
Inhoudsopgave
Als u manieren zoekt om P-waarde of waarschijnlijkheidswaarde in lineaire regressie in Excel, dan ben je op de juiste plaats. P-waarde wordt gebruikt om de waarschijnlijkheid van de resultaten van hypothetische tests te bepalen. We kunnen de resultaten analyseren op basis van 2 hypothesen; de Nulhypothese en de Alternatieve hypothese . met behulp van de P-waarde kunnen we bepalen of het resultaat de nulhypothese of de alternatieve hypothese ondersteunt.
Dus, laten we beginnen met het hoofdartikel.
Werkboek downloaden
P-waarde.xlsx3 manieren om de P-waarde te berekenen in lineaire regressie in Excel
Hier hebben we enkele voorspelde verkoopwaarden en werkelijke verkoopwaarden van enkele producten van een onderneming. We zullen deze verkoopwaarden vergelijken en de waarschijnlijkheidswaarde bepalen en dan zullen we bepalen of P De nulhypothese houdt in dat er geen verschil is tussen de twee soorten verkoopwaarden en de alternatieve hypothese gaat uit van verschillen tussen deze twee reeksen waarden.
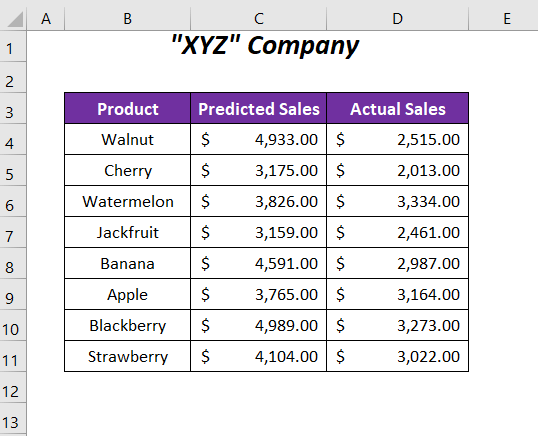
Wij hebben gebruik gemaakt van Microsoft Office 365 versie hier, u kunt elke andere versie gebruiken volgens uw gemak.
Methode-1: Gebruik van het "t-Test Analysis Tool" om de P-waarde te berekenen
Hier zullen wij het analyse-instrumentarium met de t-Test gebruiken om de P-waarde voor deze twee reeksen verkoopgegevens.

Stappen :
Als u het hulpmiddel voor gegevensanalyse niet hebt geactiveerd, schakel dan eerst dit hulpmiddel in.
➤ Klik op de Bestand tab.

Selecteer Opties .

Daarna wordt de Excel-opties dialoogvenster verschijnt.
Selecteer de Toevoegingen optie in het linkerpaneel.
➤ Kies de Excel Toevoegingen optie in de Beheer vak en druk dan op Ga naar .
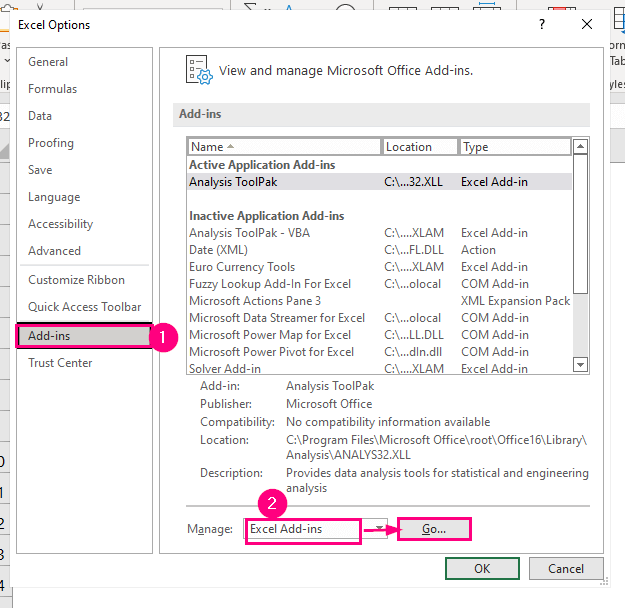
Daarna, de Toevoegingen dialoogvenster verschijnt.
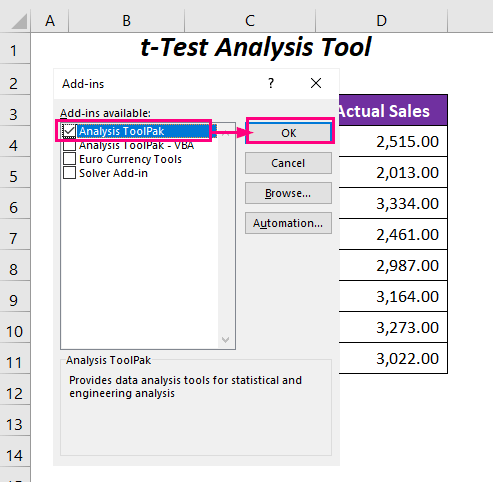
Controleer de Analyse ToolPak optie en druk op OK .
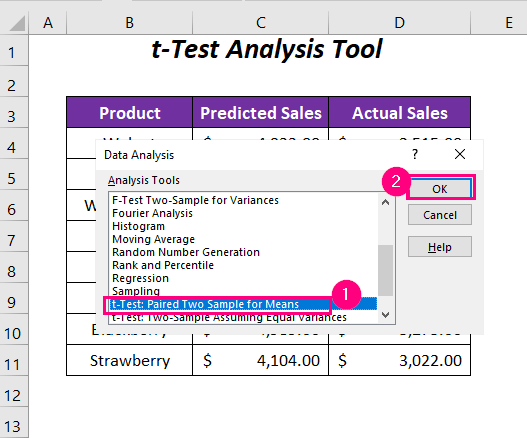
➤ Ga nu naar de Gegevens Tab>> Analyse Groep>> Gegevensanalyse Optie.

Dan, de Gegevensanalyse wizard zal verschijnen.
Selecteer de optie t-Test: Gepaarde twee steekproeven voor de gemiddelden uit verschillende opties van Analyse-instrumenten .
Daarna wordt de t-Test: Gepaarde twee steekproeven voor de gemiddelden dialoogvenster wordt geopend.
Als Ingang moeten we twee variabele bereiken opgeven; $C$4:$C$11 voor Variabele 1 Bereik en $D$4:$D$11 voor Variabele 2 Bereik zoals Uitvoerbereik hebben we geselecteerd $E$4 .
➤ U kunt de waarde voor Alpha van 0.05 (automatisch gegenereerd) naar 0.01 omdat de aangewezen waarde voor deze constante over het algemeen 0.05 of 0.01 .
➤ Druk tenslotte op OK .

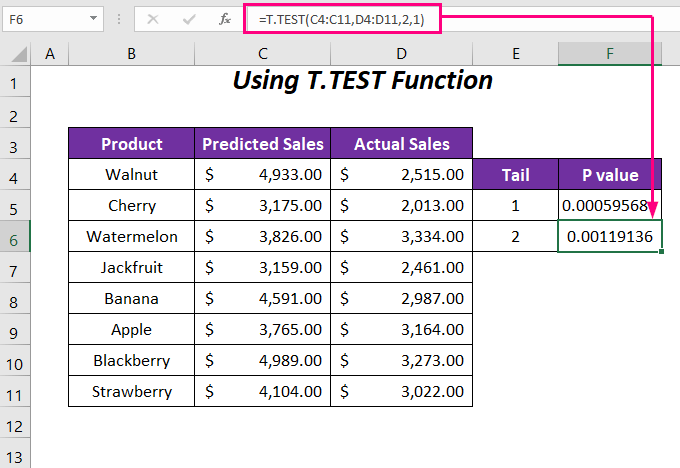
Daarna krijg je de P-waarde voor twee gevallen; de éénstaartwaarde is 0.00059568 en de tweestaartwaarde is 0.0011913 We kunnen de één-staart P-waarde is de helft van de twee-staart P-waarde Omdat de twee-staart P-waarde houdt rekening met zowel de stijging als de daling van de cijfers, terwijl de één-staart P-waarde beschouwt slechts één van deze gevallen.
Bovendien zien we dat voor de alfa-waarde van 0.05 we krijgen de P waarden lager dan 0.05 wat betekent dat de nulhypothese wordt genegeerd en de gegevens dus zeer significant zijn.

Lees meer: Lineaire regressieresultaten interpreteren in Excel (in eenvoudige stappen)
Methode-2: De T.TEST-functie gebruiken om de P-waarde te berekenen bij lineaire regressie in Excel
In dit deel gebruiken we de T.TEST functie om de P-waarden voor staarten 1 en 2 .
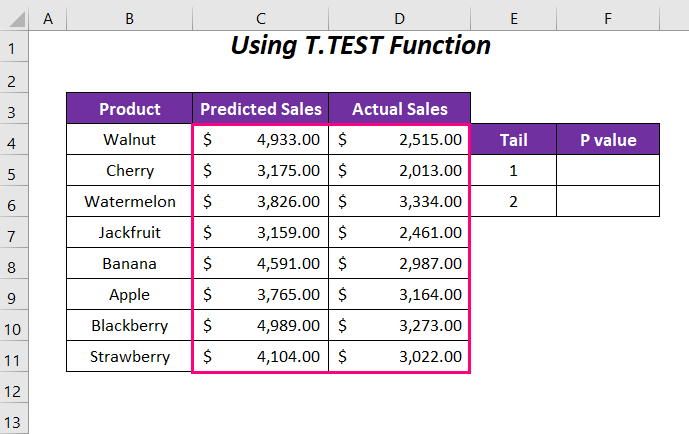
Stappen :
We beginnen met het bepalen van de P-waarde voor staart 1 of in één richting.
Typ de volgende formule in de cel F5 .
=T.TEST(C4:C11,D4:D11,1,1)Hier, C4:C11 is het bereik van Verwachte verkoop , D4:D11 is het bereik van Werkelijke verkoop , 1 is de staartwaarde en de laatste 1 is voor de Gekoppeld type.
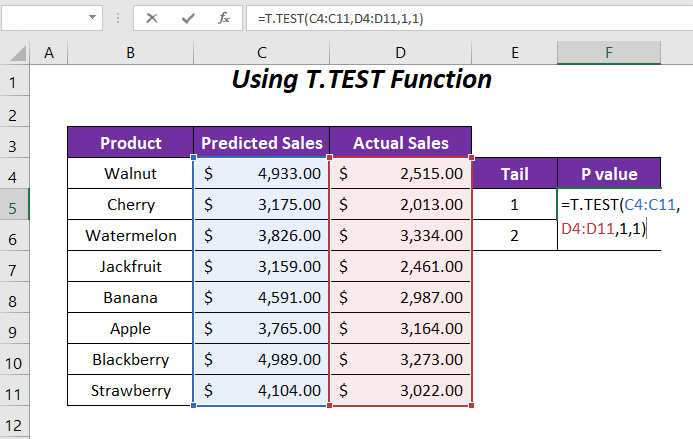
Na het indrukken van ENTER krijgen we de P-waarde 0.00059568 voor staart 1 .

➤ Pas de volgende formule toe in cel F6 om de P-waarde voor staart 2 of in beide richtingen.
=T.TEST(C4:C11,D4:D11,2,1) Hier, C4:C11 is het bereik van Verwachte verkoop , D4:D11 is het bereik van Werkelijke verkoop , 2 is de staartwaarde en de laatste 1 is voor de Gekoppeld type.
Lees meer: Meervoudige lineaire regressie op Excel-gegevensreeksen (2 methoden)
Methode-3: De functies CORREL, T.DIST.2T gebruiken om de P-waarde in lineaire regressie te berekenen
We zullen bepalen P-waarde voor correlatie hier door de CORREL , T.DIST.2T functies.
Daartoe hebben we enkele kolommen met koppen gemaakt Totaal , Correl. factor , t Waarde en P-waarde en we hebben de waarde voor het totaal aantal items ook ingevoerd en dat is 8 .

Stappen :
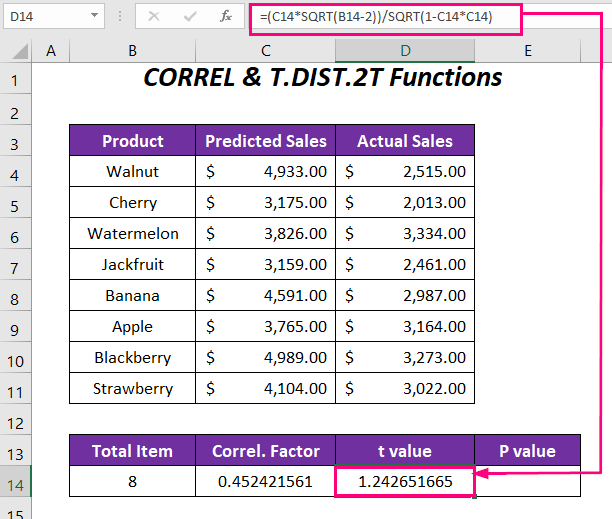
➤ Eerst bepalen we de Correl.factor door de volgende formule in te voeren in cel C14 .
=CORREL(C4:C11,D4:D11) Hier, C4:C11 is het bereik van Verwachte verkoop en D4:D11 is het bereik van Werkelijke verkoop .

➤ Om de t-waarde typ de volgende formule in cel D14 .
=(C14*SQRT(B14-2))/SQRT(1-C14*C14) Hier, C14 de correlatiefactor is, en B14 is het totale aantal producten.
- SQRT(B14-2) wordt
SQRT(8-2) → SQRT(6) geeft de vierkantswortel van 6 .
Uitgang → 2.4494897
- C14*SQRT(B14-2) wordt
0.452421561*2.4494897
Uitgang → 1.10820197
- 1-C14*C14 wordt
1-0.452421561*0.452421561
Uitgang → 0.79531473
- SQRT(1-C14*C14) wordt
SQRT(0,79531473) → geeft de vierkantswortel van 0.79531473 .
Uitgang → 0.891804199
- (C14*SQRT(B14-2))/SQRT(1-C14*C14) wordt
(1.10820197)/0.891804199
Uitgang → 1.242651665
➤ Ten slotte bepalen we met behulp van de volgende functie de P-waarde voor correlatie.
=T.DIST.2T(D14,B14-2) Hier, D14 is de t-waarde , B14-2 of 8-2 of 6 is de vrijheidsgraad en T.DIST.2T zal de P-waarde voor correlatie met de tweezijdige verdeling.

Lees meer: Meervoudige regressieanalyse in Excel (met eenvoudige stappen)
Dingen om te onthouden
⦿ Over het algemeen gebruiken we twee gemeenschappelijke Alpha waarden; 0.05 en 0.01 .
⦿ Er zijn twee hypothesen, de nulhypothese en de alternatieve hypothese; de nulhypothese gaat uit van geen verschil tussen twee reeksen gegevens en de andere houdt rekening met het verschil tussen twee reeksen gegevens.
⦿ Wanneer de P-waarde is minder dan 0.05 ontkent het de nulhypothese en voor waarden groter dan 0.05 het ondersteunt de nulhypothese. Door het beoordelen van de P-waarde kunnen we de volgende conclusies trekken.
P<0.05 → zeer significante gegevensP=0.05 → belangrijke gegevens
P=0.05-0.1 → marginaal significante gegevens
P>0.1 → onbelangrijke gegevens
Praktijk Sectie
Om zelf te oefenen hebben we een Praktijk sectie zoals hieronder in een blad met de naam Praktijk Doe het alsjeblieft zelf.
Conclusie
In dit artikel hebben we geprobeerd de manieren te behandelen om te berekenen P-waarde in lineaire regressie in Excel. Hopelijk vindt u het nuttig. Als u suggesties of vragen hebt, voel u vrij om ze te delen in de commentaarsectie.
