
સામગ્રીઓનું કોષ્ટક
જો તમે Excel માં P-વેલ્યુ અથવા રેખીય રીગ્રેસન, માં સંભાવના મૂલ્યની ગણતરી કરવાની રીતો શોધી રહ્યાં છો, તો તમે યોગ્ય સ્થાને છો. P-વેલ્યુ નો ઉપયોગ અનુમાનિત પરીક્ષણોના પરિણામોની સંભાવના નક્કી કરવા માટે થાય છે. અમે 2 પૂર્વધારણાઓના આધારે પરિણામોનું વિશ્લેષણ કરી શકીએ છીએ; નલ પૂર્વધારણા અને વૈકલ્પિક પૂર્વધારણા . P-મૂલ્ય નો ઉપયોગ કરીને અમે નક્કી કરી શકીએ છીએ કે પરિણામ નલ પૂર્વધારણા અથવા વૈકલ્પિક પૂર્વધારણાને સમર્થન આપે છે કે કેમ.
તો, ચાલો મુખ્ય લેખ સાથે પ્રારંભ કરીએ.
વર્કબુક ડાઉનલોડ કરો
P value.xlsx
એક્સેલમાં લીનિયર રીગ્રેશનમાં P મૂલ્યની ગણતરી કરવાની 3 રીતો
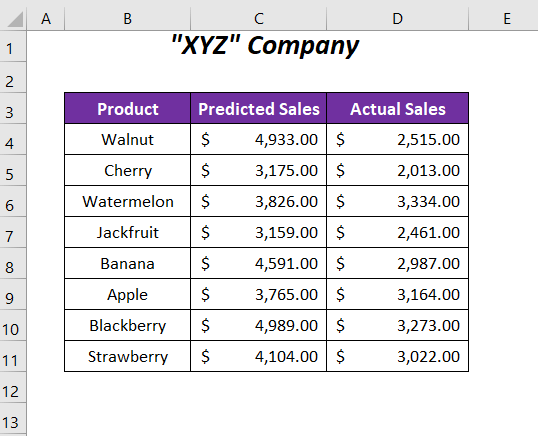
અહીં, અમારી પાસે કેટલાક અનુમાનિત વેચાણ મૂલ્યો છે અને કંપનીના કેટલાક ઉત્પાદનોના વાસ્તવિક વેચાણ મૂલ્યો. અમે આ વેચાણ મૂલ્યોની તુલના કરીશું અને સંભાવના મૂલ્ય નક્કી કરીશું અને પછી અમે નિર્ધારિત કરીશું કે શું P નલ પૂર્વધારણા અથવા વૈકલ્પિક પૂર્વધારણાને સમર્થન આપે છે. શૂન્ય પૂર્વધારણા માને છે કે બે પ્રકારના વેચાણ મૂલ્યો વચ્ચે કોઈ તફાવત નથી અને વૈકલ્પિક પૂર્વધારણા આ બે મૂલ્યોના સેટ વચ્ચેના તફાવતને ધ્યાનમાં લેશે.
અમે નો ઉપયોગ કર્યો છે. માઈક્રોસોફ્ટ ઓફિસ 365 વર્ઝન અહીં, તમે તમારી અનુકૂળતા અનુસાર કોઈપણ અન્ય વર્ઝનનો ઉપયોગ કરી શકો છો.
પદ્ધતિ-1: પી વેલ્યુની ગણતરી કરવા માટે 'ટી-ટેસ્ટ એનાલિસિસ ટૂલ'નો ઉપયોગ કરીને
અહીં, અમે P-મૂલ્ય નક્કી કરવા માટે ટી-ટેસ્ટ વિશ્લેષણ સાધન ધરાવતા વિશ્લેષણ ટૂલપેકનો ઉપયોગ કરીશું સેલ્સ ડેટાના આ બે સેટ માટે.

પગલાઓ :
જો તમે ડેટા વિશ્લેષણ સાધન સક્રિય ન કર્યું હોય પછી સૌથી પહેલા આ ટૂલપેકને સક્ષમ કરો.
➤ ફાઈલ ટેબ પર ક્લિક કરો.

➤ વિકલ્પો<2 પસંદ કરો>.

તે પછી, Excel વિકલ્પો સંવાદ બોક્સ દેખાશે.
➤ એડ-ઇન્સ <પસંદ કરો 2>ડાબી પેનલ પર વિકલ્પ.
➤ મેનેજ કરો બોક્સમાં Excel Add-ins વિકલ્પ પસંદ કરો અને પછી દબાવો જાઓ .
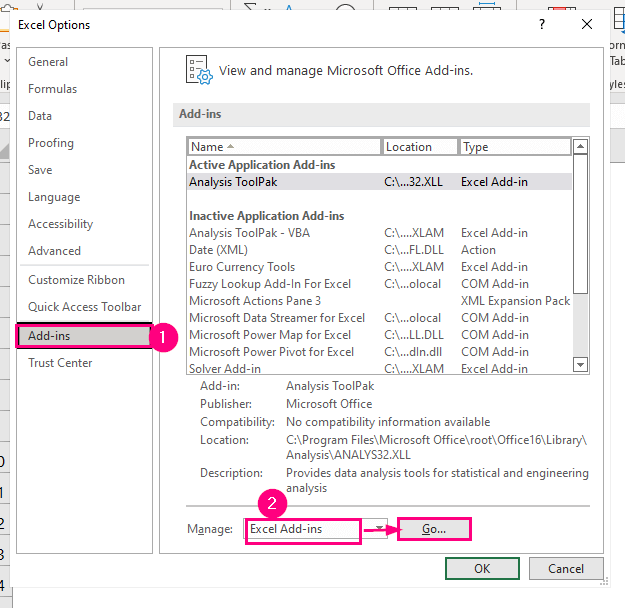
ત્યારબાદ, એડ-ઇન્સ સંવાદ બોક્સ પોપ અપ થશે.
➤ તપાસો વિશ્લેષણ ToolPak વિકલ્પ અને ઓકે દબાવો.
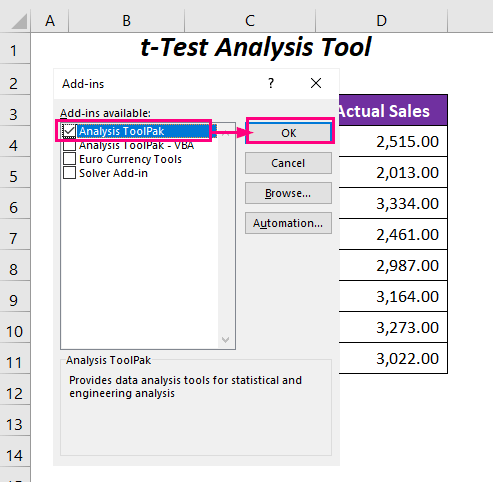
➤ હવે, ડેટા ટેબ >><પર જાઓ. 1>વિશ્લેષણ જૂથ >> ડેટા વિશ્લેષણ વિકલ્પ.

પછી, ડેટા વિશ્લેષણ વિઝાર્ડ દેખાશે .
➤ વિશ્લેષણ સાધનો ના વિવિધ વિકલ્પોમાંથી ટી-ટેસ્ટ: માધ્યમ માટે જોડી કરેલ બે નમૂના વિકલ્પ પસંદ કરો.
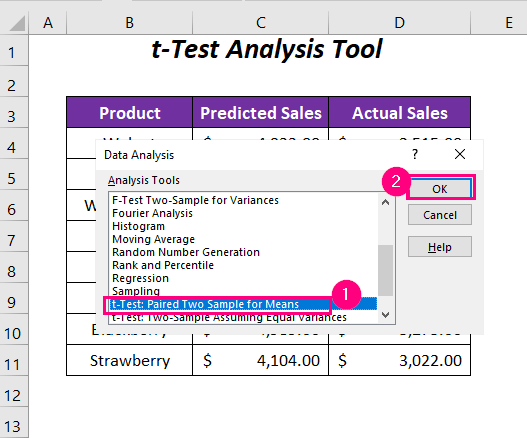
તે પછી, ટી-ટેસ્ટ: પેયર ટુ સેમ્પલ ફોર મીન્સ સંવાદ બોક્સ ખુલશે.
➤ જેમ ઇનપુટ આપણે બે વેરીએબલ રેન્જ પ્રદાન કરવી પડશે; ચલ 1 શ્રેણી અને $D$4:$D$11 માટે ચલ 2 શ્રેણી માટે $C$4:$C$11 , <તરીકે 1>આઉટપુટ રેન્જ અમે $E$4 પસંદ કર્યું છે.
➤ તમે માંથી આલ્ફા ની કિંમત બદલી શકો છો 0.05 (આપમેળે જનરેટ) થી 0.01 કારણ કે આ સ્થિરાંક માટે નિયુક્ત મૂલ્ય સામાન્ય રીતે 0.05 અથવા 0.01 છે.
➤છેલ્લે, ઓકે દબાવો.

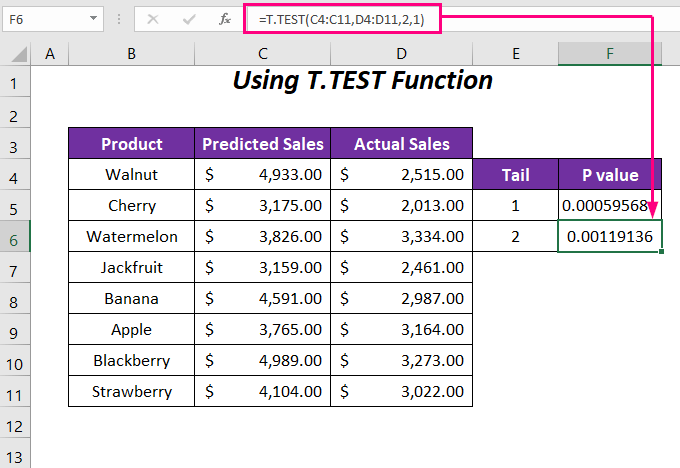
તે પછી, તમને બે કેસ માટે P-વેલ્યુ મળશે; એક પૂંછડીનું મૂલ્ય 0.00059568 છે અને બે પૂંછડીનું મૂલ્ય 0.0011913 છે. આપણે એક-પૂંછડી P-મૂલ્ય બે-પૂંછડી P-મૂલ્ય ના અડધા ગણા છે તે જોઈ શકીએ છીએ. કારણ કે દ્વિ-પૂંછડી P-મૂલ્ય માર્કના વધારો અને ઘટાડા બંનેને ધ્યાનમાં લે છે જ્યારે એક-પૂંછડી P-મૂલ્ય આમાંથી ફક્ત એક જ કેસને ધ્યાનમાં લે છે.
વધુમાં, આપણે જોઈ શકીએ છીએ કે 0.05 ના આલ્ફા મૂલ્ય માટે અમને P 0.05 કરતા ઓછા મૂલ્યો મળી રહ્યા છે, જેનો અર્થ છે કે તે નલ પૂર્વધારણાની અવગણના કરે છે અને તેથી ડેટા ખૂબ જ મહત્વપૂર્ણ છે.

વધુ વાંચો: એક્સેલમાં લીનિયર રીગ્રેશન પરિણામોનું અર્થઘટન કેવી રીતે કરવું (સરળ પગલાં સાથે)
પદ્ધતિ-2: એક્સેલમાં લીનિયર રીગ્રેશનમાં P મૂલ્યની ગણતરી કરવા માટે T.TEST ફંક્શનનો ઉપયોગ કરીને
આ વિભાગમાં, અમે T.TEST ફંક્શનનો ઉપયોગ કરીશું. 2> પૂંછડીઓ 1 અને 2 માટે P મૂલ્યો નક્કી કરવા.
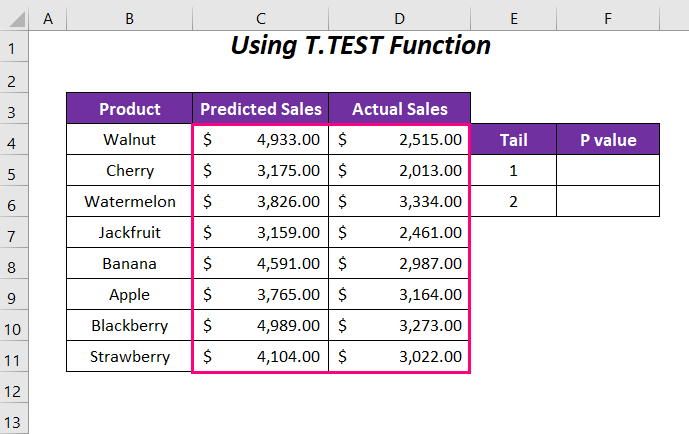
પગલાઓ :
અમે પૂંછડી 1 <માટે P-મૂલ્ય નિર્ધારિત કરવા સાથે પ્રારંભ કરીશું 2> અથવા એક દિશામાં.
➤ સેલ F5 માં નીચેનું સૂત્ર ટાઈપ કરો.
=T.TEST(C4:C11,D4 :D11,1,1)અહીં, C4:C11 એ અનુમાનિત વેચાણ ની શ્રેણી છે, D4:D11 એ વાસ્તવિક વેચાણ ની શ્રેણી છે, 1 પૂંછડીની કિંમત છે અને છેલ્લું 1 છે જોડી માટે પ્રકાર.
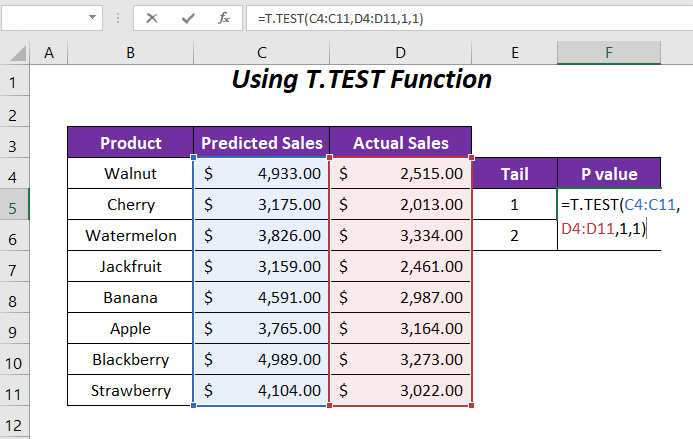
ENTER દબાવ્યા પછી, અમને P-વેલ્યુ 0.00059568 મળશે. પૂંછડી માટે 1 .

➤ નક્કી કરવા માટે નીચેના સૂત્રને કોષમાં લાગુ કરો F6 પૂંછડી 2 અથવા બંને દિશામાં માટે P-મૂલ્ય .
=T.TEST(C4:C11,D4:D11,2,1) અહીં, C4: C11 એ અનુમાનિત વેચાણ ની શ્રેણી છે, D4:D11 એ વાસ્તવિક વેચાણ ની શ્રેણી છે , 2 પૂંછડીની કિંમત છે અને છેલ્લું 1 જોડી પ્રકાર માટે છે.
વધુ વાંચો: એક્સેલ ડેટા સેટ્સ પર મલ્ટીપલ લીનિયર રીગ્રેસન (2 પદ્ધતિઓ)
પદ્ધતિ-3: CORREL, T.DIST.2T કાર્યોનો ઉપયોગ કરવો લીનિયર રીગ્રેશનમાં P મૂલ્યની ગણતરી કરવા માટે
અમે અહીં CORREL , T.DIST.2T નો ઉપયોગ કરીને સહસંબંધ માટે P-મૂલ્ય નિર્ધારિત કરીશું. ફંક્શન્સ.
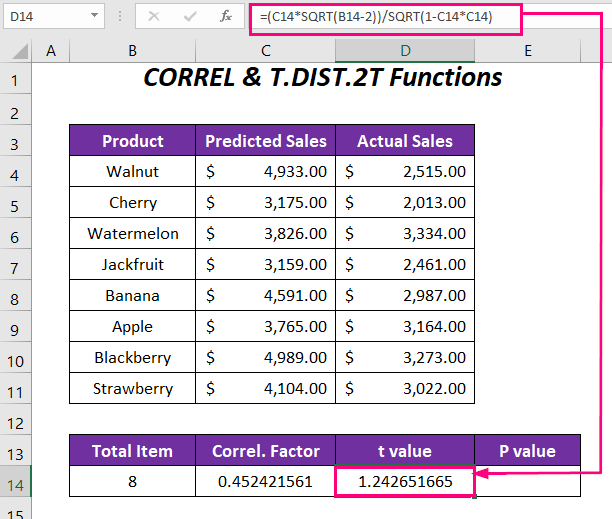
આ કરવા માટે અમે હેડરો કુલ આઇટમ , કોરલ સાથે કેટલીક કૉલમ બનાવી છે. પરિબળ , t મૂલ્ય , અને P મૂલ્ય અને અમે કુલ આઇટમ્સ માટે પણ મૂલ્ય દાખલ કર્યું છે જે 8 છે. | કોષમાં C14 .
=CORREL(C4:C11,D4:D11) અહીં, C4:C11 ની શ્રેણી છે અનુમાનિત વેચાણ , અને D4:D11 એ વાસ્તવિક વેચાણ ની શ્રેણી છે.

➤ t મૂલ્ય નિર્ધારિત કરવા માટે કોષમાં નીચેનું સૂત્ર લખો D14 .
=(C14*SQRT(B14-2))/SQRT(1-C14*C14) અહીં, C14 સંબંધ પરિબળ છે, અને B14 છે ઉત્પાદનોની કુલ સંખ્યા.
- SQRT(B14-2) બનાય છે
SQRT(8-2) → SQRT(6 ) 6 નું વર્ગમૂળ આપે છે.
આઉટપુટ → 2.4494897
- C14*SQRT(B14-2) બનાય છે
0.452421561*2.4494897
આઉટપુટ → 1.10820197
1-0.452421561*0.452421561
આઉટપુટ → 0.79531473
<30- SQRT(1-C14*C14) બનાય છે
SQRT(0.79531473) → 0.79531473<2 નું વર્ગમૂળ પરત કરે છે>.
આઉટપુટ → 0.891804199
- (C14*SQRT(B14-2))/SQRT(1-C14*C14) બનાય છે
(1.10820197)/0.891804199
આઉટપુટ → 1.242651665
➤ અંતે, નીચેના ફંક્શનનો ઉપયોગ કરીને આપણે સહસંબંધ માટે P-મૂલ્ય નિર્ધારિત કરીશું.
=T.DIST.2T(D14,B14-2) અહીં, D14 એ t મૂલ્ય , B14-2 અથવા 8-2 અથવા 6 છે સ્વતંત્રતાની ડિગ્રી અને T.DIST.2T દ્વિ-પુચ્છીય વિતરણ સાથે સહસંબંધ માટે P-મૂલ્ય પાછું આપશે.

વધુ વાંચો: એક્સેલમાં મલ્ટિપલ રીગ્રેશન એનાલિસિસ કેવી રીતે કરવું (સરળ પગલાંઓ સાથે)
યાદ રાખવા જેવી બાબતો
⦿ સામાન્ય રીતે, અમે બે સામાન્ય નો ઉપયોગ કરીએ છીએ આલ્ફા મૂલ્યો; 0.05 અને 0.01 .
⦿ બે પૂર્વધારણાઓ છે, નલ પૂર્વધારણા અને વૈકલ્પિક પૂર્વધારણા,નલ પૂર્વધારણા ડેટાના બે સેટ વચ્ચેના તફાવતને ધ્યાનમાં લેતી નથી અને અન્ય ડેટાના બે સેટ વચ્ચેના તફાવતને ધ્યાનમાં લે છે.
⦿ જ્યારે P-મૂલ્ય કરતાં ઓછું હોય ત્યારે 0.05 તે નલ પૂર્વધારણાને નકારે છે અને 0.05 કરતાં વધુ મૂલ્યો માટે તે નલ પૂર્વધારણાને સમર્થન આપે છે. P-મૂલ્ય નું મૂલ્યાંકન કરીને અમે નીચેના નિષ્કર્ષ પર આવી શકીએ છીએ.
P<0.05 → અત્યંત નોંધપાત્ર ડેટાP =0.05 → નોંધપાત્ર ડેટા
P=0.05-0.1 → નજીવો નોંધપાત્ર ડેટા
P>0.1 → નજીવી માહિતી
પ્રેક્ટિસ વિભાગ
તમારી જાતે પ્રેક્ટિસ કરવા માટે અમે પ્રેક્ટિસ નામની શીટમાં નીચેની જેમ પ્રેક્ટિસ વિભાગ પ્રદાન કર્યો છે. કૃપા કરીને તે જાતે કરો.
નિષ્કર્ષ
આ લેખમાં, અમે P-વેલ્યુ ની ગણતરી કરવાની રીતોને આવરી લેવાનો પ્રયાસ કર્યો એક્સેલમાં લીનિયર રીગ્રેશન. આશા છે કે તમને તે ઉપયોગી લાગશે. જો તમારી પાસે કોઈ સૂચનો અથવા પ્રશ્નો હોય, તો તેને ટિપ્પણી વિભાગમાં શેર કરવા માટે નિઃસંકોચ.
