
সুচিপত্র
আপনি যদি এক্সেলের রৈখিক রিগ্রেশন এ P-মান বা সম্ভাব্যতার মান গণনা করার উপায় খুঁজছেন, তাহলে আপনি সঠিক জায়গায় আছেন। P-মান কাল্পনিক পরীক্ষার ফলাফলের সম্ভাব্যতা নির্ধারণ করতে ব্যবহৃত হয়। আমরা 2টি অনুমানের উপর ভিত্তি করে ফলাফল বিশ্লেষণ করতে পারি; শূন্য হাইপোথিসিস এবং বিকল্প অনুমান । P-মান ব্যবহার করে আমরা নির্ধারণ করতে পারি যে ফলাফলটি নাল হাইপোথিসিস বা বিকল্প হাইপোথিসিসকে সমর্থন করে।
তাই, মূল নিবন্ধ দিয়ে শুরু করা যাক।
ওয়ার্কবুক ডাউনলোড করুন
P value.xlsx
এক্সেলের লিনিয়ার রিগ্রেশনে পি মান গণনা করার 3 উপায়
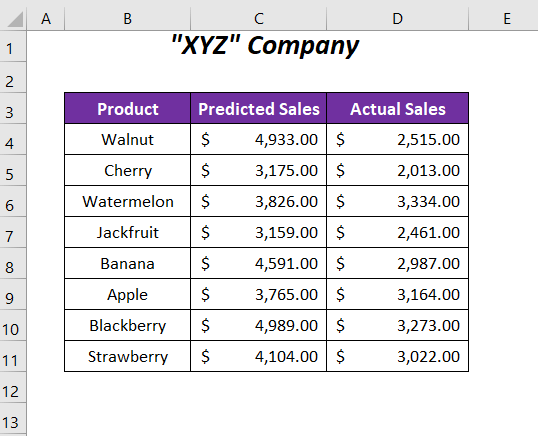
এখানে, আমাদের কাছে কিছু পূর্বাভাসিত বিক্রয় মান রয়েছে এবং একটি কোম্পানির কিছু পণ্যের প্রকৃত বিক্রয় মান। আমরা এই বিক্রয় মানগুলি তুলনা করব এবং সম্ভাব্যতার মান নির্ধারণ করব এবং তারপরে আমরা নির্ধারণ করব যে P নাল হাইপোথিসিস বা বিকল্প হাইপোথিসিস সমর্থন করে কিনা। নাল হাইপোথিসিস মনে করে যে দুটি ধরণের বিক্রয় মানের মধ্যে কোন পার্থক্য নেই এবং বিকল্প অনুমান এই দুটি মানের সেটের মধ্যে পার্থক্য বিবেচনা করবে৷
আমরা ব্যবহার করেছি Microsoft Office 365 সংস্করণ এখানে, আপনি আপনার সুবিধা অনুযায়ী অন্য যেকোনো সংস্করণ ব্যবহার করতে পারেন।
পদ্ধতি-1: পি মান গণনা করতে 't-টেস্ট বিশ্লেষণ টুল' ব্যবহার করে
এখানে, আমরা P-মান নির্ধারণ করতে টি-টেস্ট বিশ্লেষণ টুল ধারণকারী বিশ্লেষণ টুলপ্যাক ব্যবহার করব বিক্রয় ডেটার এই দুটি সেটের জন্য।

পদক্ষেপ :
আপনি যদি ডেটা বিশ্লেষণ টুল সক্রিয় না করে থাকেন তারপর প্রথমে প্রথমে এই টুলপ্যাকটি সক্রিয় করুন।
➤ ফাইল ট্যাবে ক্লিক করুন।

➤ বিকল্পগুলি<2 নির্বাচন করুন।>.

এর পর, Excel অপশন ডায়ালগ বক্স আসবে।
➤ অ্যাড-ইনস <নির্বাচন করুন। 2>বাম প্যানেলে বিকল্প।
➤ এক্সেল অ্যাড-ইনস বিকল্পটি বেছে নিন ম্যানেজ বক্সে এবং তারপরে টিপুন যান ।
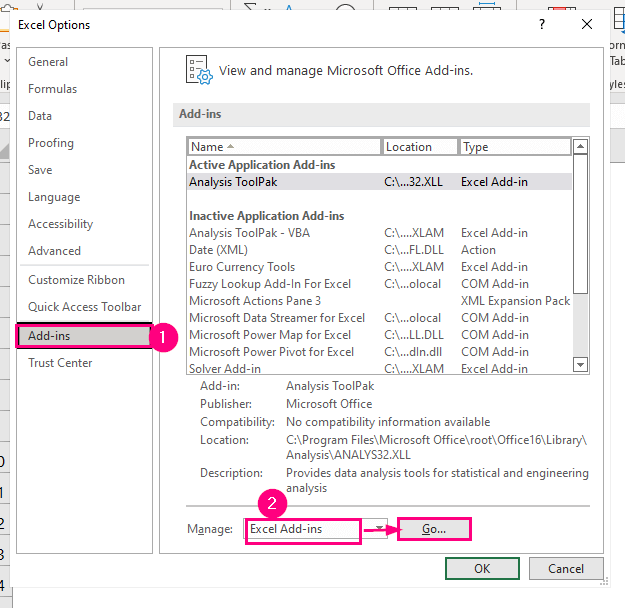
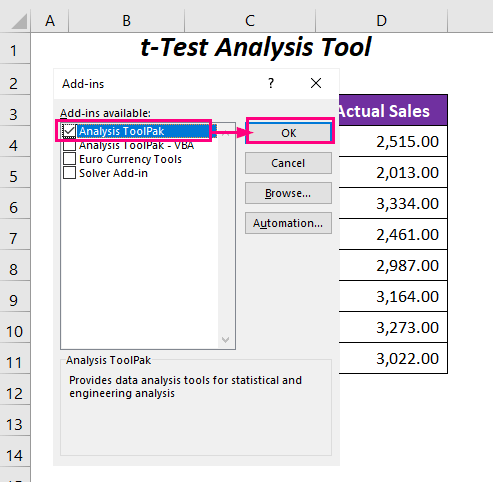
পরে, অ্যাড-ইনস ডায়ালগ বক্স পপ আপ হবে।
➤ চেক করুন বিশ্লেষণ টুলপ্যাক বিকল্প এবং ঠিক আছে টিপুন।
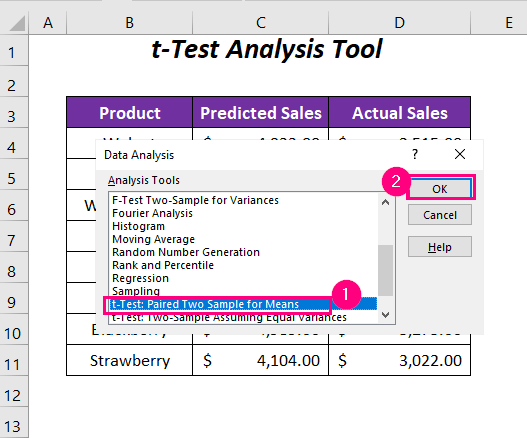
➤ এখন, ডেটা ট্যাবে যান >> বিশ্লেষণ গ্রুপ >> ডেটা বিশ্লেষণ বিকল্প।
18>
তারপর, ডেটা বিশ্লেষণ উইজার্ড প্রদর্শিত হবে .
➤ বিকল্পটি নির্বাচন করুন টি-পরীক্ষা: অর্থের জন্য জোড়া দুটি নমুনা বিশ্লেষণ সরঞ্জাম এর বিভিন্ন বিকল্প থেকে।
এর পর, t-Test: Paired Two Sample for Means ডায়ালগ বক্স খুলবে।
➤ যেমন ইনপুট আমাদের দুটি পরিবর্তনশীল রেঞ্জ প্রদান করতে হবে; $C$4:$C$11 এর জন্য ভেরিয়েবল 1 রেঞ্জ এবং $D$4:$D$11 এর জন্য ভেরিয়েবল 2 রেঞ্জ , হিসাবে আউটপুট রেঞ্জ আমরা $E$4 নির্বাচন করেছি।
➤ আপনি থেকে আলফা এর মান পরিবর্তন করতে পারেন 0.05 (স্বয়ংক্রিয়ভাবে তৈরি) থেকে 0.01 কারণ এই ধ্রুবকের জন্য নির্ধারিত মান সাধারণত 0.05 বা 0.01 ।
➤অবশেষে, ঠিক আছে টিপুন।

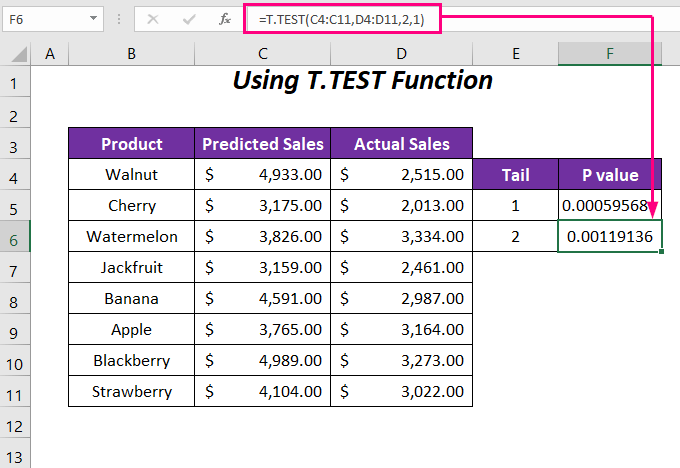
এর পরে, আপনি দুটি ক্ষেত্রে P-মান পাবেন; এক-টেইল মান হল 0.00059568 এবং টু-টেইল মান হল 0.0011913 । আমরা দেখতে পাচ্ছি এক-টেইল P-মান টু-টেইলের অর্ধেক P-মান । কারণ দুই-টেইল P-মান চিহ্নের বৃদ্ধি এবং হ্রাস উভয়কেই বিবেচনা করে যেখানে এক-টেইল P-মান এই ক্ষেত্রেগুলির মধ্যে একটিকে বিবেচনা করে।
আরও, আমরা দেখতে পাচ্ছি যে 0.05 এর আলফা মানের জন্য আমরা P মান 0.05 এর চেয়ে কম পাচ্ছি যার মানে এটি শূন্য অনুমানকে অবহেলা করে এবং তাই ডেটা অত্যন্ত তাৎপর্যপূর্ণ৷

আরো পড়ুন: এক্সেলে লিনিয়ার রিগ্রেশন ফলাফল কীভাবে ব্যাখ্যা করবেন (সহজ পদক্ষেপ সহ)
পদ্ধতি-2: এক্সেলের লিনিয়ার রিগ্রেশনে P মান গণনা করতে T.TEST ফাংশন ব্যবহার করে
এই বিভাগে, আমরা T.TEST ফাংশন<ব্যবহার করব 2> লেজের P মান নির্ধারণ করতে 1 এবং 2 ।
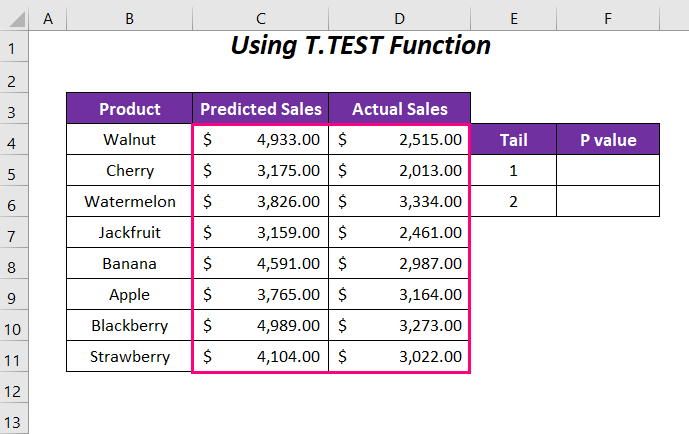
পদক্ষেপ :
আমরা টেলের P-মান নির্ধারণ করে শুরু করব 1 অথবা এক দিকে।
➤ কক্ষে নিম্নলিখিত সূত্রটি টাইপ করুন F5 ।
=T.TEST(C4:C11,D4 :D11,1,1)এখানে, C4:C11 পরিসীমা হল আনুমানিক বিক্রয় , D4:D11 এটি হল প্রকৃত বিক্রয়ের পরিসর , 1 টেইল মান এবং শেষ 1 হলো পেয়ার করা টাইপ।
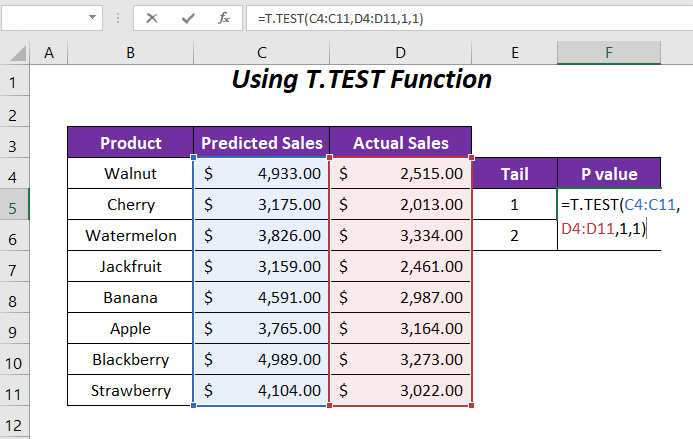
ENTER চাপার পর, আমরা P-মান 0.00059568 পাচ্ছি। টেলের জন্য 1 ।

➤ নিচের সূত্রটি কক্ষে প্রয়োগ করুন F6 নির্ধারণ করতে পি-মান টেলের জন্য 2 অথবা উভয় দিকেই।
=T.TEST(C4:C11,D4:D11,2,1) এখানে, C4: C11 হল আনুমানিক বিক্রয়ের পরিসর , D4:D11 হল প্রকৃত বিক্রয়ের পরিসর , 2 টেইল মান এবং শেষ 1 টি পেয়ার করা টাইপের জন্য।
আরো পড়ুন: এক্সেল ডেটা সেটে একাধিক রৈখিক রিগ্রেশন (2 পদ্ধতি)
পদ্ধতি-3: CORREL, T.DIST.2T ফাংশন ব্যবহার করে লিনিয়ার রিগ্রেশনে P মান গণনা করতে
আমরা এখানে CORREL , T.DIST.2T ব্যবহার করে পারস্পরিক সম্পর্কের জন্য P-মান নির্ধারণ করব। ফাংশন।
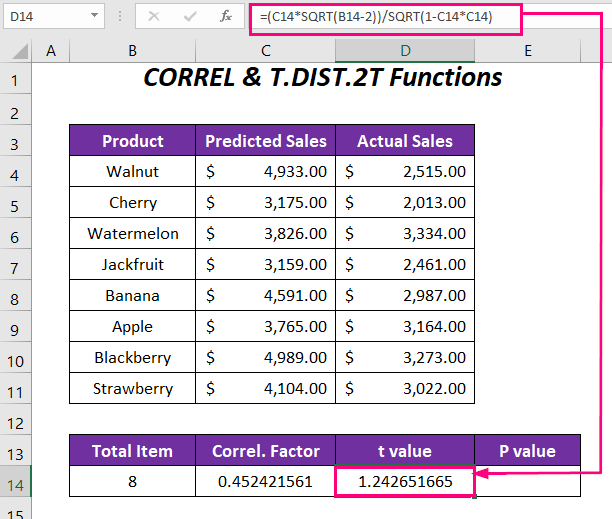
এটি করার জন্য আমরা হেডার মোট আইটেম , করেল সহ কিছু কলাম তৈরি করেছি। ফ্যাক্টর , t মান , এবং P মান এবং আমরা মোট আইটেমগুলির জন্যও মান প্রবেশ করিয়েছি যা 8 | সেলে C14 ।
=CORREL(C4:C11,D4:D11) এখানে, C4:C11 এর পরিসর হল পূর্বাভাসিত বিক্রয় , এবং D4:D11 হল প্রকৃত বিক্রয় এর পরিসর।

➤ t মান নির্ধারণ করতে ঘরে নিচের সূত্রটি টাইপ করুন D14 ।
=(C14*SQRT(B14-2))/SQRT(1-C14*C14) এখানে, C14 পারস্পরিক সম্পর্ক ফ্যাক্টর, এবং B14 হলো পণ্যের মোট সংখ্যা।
- SQRT(B14-2) হবে
SQRT(8-2) → SQRT(6 ) 6 এর বর্গমূল দেয়।
আউটপুট → 2.4494897
- C14*SQRT(B14-2) হয়ে যায়
0.452421561*2.4494897
আউটপুট → 1.10820197
1-0.452421561*0.452421561
আউটপুট → 0.79531473
<30- SQRT(1-C14*C14) হয়ে যায়
SQRT(0.79531473) → 0.79531473<2 এর বর্গমূল দেখায়>.
আউটপুট → 0.891804199
- (C14*SQRT(B14-2))/SQRT(1-C14*C14) হয়ে যায়
(1.10820197)/0.891804199
আউটপুট → 1.242651665
➤ অবশেষে, নিম্নলিখিত ফাংশনটি ব্যবহার করে আমরা পারস্পরিক সম্পর্কের জন্য P-মান নির্ধারণ করব।
=T.DIST.2T(D14,B14-2) এখানে, D14 হলো টি মান , B14-2 বা 8-2 বা 6 হলো স্বাধীনতা ডিগ্রী এবং T.DIST.2T টু-টেইল্ড ডিস্ট্রিবিউশনের সাথে পারস্পরিক সম্পর্কের জন্য P-মান রিটার্ন করবে।

আরো পড়ুন: এক্সেল এ মাল্টিপল রিগ্রেশন এনালাইসিস কিভাবে করবেন (সহজ ধাপ সহ)
মনে রাখার মত বিষয়
⦿ সাধারণত, আমরা দুটি সাধারণ ব্যবহার করি আলফা মান; 0.05 এবং 0.01 ।
⦿ দুটি হাইপোথিসিস আছে, নাল হাইপোথিসিস এবং বিকল্প হাইপোথিসিস,নাল হাইপোথিসিস দুটি ডেটা সেটের মধ্যে কোনো পার্থক্য বিবেচনা করে না এবং অন্যটি ডেটার দুটি সেটের মধ্যে পার্থক্য বিবেচনা করে।
⦿ যখন P-মান এর কম হয় 0.05 এটি নাল হাইপোথিসিসকে অস্বীকার করে এবং 0.05 এর চেয়ে বেশি মানের জন্য এটি নাল হাইপোথিসিসকে সমর্থন করে। P-মান মূল্যায়ন করে আমরা নিম্নলিখিত সিদ্ধান্তে আসতে পারি।
P<0.05 → অত্যন্ত গুরুত্বপূর্ণ ডেটাP =0.05 → উল্লেখযোগ্য ডেটা
P=0.05-0.1 → প্রান্তিকভাবে উল্লেখযোগ্য ডেটা
P>0.1 → তুচ্ছ ডেটা
অনুশীলন বিভাগ
নিজে অনুশীলন করার জন্য আমরা অভ্যাস নামের একটি শিটে নীচের মত একটি অনুশীলন বিভাগ প্রদান করেছি। অনুগ্রহ করে এটি নিজে করুন৷
উপসংহার
এই নিবন্ধে, আমরা পি-মান এ গণনা করার উপায়গুলি কভার করার চেষ্টা করেছি Excel এ লিনিয়ার রিগ্রেশন। আশা করি এটি আপনার কাজে লাগবে। যদি আপনার কোন পরামর্শ বা প্রশ্ন থাকে, তাহলে মন্তব্য বিভাগে সেগুলি শেয়ার করুন৷
৷