
Зміст
Якщо ви шукаєте способи розрахунку P-значення або значення ймовірності в лінійна регресія в Excel, то ви потрапили в потрібне місце. P-значення використовується для визначення ймовірності результатів гіпотетичних випробувань. Ми можемо проаналізувати результати, виходячи з 2 гіпотез, а саме Нульова гіпотеза та Альтернативна гіпотеза Використовуючи P-значення ми можемо визначити, чи підтверджує отриманий результат Нульову гіпотезу або Альтернативну гіпотезу.
Отже, почнемо з головної статті.
Завантажити Робочий зошит
Значення P.xlsx3 Способи розрахунку значення P в лінійній регресії в Excel
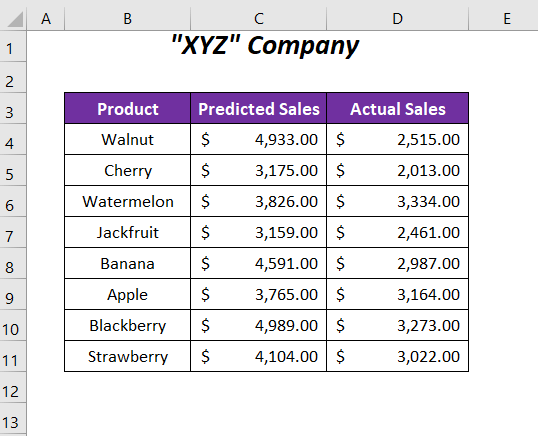
Тут у нас є деякі прогнозовані значення продажів і фактичні значення продажів деяких продуктів компанії. Ми порівняємо ці значення продажів і визначимо значення ймовірності, а потім визначимо, чи є P Нульова гіпотеза передбачає відсутність різниці між двома типами значень обсягів продажу, а альтернативна гіпотеза розглядає відмінності між цими двома наборами значень.
Ми використовували Microsoft Office 365 тут, ви можете використовувати будь-які інші версії відповідно до вашої зручності.
Метод-1: Використання "Інструменту аналізу t-критерію" для розрахунку значення P
Тут ми скористаємося пакетом аналітичних інструментів, що містить інструмент аналізу t-критерій для визначення P-значення для цих двох наборів даних про продажі.

Кроки :
Якщо ви не активували інструмент аналізу даних, то спочатку увімкніть цей пакет інструментів.
Натисніть на кнопку Файл рахунок.

Виберіть Опції .

Після цього, в рамках візиту в Україну, в рамках візиту Параметри Excel з'явиться діалогове вікно.
Виберіть пункт Надбудови на лівій панелі.
➤ Виберіть пункт Excel Надбудови опція в Керувати і натисніть кнопку Іди. .
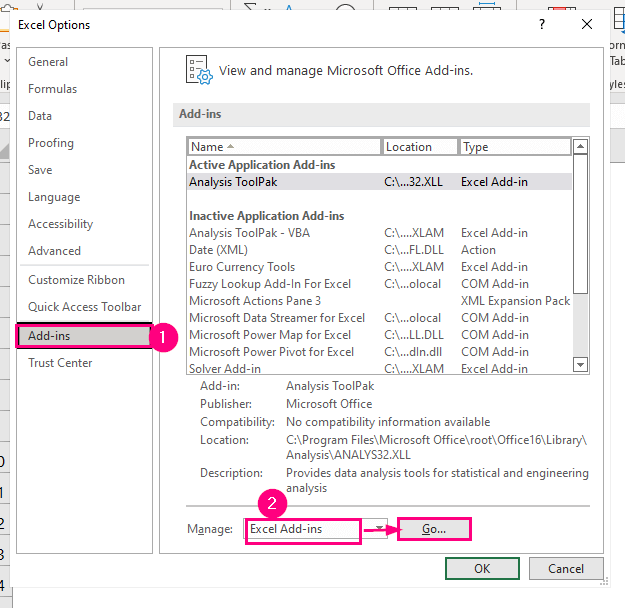
Після цього відбулася зустріч з представниками Надбудови з'явиться діалогове вікно.
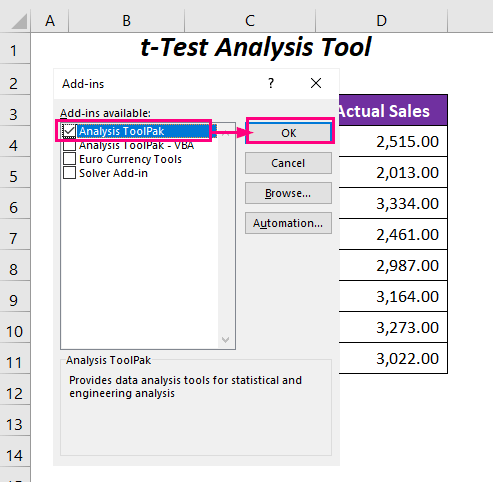
➤ Перевірте Analysis ToolPak і натисніть ГАРАЗД. .
➤ Тепер перейдіть до розділу Дані Вкладка>>; Аналіз Група "А"; Аналіз даних Варіант.

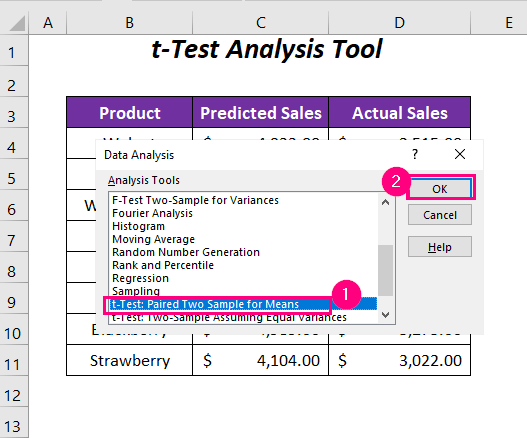
Після цього, на засіданні Аналіз даних з'явиться чарівник.
➤ Виберіть опцію t-тест: парні дві вибірки для середніх значень з різних варіантів Інструменти аналізу .
Після цього, в рамках візиту в Україну t-тест: парні дві вибірки для середніх значень відкриється діалогове вікно.
➤ Як Вхідні дані ми повинні забезпечити два діапазони змінних; C$4:C$11 для Змінна 1 Діапазон і $D$4:$D$11 для Змінна 2 Діапазон як Вихідний діапазон ми обрали $E$4 .
Ви можете змінити значення для Альфа від 0.05 (автоматично згенеровано) до 0.01 тому що призначене значення для цієї константи, як правило, дорівнює 0.05 або 0.01 .
Нарешті, натисніть ГАРАЗД. .

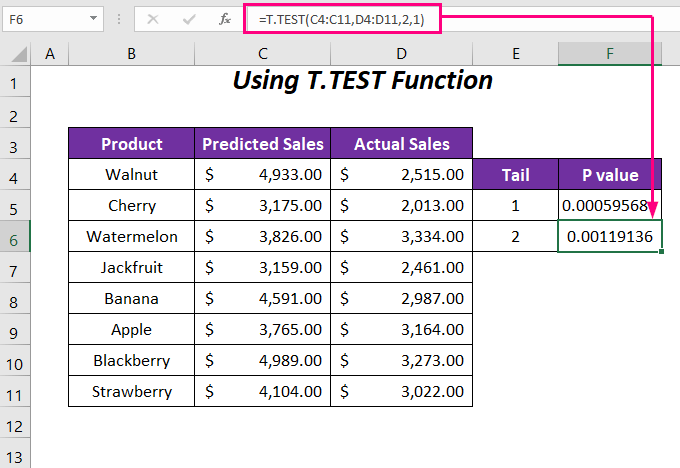
Після цього ви отримаєте P-значення для двох випадків; однохвостове значення дорівнює 0.00059568 а двочленне значення дорівнює 0.0011913 Ми бачимо однохвостого. P-значення вдвічі менший за двохвилинний P-значення Тому що двохвостий P-значення враховує як підвищення, так і зниження оцінок, тоді як однохвоста P-значення розглядає лише одну з цих справ.
Більше того, ми бачимо, що для значення Альфа 0.05 ми отримуємо P значення менше, ніж 0.05 що означає нехтування нульовою гіпотезою, а отже дані є високо значимими.

Читати далі: Як інтерпретувати результати лінійної регресії в Excel (з простими кроками)
Спосіб-2: Використання функції T.TEST для розрахунку значення P в лінійній регресії в Excel
У цьому розділі ми будемо використовувати Функція T.TEST для визначення Значення P для хвостів 1 і 2 .
Кроки :
Розпочнемо з визначення P-значення для хвоста 1 або в одному напрямку.
➤ Введіть наступну формулу в комірку F5 .
=T.TEST(C4:C11,D4:D11,1,1)Ось, C4:C11 це діапазон Прогнозовані продажі , D4:D11 це діапазон Фактичні продажі , 1 є хвостовим значенням, а останнє 1 це для Парні тип.
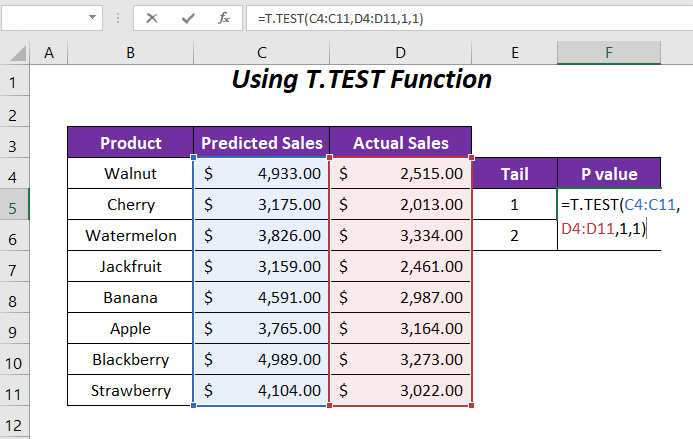
Після натискання ENTER ми отримуємо P-значення 0.00059568 для хвоста 1 .

Застосуйте наступну формулу в комірці F6 для визначення P-значення для хвоста 2 або в обох напрямках.
=T.TEST(C4:C11,D4:D11,2,1) Ось, C4:C11 це діапазон Прогнозовані продажі , D4:D11 це діапазон Фактичні продажі , 2 є хвостовим значенням, а останнє 1 це для Парні тип.
Читати далі: Множинна лінійна регресія на масивах даних Excel (2 методики)
Спосіб 3: Використання функцій CORREL, T.DIST.2T для розрахунку значення P в лінійній регресії
Ми визначимо P-значення для кореляції тут, використовуючи КОРЕЛЯЦІЯ , T.DIST.2T функції.
Для цього ми створили кілька колонок із заголовками Усього Позиція , Коефіцієнт кореляції , т Значення і Значення P і ми також ввели значення для загальної кількості пунктів, яке становить 8 .

Кроки :
➤ По-перше, ми визначаємо Корел.фактор ввівши в комірку наступну формулу C14 .
=CORREL(C4:C11,D4:D11) Ось, C4:C11 це діапазон Прогнозовані продажі і D4:D11 це діапазон Фактичні продажі .

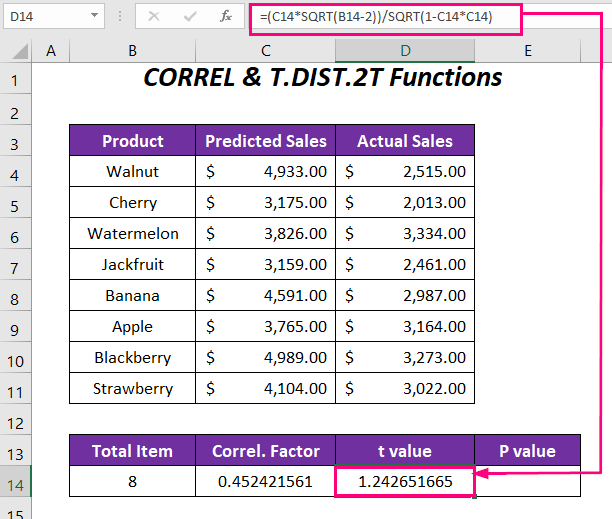
➤ Для визначення значення t введіть в комірку наступну формулу D14 .
=(C14*SQRT(B14-2))/SQRT(1-C14*C14) Ось, C14 коефіцієнт кореляції, а B14 загальна кількість продукції.
- SQRT(B14-2) стає
SQRT(8-2) → SQRT(6) дає квадратний корінь з числа 6 .
Вихідні дані → 2.4494897
- C14*SQRT(B14-2) стає
0.452421561*2.4494897
Вихідні дані → 1.10820197
- 1-C14*C14 стає
1-0.452421561*0.452421561
Вихідні дані → 0.79531473
- SQRT(1-C14*C14) стає
SQRT(0.79531473) → повертає квадратний корінь з числа 0.79531473 .
Вихідні дані → 0.891804199
- (C14*SQRT(B14-2))/SQRT(1-C14*C14) стає
(1.10820197)/0.891804199
Вихідні дані → 1.242651665
Нарешті, за допомогою наступної функції ми визначимо P-значення для кореляції.
=T.DIST.2T(D14,B14-2) Ось, D14 це значення t , B14-2 або 8-2 або 6 це ступінь свободи і T.DIST.2T поверне P-значення для кореляції з двохвостим розподілом.

Читати далі: Як зробити множинний регресійний аналіз в Excel (з простими кроками)
Важливі моменти для запам'ятовування
⦿ Як правило, ми використовуємо два загальних Альфа цінності; 0.05 і 0.01 .
⦿ Існує дві гіпотези, нульова гіпотеза та альтернативна гіпотеза, нульова гіпотеза не враховує різницю між двома наборами даних, а інша враховує різницю між двома наборами даних.
⦿ У разі, коли P-значення менше, ніж 0.05 заперечує нульову гіпотезу і для значень, більших за 0.05 Це підтверджує нульову гіпотезу. Оцінюючи P-значення можна зробити наступні висновки.
P<0.05 → особливо важливі даніP=0.05 → важливі дані
P=0.05-0.1 → малозначущі дані
P>0.1 → незначні дані
Практична секція
Для самостійного проходження практики ми надали Практика розділ, як показано нижче, на аркуші з назвою Практика Будь ласка, зробіть це самі.
Висновок
У цій статті ми спробували висвітлити способи розрахунку P-значення в лінійна регресія в Excel. Сподіваємось, вона буде корисною для Вас, а якщо у Вас є пропозиції чи запитання, будь ласка, діліться ними у коментарях.
