
Innehållsförteckning
Om du letar efter sätt att beräkna P-värde eller sannolikhetsvärde i linjär regression i Excel, då är du på rätt plats. P-värde används för att bestämma sannolikheten för resultaten av hypotetiska tester. Vi kan analysera resultaten utifrån två hypoteser: hypotesen Nollhypotes och Alternativ hypotes . Användning av P-värde kan vi avgöra om resultatet stöder nollhypotesen eller alternativhypotesen.
Låt oss börja med huvudartikeln.
Ladda ner arbetsboken
P-värde.xlsx3 sätt att beräkna P-värdet i linjär regression i Excel
Här har vi några prognostiserade försäljningsvärden och faktiska försäljningsvärden för några av företagets produkter. Vi kommer att jämföra dessa försäljningsvärden och bestämma sannolikhetsvärdet och sedan bestämma om P Nollhypotesen innebär att det inte finns någon skillnad mellan de två typerna av försäljningsvärden, medan den alternativa hypotesen tar hänsyn till skillnaderna mellan dessa två typer av värden.
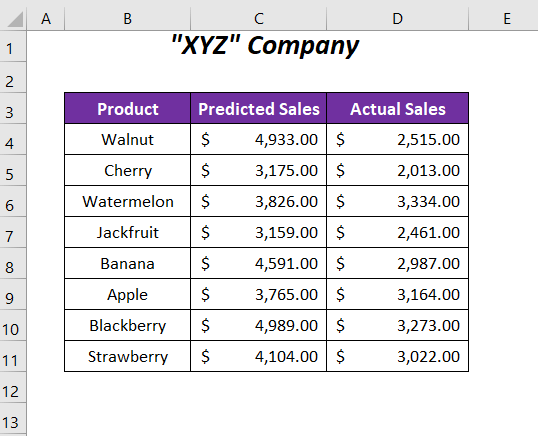
Vi har använt oss av Microsoft Office 365 versionen här, men du kan använda andra versioner när det passar dig.
Metod-1: Användning av "t-Test Analysis Tool" för att beräkna P-värdet
Här kommer vi att använda analysverktygspaketet som innehåller analysverktyget t-Test för att bestämma P-värde för dessa två uppsättningar försäljningsuppgifter.

Steg :
Om du inte har aktiverat dataanalysverktyget ska du först aktivera detta verktygspaket.
➤ Klicka på Fil fliken.

➤ Välj Alternativ .

Efter detta kan Excel-alternativ kommer att visas.
➤ Välj den Tilläggsfunktioner i den vänstra panelen.
➤ Välj den Excel Tilläggsfunktioner i alternativet i Hantera och tryck sedan på Gå till .
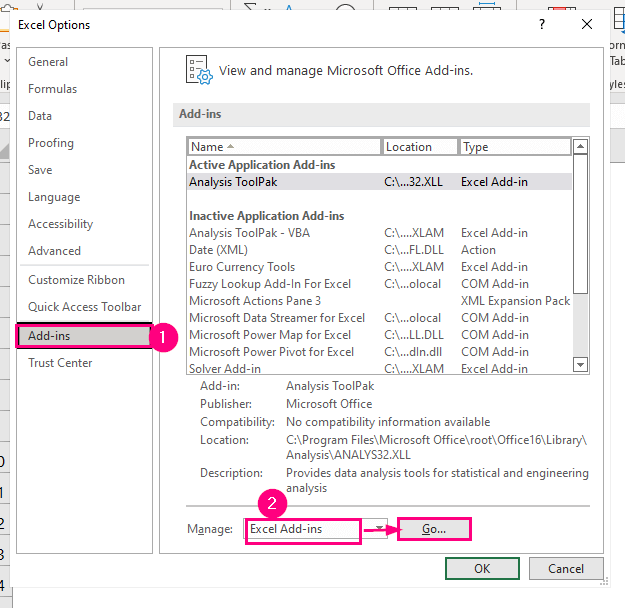
Efteråt kommer Tilläggsfunktioner öppnas.
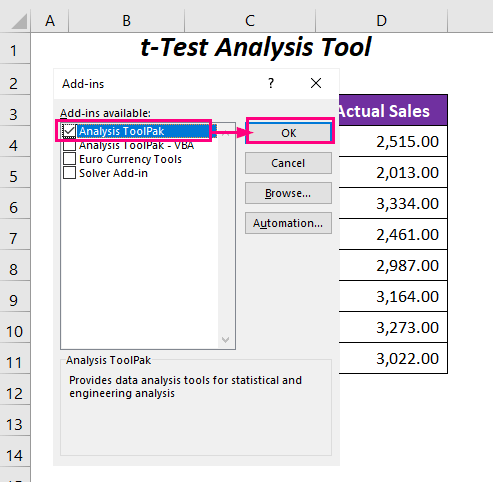
➤ Kontrollera Verktygspaket för analys och tryck på OK .
➤ Gå nu till Uppgifter Fliken>> Analys Grupp>> Analys av data Alternativ.

Därefter är det Analys av data kommer att visas.
➤ Välj alternativet t-Test: parade två stickprov för medelvärden från olika alternativ av Analysverktyg .
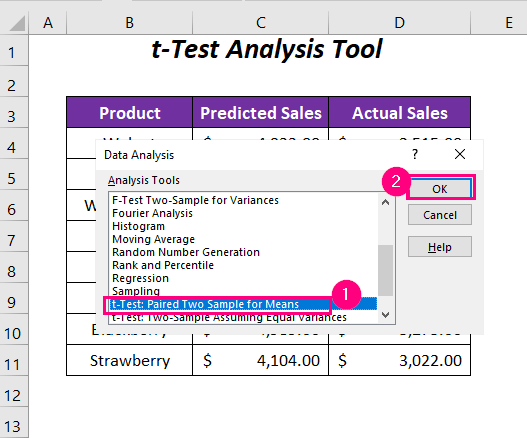
Efter detta kan t-Test: parade två stickprov för medelvärden öppnas.
➤ Som Ingång måste vi ange två variabla intervall; $C$4:$C$11 för Variabel 1 Område och $D$4:$D$11 för Variabel 2 Område , eftersom Utgångsområde Vi har valt ut följande $E$4 .
➤ Du kan ändra värdet för Alpha från 0.05 (som genereras automatiskt) till 0.01 eftersom det angivna värdet för denna konstant i allmänhet är 0.05 eller . 0.01 .
➤ Tryck slutligen på OK .

Efter det får du P-värde för två fall; värdet med en svans är 0.00059568 och värdet med två svansar är 0.0011913 Vi kan se att det finns en en-strängad P-värde är hälften så stor som den dubbla halva P-värde . Eftersom den tvåtaggade P-värde tar hänsyn till både ökningen och minskningen av markeringarna, medan den en-avslutande P-värde endast ett av dessa fall.
Dessutom kan vi se att för Alfa-värdet för 0.05 vi får den P värden som är mindre än 0.05 vilket innebär att den negligerar nollhypotesen och att uppgifterna därför är högt signifikanta.

Läs mer: Hur man tolkar resultat av linjär regression i Excel (med enkla steg)
Metod-2: Använd T.TEST-funktionen för att beräkna P-värdet i linjär regression i Excel
I det här avsnittet kommer vi att använda T.TEST-funktion för att fastställa P-värden för svansar 1 och 2 .
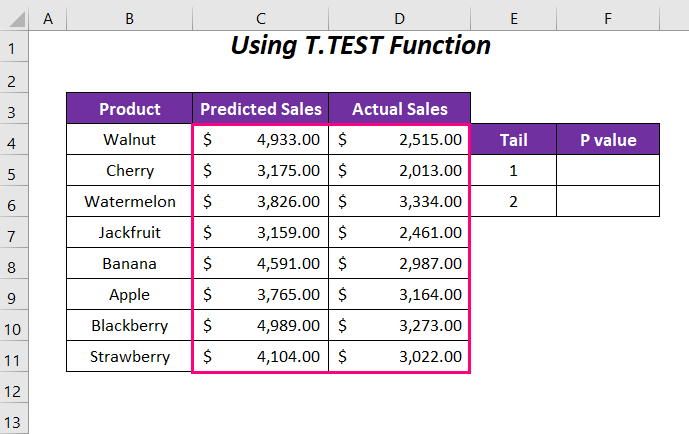
Steg :
Vi börjar med att fastställa P-värde för svans 1 eller i en riktning.
➤ Skriv följande formel i cellen F5 .
=T.TEST(C4:C11,D4:D11,1,1)Här, C4:C11 är intervallet för Prognostiserad försäljning , D4:D11 är intervallet för Faktisk försäljning , 1 är svansvärdet och det sista 1 är för Parat typ.
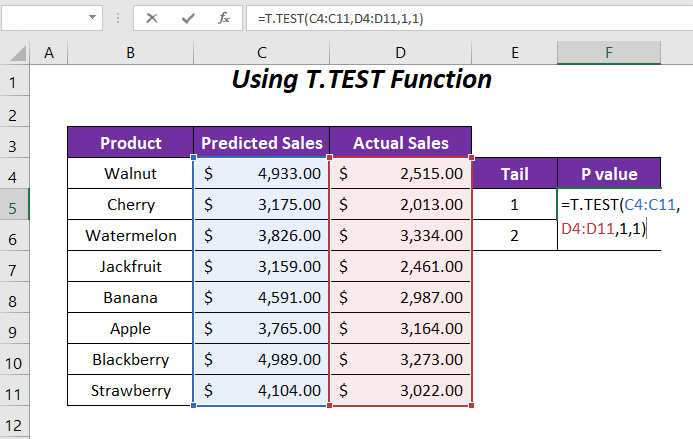
Efter att ha tryckt på ENTER , vi får den P-värde 0.00059568 för svans 1 .

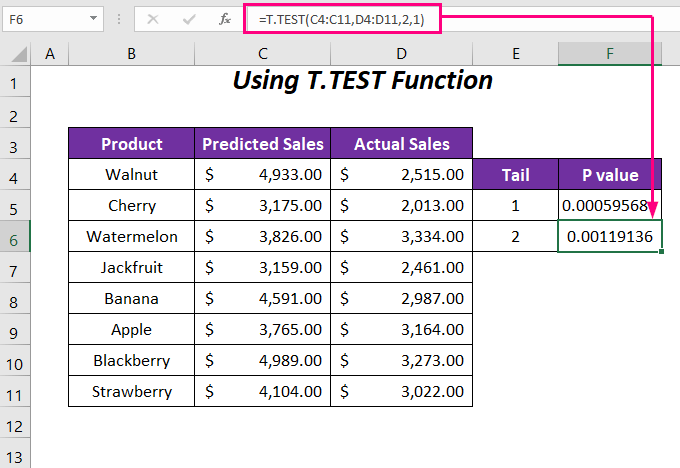
➤ Tillämpa följande formel i cellen F6 för att fastställa P-värde för svans 2 eller i båda riktningarna.
=T.TEST(C4:C11,D4:D11,2,1) Här, C4:C11 är intervallet för Prognostiserad försäljning , D4:D11 är intervallet för Faktisk försäljning , 2 är svansvärdet och det sista 1 är för Parat typ.
Läs mer: Multipel linjär regression på Excel-dataset (2 metoder)
Metod-3: Använda CORREL, T.DIST.2T-funktioner för att beräkna P-värdet vid linjär regression
Vi kommer att fastställa P-värde för korrelation här genom att använda CORREL , T.DIST.2T funktioner.
För att göra detta skapade vi några kolumner med rubriker Totalt , Korrelationsfaktor , t Värde , och P-värde och vi har också angett värdet för totala antalet artiklar, vilket är 8 .

Steg :
➤ För det första bestämmer vi den Korrel.faktor genom att skriva in följande formel i cell C14 .
=CORREL(C4:C11,D4:D11) Här, C4:C11 är intervallet för Prognostiserad försäljning , och D4:D11 är intervallet för Faktisk försäljning .

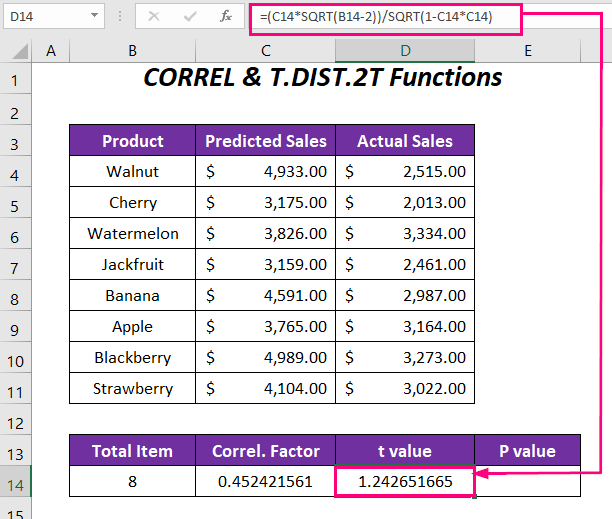
➤ För att fastställa t-värde Skriv följande formel i cell D14 .
=(C14*SQRT(B14-2))/SQRT(1-C14*C14) Här, C14 är korrelationsfaktorn, och B14 är det totala antalet produkter.
- SQRT(B14-2) blir
SQRT(8-2) → SQRT(6) ger kvadratroten av 6 .
Utgång → 2.4494897
- C14*SQRT(B14-2) blir
0.452421561*2.4494897
Utgång → 1.10820197
- 1-C14*C14 blir
1-0.452421561*0.452421561
Utgång → 0.79531473
- SQRT(1-C14*C14) blir
SQRT(0,79531473) → återger kvadratroten av 0.79531473 .
Utgång → 0.891804199
- (C14*SQRT(B14-2))/SQRT(1-C14*C14) blir
(1.10820197)/0.891804199
Utgång → 1.242651665
➤ Slutligen kan vi med hjälp av följande funktion bestämma P-värde för korrelation.
=T.DIST.2T(D14,B14-2) Här, D14 är den t-värde , B14-2 eller . 8-2 eller . 6 är frihetsgraden och T.DIST.2T kommer att återge den P-värde för korrelation med den tvåsidiga fördelningen.

Läs mer: Hur man gör multipel regressionsanalys i Excel (med enkla steg)
Saker att komma ihåg
⦿ I allmänhet använder vi två vanliga Alpha värden; 0.05 och 0.01 .
⦿ Det finns två hypoteser, nollhypotesen och alternativhypotesen, nollhypotesen anser att det inte finns någon skillnad mellan två uppsättningar data och den andra hypotesen tar hänsyn till skillnaden mellan två uppsättningar data.
⦿ När den P-värde är mindre än 0.05 förnekar den nollhypotesen och för värden som är större än 0.05 den stöder nollhypotesen. Genom att bedöma den P-värde kan vi dra följande slutsatser.
P<0,05 → mycket betydelsefulla uppgifterP=0.05 → viktiga uppgifter
P=0.05-0.1 → marginellt signifikanta uppgifter
P>0,1 → obetydliga uppgifter
Övningssektionen
För att du ska kunna öva på egen hand har vi tillhandahållit en Praktik som nedan i ett ark som heter Praktik . Gör det själv.
Slutsats
I den här artikeln har vi försökt att täcka in hur du kan beräkna P-värde på linjär regression i Excel. Om du har några förslag eller frågor får du gärna dela med dig av dem i kommentarsfältet.
