
Содржина
Ако барате начини да пресметате P-вредност или вредност на веројатност во линеарна регресија во Excel, тогаш сте на вистинското место. P-вредност се користи за одредување на веројатноста за резултатите од хипотетички тестови. Резултатите можеме да ги анализираме врз основа на 2 хипотези; Нулта хипотеза и Алтернативна хипотеза . Користејќи ја P-вредноста можеме да одредиме дали резултатот ја поддржува Нултата хипотеза или Алтернативната хипотеза.
Значи, да започнеме со главната статија.
Преземи работна книга
P value.xlsx
3 начини да се пресмета вредноста P во линеарна регресија во Excel
Овде, имаме некои предвидени продажни вредности и реалните продажни вредности на некои од производите на една компанија. Ќе ги споредиме овие продажни вредности и ќе ја одредиме вредноста на веројатноста и потоа ќе утврдиме дали P ја поддржува нултата хипотеза или алтернативната хипотеза. Нултата хипотеза смета дека нема разлика помеѓу двата типа на продажни вредности и алтернативната хипотеза ќе ги земе предвид разликите помеѓу овие две групи вредности.
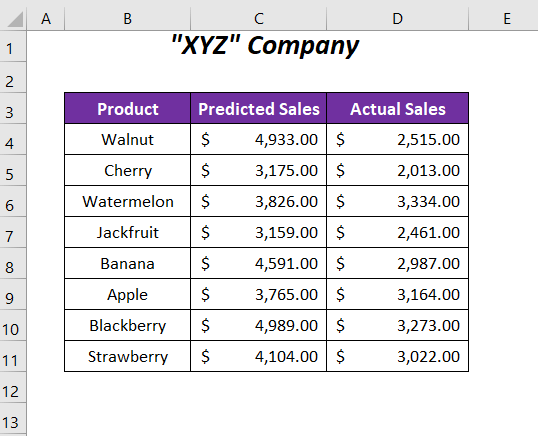
Користевме Верзијата на Microsoft Office 365 овде, можете да користите која било друга верзија според вашата погодност.
Метод-1: Користење на „Алатката за анализа на t-Test“ за пресметување на вредноста P
Тука, ќе ја користиме алатката за анализа која ја содржи алатката за анализа t-Test за да ја одредиме P-вредноста за овие две групи на податоци за продажба.

Чекори :
Ако не сте ја активирале алатката за анализа на податоци потоа прво вклучете ја оваа алатка.
➤ Кликнете на јазичето Датотека .

➤ Изберете Опции .

Потоа, ќе се појави полето за дијалог Excel Options .
➤ Изберете го Додатоци опција на левиот панел.
➤ Изберете ја опцијата Excel Додатоци во полето Управување и потоа притиснете Оди .
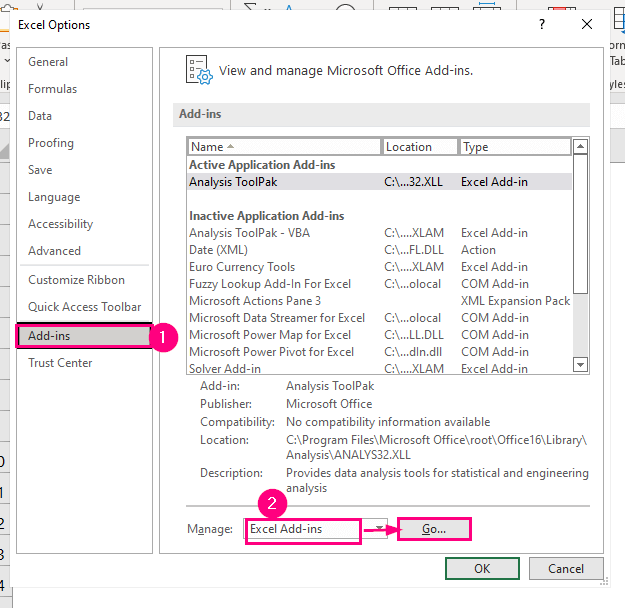
Потоа, ќе се појави полето за дијалог Додатоци .
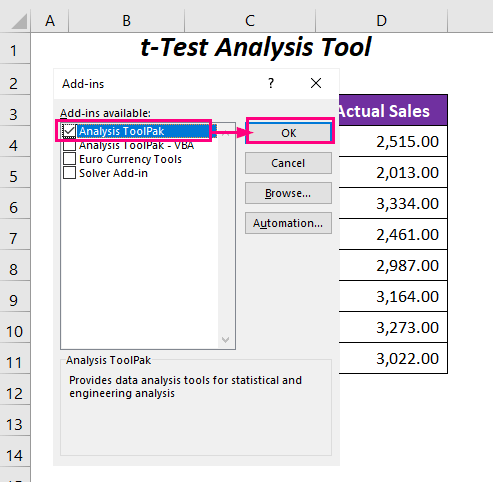
➤ Проверете го Analysis ToolPak опција и притиснете OK .
➤ Сега, одете во Data Tab >> Анализа Групна >> Анализа на податоци Опција.

Потоа, ќе се појави волшебникот Анализа на податоци .
➤ Изберете ја опцијата t-Test: Paired Two Sample for Means од различни опции на Алатки за анализа .
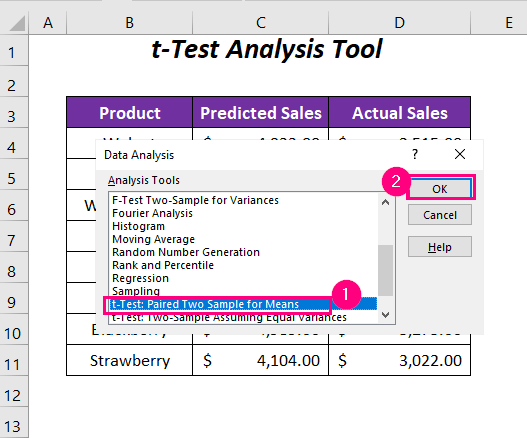
Потоа, ќе се отвори полето за дијалог t-Test: Paired Two Sample for Means .
➤ Како Влез мораме да обезбедиме два опсези на променливи; $C$4:$C$11 за Опсег на променлива 1 и $D$4:$D$11 за Опсег на променлива 2 , како Излезен опсег избравме $E$4 .
➤ Можете да ја промените вредноста за Alpha од 0,05 (автоматски генериран) до 0,01 бидејќи назначената вредност за оваа константа е генерално 0,05 или 0,01 .
➤Конечно, притиснете OK .

Потоа, ќе ја добиете P-вредноста за два случаи; вредноста со една опашка е 0,00059568 а вредноста со две опашки е 0,0011913 . Можеме да видиме дека P-вредноста со една опашка е половина пати од двоопашката P-вредноста . Бидејќи дво-опашката P-вредност го зема предвид и зголемувањето и намалувањето на ознаките додека едноопашката P-вредноста разгледува само еден од овие случаи.
Покрај тоа, можеме да видиме дека за алфа вредноста на 0,05 ги добиваме P вредностите помали од 0,05 што значи дека ја занемарува нултата хипотеза и така што податоците се многу значајни.

Прочитајте повеќе: Како да ги толкувате резултатите од линеарната регресија во Excel (со лесни чекори)
Метод-2: Користење на функцијата T.TEST за пресметување на вредноста P во линеарна регресија во Excel
Во овој дел, ќе ја користиме функцијата T.TEST за да се одредат P вредностите за опашките 1 и 2 .
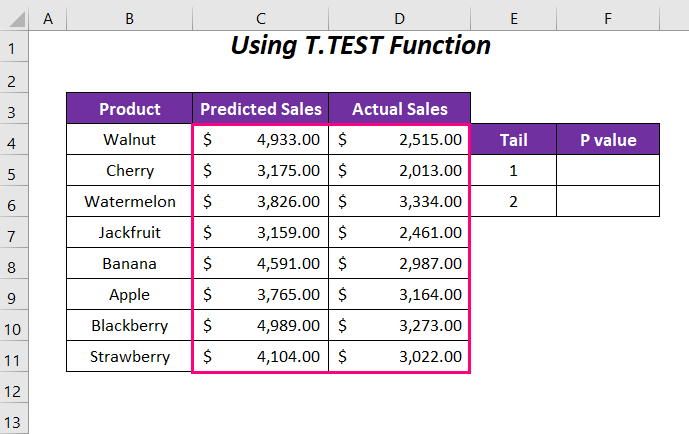
Чекори :
Ќе започнеме со одредување на P-вредноста за опашката 1 или во една насока.
➤ Внесете ја следната формула во ќелијата F5 .
=T.TEST(C4:C11,D4 :D11,1,1)Тука, C4:C11 е опсегот на Предвидени продажби , D4:D11 е опсегот на Вистинска продажба , 1 е опашката вредност и последната 1 е за Спарени тип.
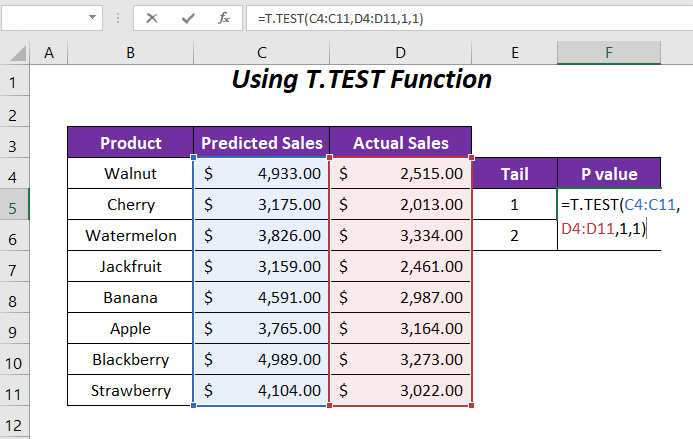
По притискање на ENTER , ја добиваме P-вредноста 0.00059568 за опашка 1 .

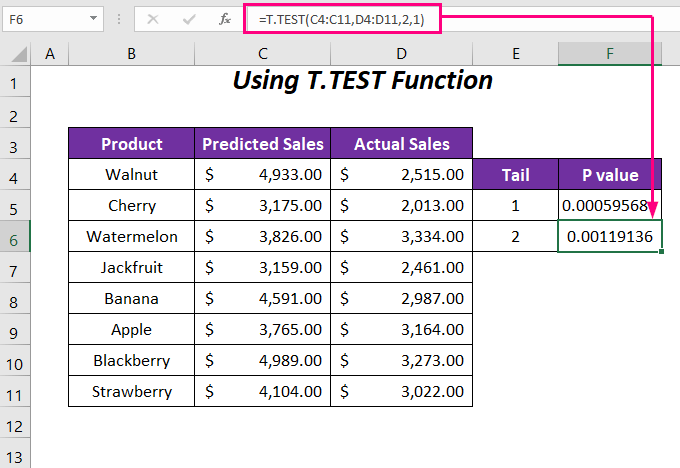
➤ Примени ја следнава формула во ќелијата F6 за да одредиш P-вредноста за опашката 2 или во двете насоки.
=T.TEST(C4:C11,D4:D11,2,1) Тука, C4: C11 е опсегот на Предвидени продажби , D4:D11 е опсегот на Вистинската продажба , 2 е вредноста на опашката и последната 1 е за типот Спарен .
Прочитајте повеќе: Повеќекратна линеарна регресија на множества податоци на Excel (2 методи)
Метод-3: Користење на функциите CORREL, T.DIST.2T да ја пресметаме вредноста P во линеарна регресија
Ќе одредиме P-вредност за корелација овде со користење на CORREL , T.DIST.2T функции.
За да го направите ова, создадовме неколку колони со заглавија Вкупна ставка , Correl. Фактор , t Вредност и P вредност и ја внесовме вредноста за вкупните ставки исто така која е 8 .

Чекори :
➤ Прво, го одредуваме Correl.Factor со внесување на следната формула во ќелијата C14 .
=CORREL(C4:C11,D4:D11) Тука, C4:C11 е опсегот на Предвидени продажби и D4:D11 е опсегот на Вистински продажби .

➤ За да ја одредите вредноста t напишете ја следнава формула во ќелијата D14 .
=(C14*SQRT(B14-2))/SQRT(1-C14*C14) Тука, C14 е факторот на корелација, а B14 е вкупниот број на производи.
- SQRT(B14-2) станува
SQRT(8-2) → SQRT(6 ) го дава квадратниот корен на 6 .
Излез → 2.4494897
- C14*SQRT(B14-2) станува
0,452421561*2,4494897
Излез → 1,10820197
- 1-C14*C14 станува
1-0,452421561*0,452421561
Излез → 0,79531473
- SQRT(1-C14*C14) станува
SQRT(0,79531473) → го враќа квадратниот корен од 0,79531473 .
Излез → 0,891804199
- (C14*SQRT(B14-2))/SQRT(1-C14*C14) станува
(1.10820197)/0.891804199
Излез → 1.242651665
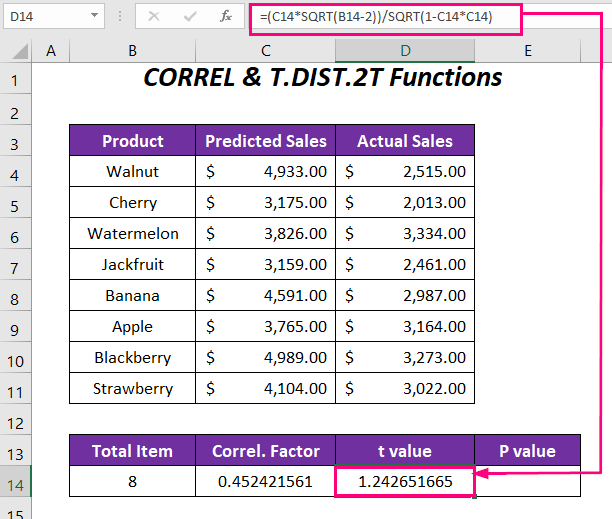
➤ Конечно, со користење на следнава функција ќе ја одредиме P-вредноста за корелација.
=T.DIST.2T(D14,B14-2) Тука, D14 е t вредноста , B14-2 или 8-2 или 6 е степен на слобода и T.DIST.2T ќе ја врати P-вредноста за корелација со дистрибуцијата со две опашки.

Прочитај повеќе: Како да се направи повеќекратна регресивна анализа во Excel (со лесни чекори)
Работи што треба да се запаметат
⦿ Општо земено, ние користиме две вообичаени Алфа вредности; 0,05 и 0,01 .
⦿ Постојат две хипотези, нултата хипотеза и алтернативната хипотеза.нултата хипотеза не смета дека нема разлика помеѓу две групи податоци, а другата ја зема предвид разликата помеѓу две групи податоци.
⦿ Кога P-вредноста е помала од 0,05 ја негира нултата хипотеза и за вредности поголеми од 0,05 ја поддржува нултата хипотеза. Со проценка на P-вредноста можеме да дојдеме до следните заклучоци.
P<0,05 →многу значајни податоциP =0,05 → значајни податоци
P=0,05-0,1 → маргинално значајни податоци
P>0,1 → незначителни податоци
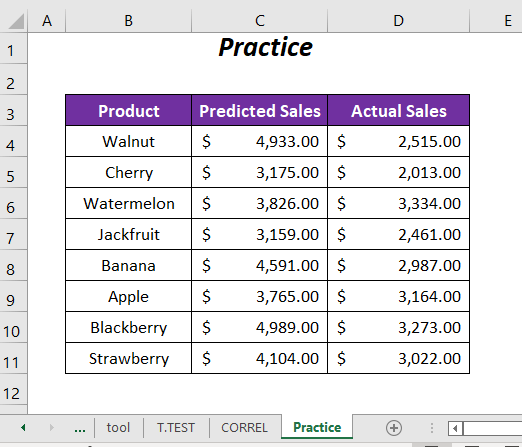
Дел за вежбање
За вежбање сами дадовме дел Вежбање како подолу во листот со име Вежба . Ве молиме направете го тоа сами.
Заклучок
Во оваа статија се обидовме да ги покриеме начините за пресметување P-вредност во линеарна регресија во Excel. Се надеваме дека ќе ви биде корисно. Ако имате какви било предлози или прашања, слободно споделете ги во делот за коментари.
