9) 에 다음 공식을 사용합니다. 
- 마지막으로 t를 얻으려면 그는 평균 (X-μ)^2 에 대한 편차의 제곱의 합을 (N-1) 으로 나누고 다음 공식을셀 E14.
=E11/(E12-1) 결과는 다음과 같습니다.

자세히 보기: 엑셀에서 평균분산 및 표준편차 계산하는 방법
2. 엑셀 VAR.S 함수 활용
계산을 위해 Excel에서 샘플 분산을 사용하려면 기본 제공 함수 VAR.S 를 사용합니다. 이 기능을 적용하려면 아래 단계를 따르십시오.
📌 단계:
- 먼저 데이터세트에서 셀을 선택합니다(이 예에서는 , C11) 여기서 Sample Variance 값을 입력합니다. 그런 다음 이 셀에 다음 수식을 입력하고 마지막으로 Enter를 누릅니다.
=VAR.S(C5:C9) 결과는 다음과 같습니다.

자세히 보기: 엑셀에서 분산을 계산하는 방법(쉬운 안내서)
결론
이 자습서에서는 Excel에서 샘플 분산을 계산하는 두 가지 방법에 대해 설명했습니다. 이 기사가 도움이 되었기를 바랍니다. 저희 웹사이트 ExcelWIKI 를 방문하시면 더 많은 엑셀 관련 내용을 보실 수 있습니다. 아래 댓글 섹션에 의견, 제안 또는 질문이 있으면 남겨주세요.
